本文介绍连续型随机分布,表示一个区间内的事件的概率,需要记住的只有连续型均匀分布、正太分布
什么是连续性均匀分布?
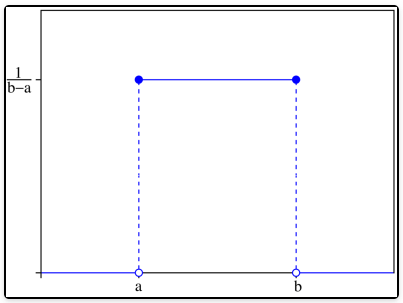
![]()
一个均匀分布在区间 [a, b] 上的连续型随机变量 X
f(n)={b−a1,0,for a <= x < b elsewhere
期望:E[X]=2a+b 方差:V[X]=12(b−a)2
均匀分布具有下属意义的等可能性。若 X ∼ U [a, b], 则 X 落在 [a, b] 内任一子区间 [c, d] 上的概率 P(c≥x≤d)=F(d)−F(c)=∫cdb−a1dx=b−ad−c ,表示概率只与区间 [c, d] 的长度有关,而与他的位置无关
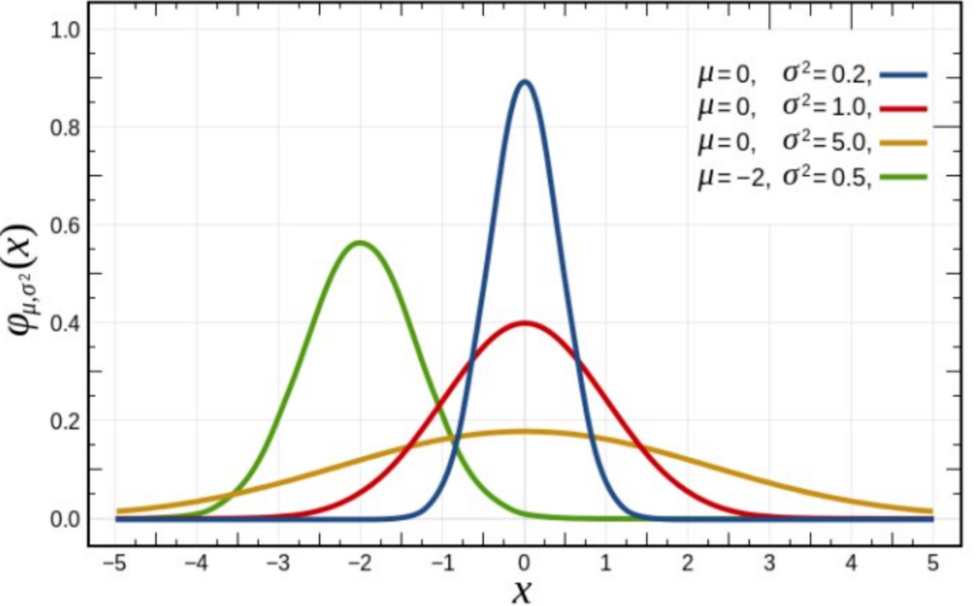
什么是高斯正态分布 (normal)?
什么是指数分布?
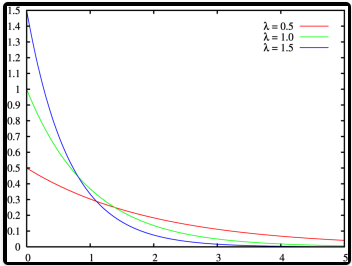
![]()
指数分布是一种连续概率分布。指数分布可以用来表示独立随机事件发生的时间间隔,比如旅客进入机场的时间间隔、打进客服中心电话的时间间隔、中文维基百科新条目出现的时间间隔等等
f(x;λ)={λe−λx,0,x >= 0x<0
其中 λ>0 是分布的一个参数,常被称为率参数。即每单位时间发生该事件的次数。指数分布的区间是 [0,∞)。如果一个随机变量 X 呈指数分布,则可以写作:X ~ Exponential(λ)
期望:E(X)=λ1 方差: V(X)=λ21
指数函数的一个重要特征是无记忆性,这表示如果一个随机变量呈指数分布,当 s,t>0 时有 P (T>t+s|T>t)=P (T>s)。即,如果 T 是某一元件的寿命,已知元件使用了 t 小时,它总共使用至少 s+t 小时的条件概率,与从开始使用时算起它使用至少 s 小时的概率相等
什么是伽马分布?
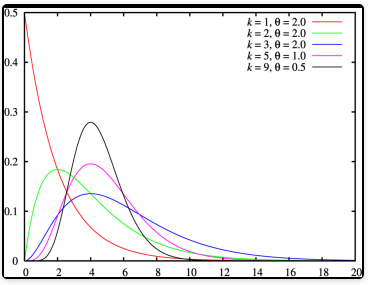
![]()
- 伽玛分布是统计学的一种连续概率函数。伽玛分布中的参数 α,称为形状参数,β 称为尺度参数,令X∼Γ(α,β) ; 且令λ=β1 : 即X∼Γ(α,λ1)
- 假设随机变量 X 为 等到第 α 件事发生所需之等候时间,分布函数为 f(x)=Γxα−1λαe(−λx)(a),x>0
- 伽马(gamma)函数 Γ(x)={(n−1)!∫0∞ettn−1dtn 为正整数实步为正的虚数 n
- 期望:μ=λα 方差:V(X)=λ2α
什么是韦布尔分布?
- 威布尔分布(Weibull distribution)是可靠性分析和寿命检验的理论基础
1
2
3
| #1.预计将在老化期间失效的项目所占的百分比是多少?例如,预计将在8小时老化期间失效的保险丝占多大百分比?
#2.预计在有效寿命阶段有多少次保修索赔?例如,在该轮胎的 50,000 英里有效寿命期间预计有多少次保修索赔?
#3.预计何时会出现快速磨损?例如,应将维护定期安排在何时以防止发动机进入磨损阶段?
|
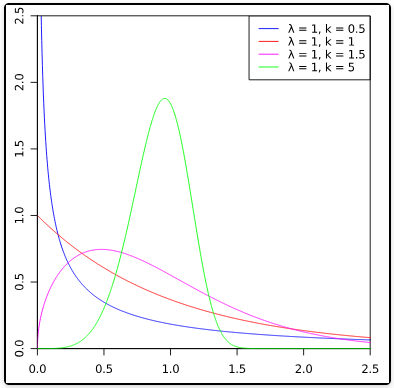
- 概率密度函数 (概率密度)f(x;λ,k)={λk(λx)k−1e−(x/λ)k0x≥0x≤0
- 其中,x 是随机变量,λ>0 是比例参数(scale parameter),k>0 是形状参数(shape parameter)。显然,它的累积分布函数是扩展的指数分布函数,而且,Weibull distribution 与很多分布都有关系。如,当 k=1,它是指数分布;k=2 时,是 Rayleigh distribution(瑞利分布)
![]()
- 期望:E=λΓ(1+k1) 方差: V=λ2[Γ(1+k2)−Γ(1+k1)2]
什么是 F 分布?
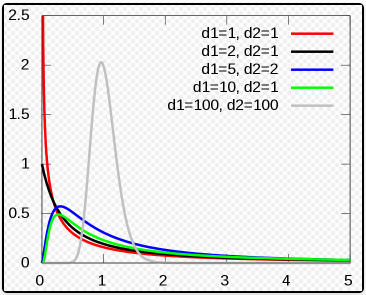
在概率论和统计学里,F - 分布是一种连续概率分布,被广泛应用于似然比率检验![]()
概率密度函数 (概率密度)
f(x;d1,d2)=xB(2d1,2d2)(d1,x+d2)(d1+d2)(d1,x)d1d22d
这里 B 是 B 函数。在很多应用中,参数 d1 和 d2 是正整数,但对于这些参数为正实数时也有定义
期望:d2−2d2,for d2≥2 方差 :d1(d2−2)2(d2−4)2d22(d1+d2−2),for d2≥4
一个 F - 分布的随机变量是两个卡方分布变量除以自由度的比率 U2/d2U1/d1=d1/d2U1/U2 , U1 和 U2 呈卡方分布,它们的自由度(degree of freedom)分别是 d1 和 d2,U1 和 U2 是相互独立的
什么是 T 分布?
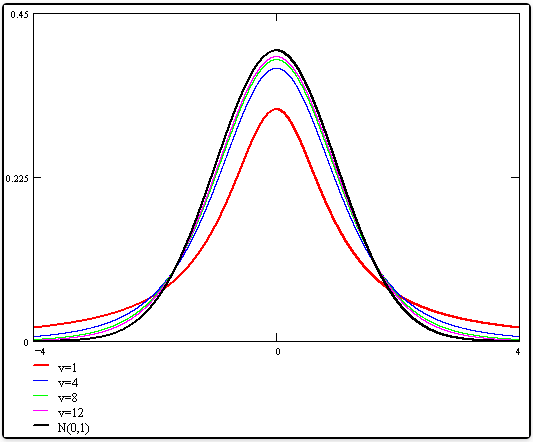
- 在概率论和统计学中,学生 t - 分布可简称为 t 分布,用于根据小样本来估计呈正态分布且方差未知的总体的均值。如果总体方差已知(例如在样本数量足够多时),则应该用正态分布来估计总体均值。它是对两个样本均值差异进行显著性测试的学生 t 检定的基础
- 概率密度函数 (概率密度) f(t)=νπΓ(2ν)Γ(2ν+1)(1+νt2)−2ν+1 ,ν 等于 n − 1。 T 的分布称为 t - 分布。参数 ν 一般被称为自由度。Γ 是伽玛函数
![]()
- 期望:ν>1 时为 0,ν=1 为定义 方差:ν>2 , 时为ν−2ν , 否则无穷大
- T 的概率密度函数 (概率密度) 的形状类似于均值为 0 方差为 1 的正态分布,但更低更宽。随着自由度ν 的增加,则越来越接近均值为 0 方差为 1 的正态分布
什么是贝塔分布?
- 在概率论中,Β 分布也称贝塔分布,是指一组定义在 (0,1) 区间的连续概率分布,有两个参数 α , β > 0. 记为X∼Be(α,β)
- B 分布可以看做是分布之上的分布,当你不知道一个东西的具体概率是多少时,它可以给出了所有概率出现的可能性大小
- 概率密度函数 (概率密度):f(x;α,β)=∫01uα−1(1−u)β−1dux(α−1)(1−x)(β−1)
- 期望:E=α+βα 方差: V=(α+β)2(α+β+1)αβ
什么是卡方分布?
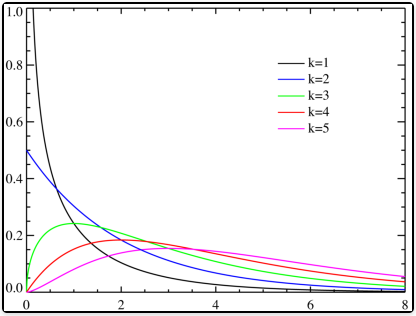
- 卡方分布是概率论与统计学中常用的一种概率分布。k 个独立的标准正态分布变量的平方和服从自由度为 k 的卡方分布,记为 X∼χ2(k)
- 卡方分布是一种特殊的伽玛分布,是统计推断中应用最为广泛的概率分布之一,例如假设检验和置信区间的计算
- 概率密度函数 fk(x)=Γ(2k)212kx2k−1e2−x
- 其中 x≥0,当 x≤0 时fk(x)=0 。这里 Γ 代表 Gamma 函数
![]()
- 期望:k 方差: ≈k(1−9k2)3
由卡方分布延伸出来皮尔森卡方检定的用处?
- 样本某性质的比例分布与总体理论分布的拟合优度(例如某行政机关男女比是否符合该机关所在城镇的男女比);
- 同一总体的两个随机变量是否独立(例如人的身高与交通违规的关联性);
- 二或多个总体同一属性的同素性检定(意大利面店和寿司店的营业额有没有差距)。(详见皮尔森卡方检定)
什么是拉普拉斯分布?
在概率论与统计学中,拉普拉斯分布 (Laplace distribution) 是一种连续概率分布。由于它可以看作是两个不同位置的指数分布背靠背拼接在一起,所以它也叫作双指数分布
两个相互独立同概率分布指数随机变量之间的差别是按照指数分布的随机时间布朗运动,所以它遵循拉普拉斯分布
概率密度函数 (概率密度)
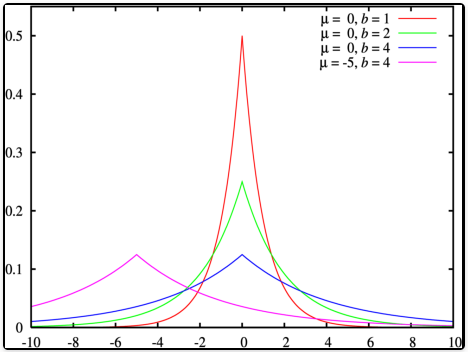
f(x∣μ,b)=21exp(−b∣x−μ∣)=2b1{exp(−bμ−x),exp(−bx−),if x<μif x≥μ
![]()
μ 是位置参数,b > 0 是尺度参数。如果 μ = 0,那么,正半部分恰好是尺度为 1/2 的指数分布
期望:μ 方差: 2b2
正态分布是用相对于 μ 平均值的差的平方来表示,而拉普拉斯概率密度函数 (概率密度) 用相对于平均值的差的绝对值来表示。因此,拉普拉斯分布的尾部比正态分布更加平坦
已知区间 (-1/2, 1/2] 中均匀分布上的随机变量 U,随机变量X=μ−bsgn(U)ln(1−2∣U∣) 为参数 μ 与 b 的拉普拉斯分布