pix2pix:Image-to-Image Translation with Conditional Adversarial Networks
通过在 GAN 中训练成对的图片,完成图片从一个域到另一个域的转换
图片 -> 图片,图生图
什么是 pix2pix ?
![]()
- 训练成对数据,相当于 GAN+Segment,完成图片到图片的学习

pix2pix 的网络结构?
![]()
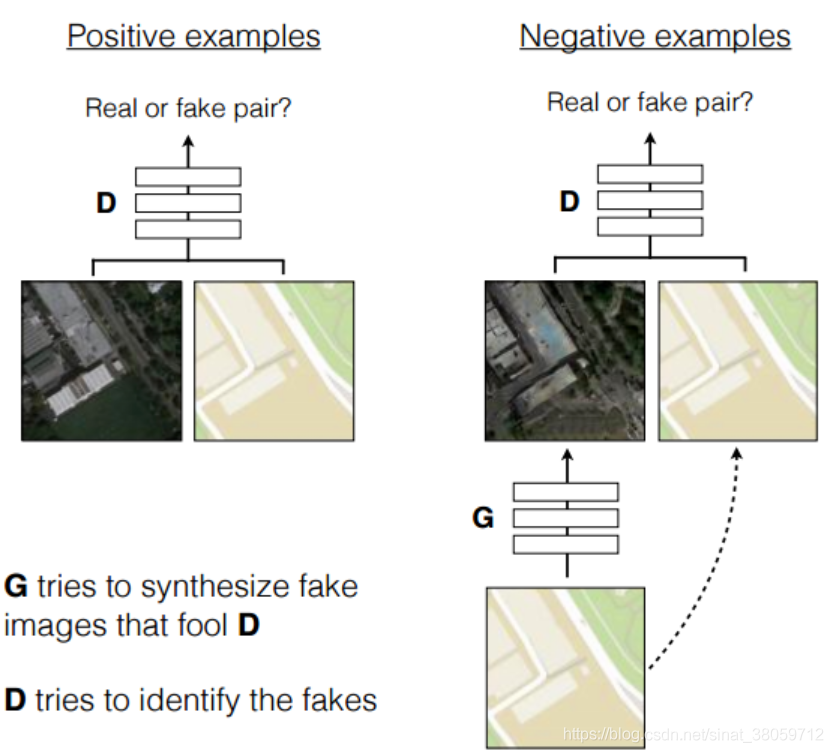
- 参考 cGAN,将标签 y 换成成对图片 (A/B) 其中的一个(假设 A),然后生成器的目的就是 A->B’, 左图是 B+A 输入判别网络,判别为真实图片,右图是 B’+A 输入判别网络。训练完成时 B’接近 B,也就接近做到 A->B
pix2pix 的损失函数?
![]()
- pix2pix 结合了两种损失函数,一种是 cGAN 损失,另一一种是生成样本和真实样本的 L1 距
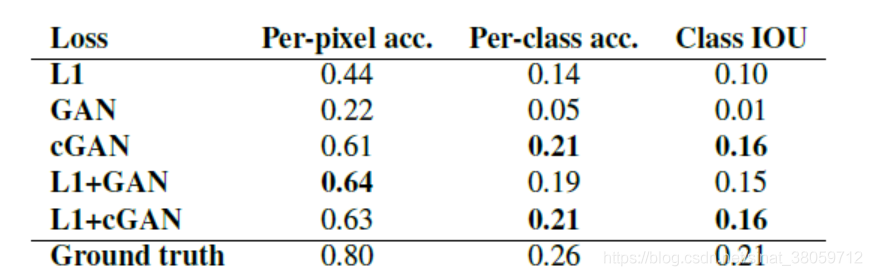
- cGAN 损失:
- L1 损失:
- 没有 z ,网络仍然可以学习从 x 到 y 的映射,但是会产生确定性的输出,因此无法匹配除增量函数以外的任何分布。对于我们最后的模型,我们只在 dropout 结构上提供了噪声,在训练和测试时运用在 G 的几个层上面。尽管存在 dropout 的噪声,在我们的网络输出中,只观察到了微弱的随机性(这是 pix2pix 的限制,生成的图片随机性不够)
pix2pix 的 PathGAN 判别器?
![]()
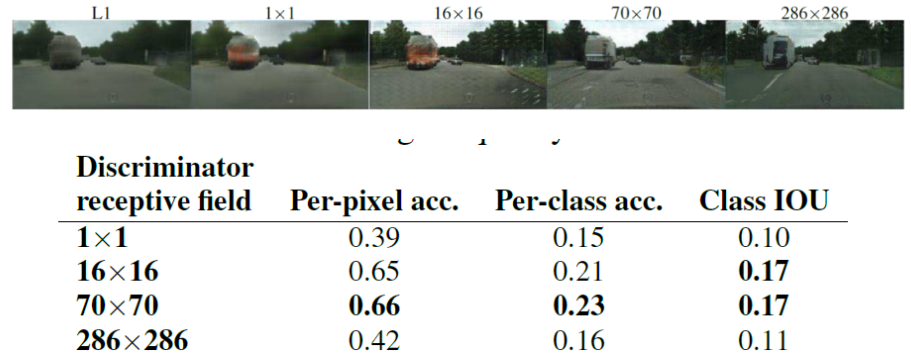
- 这个鉴别器试着分辨每一个 N × N 的 Patch 是真的还是假的,然后平均所有的相应来得到最后的输出 D,图中可以看出 70x70 效果最好
- 将一张图片所有 patch 的结果取平均值作为最终的判别器输出,而不是判断整个图像的 “真与假”。这会强制实施更多约束,能更好的判别高频信息。即使 N NN 远小于原图的大小,patchGAN 依然可以产生较好的结果。并且,它具有更少的参数,可以降低计算量,运行更快,提升效果,并且可以运用于任意大的图像
参考: