Word2Vec
提出 CBOW、Skip-gram 两种 word embedding 训练模型,是词嵌入的经典模型
什么是 Word2Vec ?
![]()
- 一个学习词嵌入的模型,提出了 CBOW 和 Skip-gram 两种模型架构,CBOW 受到了 NNLM、RNNLM 和 C&W 的启发,Skip-gram 是非常好的一个创新点
- 提出了一个令人印象深刻的评估方法:v (国王)-v (男) + v (女)=v (王后)
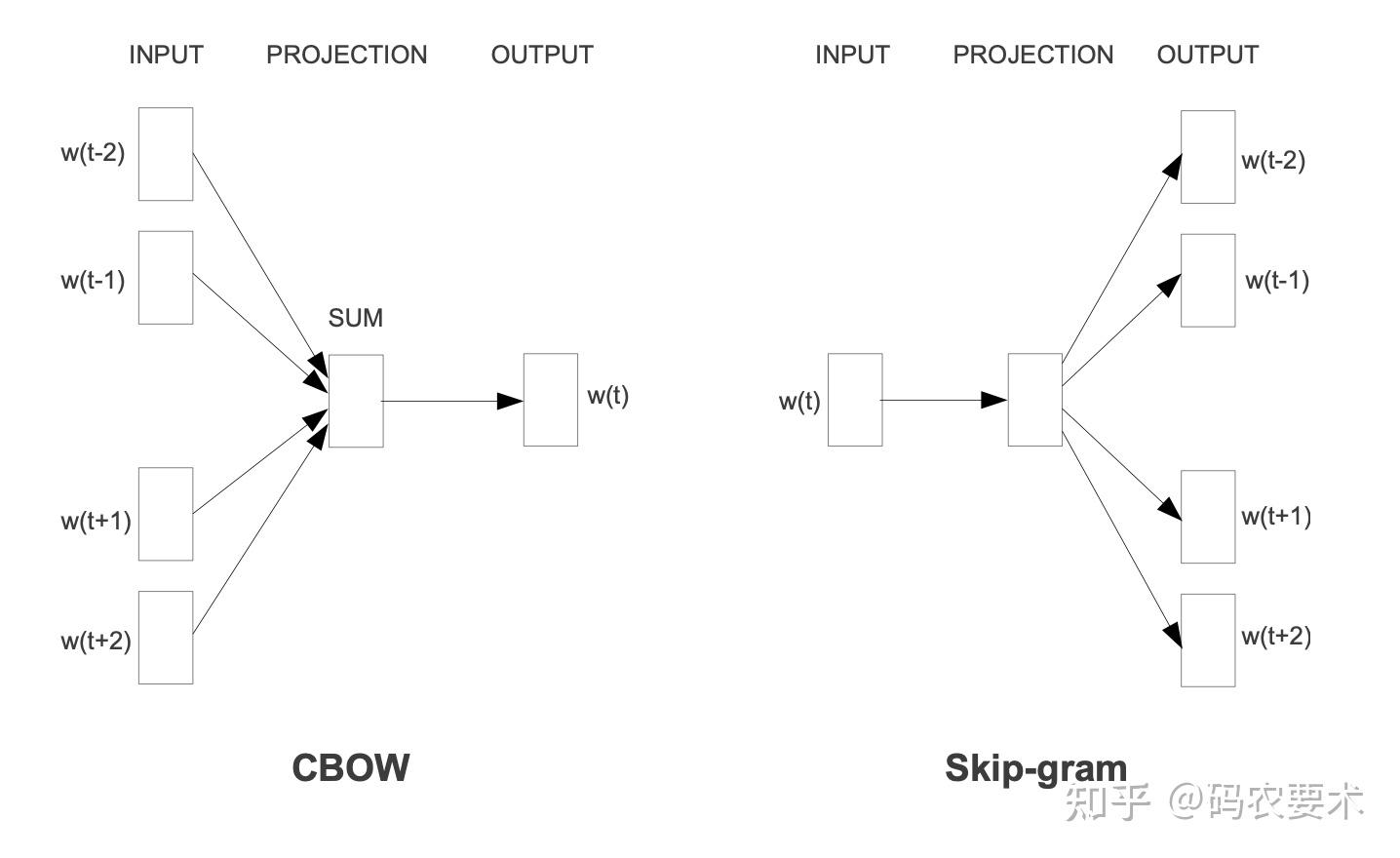
Word2Vec 的连续词袋 (continuous bag of words,CBOW) 模型结构?
![]()
- 有点类似 NNLM,但是非线性的隐层被删除,同时投影层被所有词共享 (取消了投影矩阵);所有的词都被投影到相同的位置 (多个向量取平均),我们称这个框架为词袋模型,因为词的顺序对投影没有任何的影响。而且,我们不仅使用了上文的词,还使用了下文的词
- CBOW 的目的是定上下文,来预测当前值,图示是给定前后的 M/2 个词,预测中心位置的词。假设输入是 M 个大小的词袋,通过投影层后得到 MxV 的特征矩阵,取平均后得到 1xV 的特征,经过一个 VxN 大小的权重矩阵后,输出 1xN 的隐变量表示,再经过权重矩阵 NxV 后,输出 1 xV 的输出,最后作 softmax 分类即可
Word2Vec 的跳字模型 (Skip-gram) 模型结构?
![]()
- 跟 CBOW 类似,不同之处在于 CBOW 是通过上下文来预测当前词,该框架则是使用当前词作为输入,经过投影和 log 线性分类器,来预测 当前词的上下文
- 假设需要预测上下文的距离是 t,那么输入当前词,需要预测 t+t 个词,直接在模型后面输出 t+t 个 softmax 即可
- 论文发现增大要预测上下文的范围可以提升词向量的效果,但是计算复杂度会变大。由于距离近的词比距离远的词往往更相关,我们通过对远距离的词降采样来减少权重
CBOW 与 Skip-gram 的区别?
- CBOW 和 Skip-gram 的不同架构,有点像是上辅导班。CBOW 是大班辅导,而 Skip-gram 则是一对一辅导
- 同样的老师 (上下文),CBOW 会分配更多的精力给提问次数更多的同学 (高频词), 不太主动的同学 (低频词) 就比较吃亏,没学到太多东西
- Skip-gram 因为是一对一辅导,没有其他学生和我竞争老师的资源, 不太主动的同学 (低频词) 也能学到自己想学的知识。缺点则是一对一辅导耗费的师资资源更大一些,训练更慢
参考: