我的图像生成学习路线
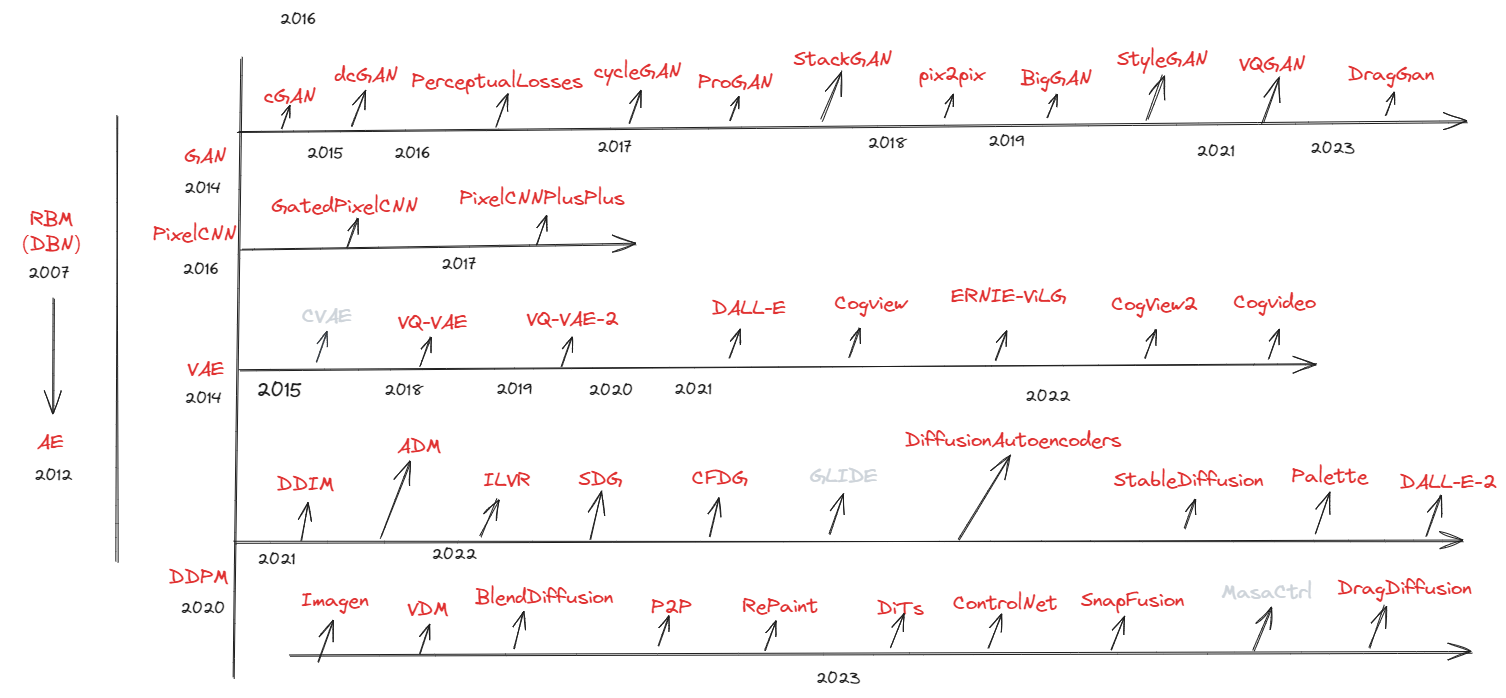
总结自己在目标生成上的学习过程
生成模型技术路线?
![Drawing-2023-11-30-21.30.32.excalidraw]()
- 深度学习生成模型的数据生成过程,可以看成是:从一个先验分布 Z 采样变换成数据分布 X 的过程
- GAN:生成对抗性网络,有:CGAN,DCGAN,StyleGAN,BigGAN,StackGAN,Pix 2 pix,Age-cGAN,CycleGAN 等
- VAE:自编码器的升级版,对隐变量加上限制,并通过最大化似然函数实现学习,有 VQ-VAE、DALL-E 等模型
- pixelCNN:将空间上排布的像素点看作是有顺序的自回归预测过程,使用修改的卷积核实现以上过程,有 PixelCNN,GatedPixelCNN,PixelCNN++ 等
- Diffusion models:受非平衡热力学的启发。定义一个扩散步骤的马尔可夫链,逐渐向数据添加随机噪声,然后学习逆扩散过程,从噪声中构建所需的数据样本
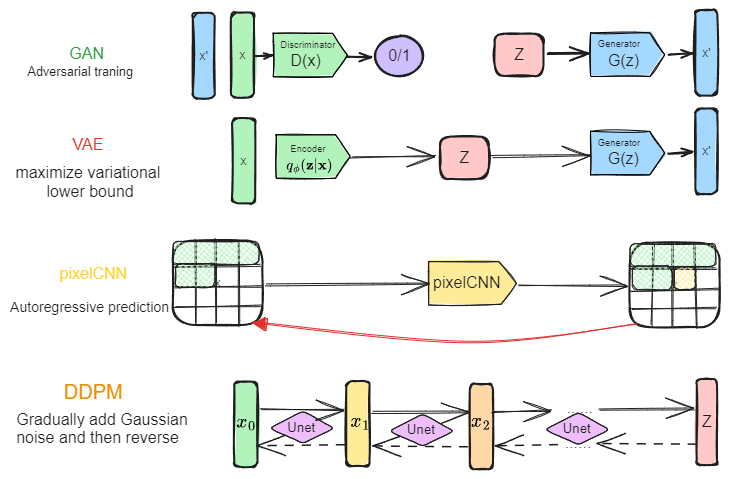
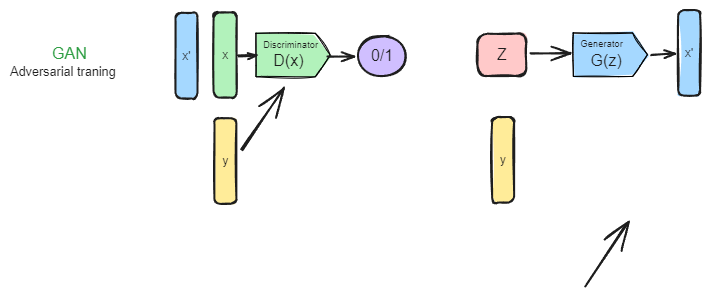
GAN 生图思路总结?
![Drawing-2023-11-30-22.04.32.excalidraw]()
- 原始版本:生成器从固定分布(如高斯分布)随机采样数据,并通过神经网络将其变换为图片,然后搭配判别器交替训练,通过对抗进行学习,最终网络完成高斯分布 -> 训练数据分布的过程,从高斯分布采样后即可生成和训练集匹配的图片
- 条件引导:条件类型有:类别、图片、文本等,一般来说将条件同时加到生成器、判别器即可
- 提升质量:先训练低分辨率,再训练高分辨率
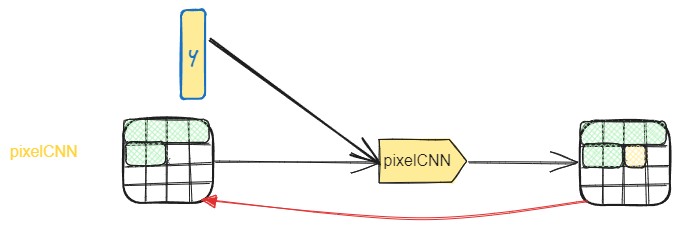
PixelCNN 生图思路总结?
![Drawing-2023-11-30-22.07.43.excalidraw]()
- 原始版本:借助 NLP 循环输入预测下一字词的特点,使用以前的像素预测下一像素。因为是自回归预测的,所以预测一张图时,需要先提供第一个像素的信息
- 条件引导:直接将条件引导加入到自回归过程中
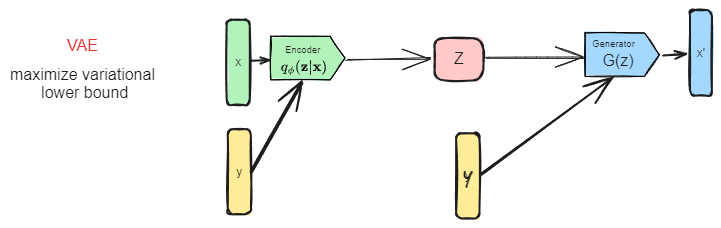
VAE 生图思路总结?
![Drawing-2023-11-30-22.10.35.excalidraw]()
- 原始版本:直接输入原图,通过编码器将其编码到潜空间,然后使用解码器中从潜空间中采样出生成图片,并且要求潜空间满足标准正太分布。推理时首先从标准正太分布采样,然后使用解码器生成图片
- 条件引导:将条件引导分别输入编码器和解码器即可
DDPM 生图思路总结?
![Drawing-2023-11-30-22.11.55.excalidraw]()
- 原始版本:输入原图,通过采样标准高斯分布,逐步向图片加躁,并用神经网络估计噪声,直至图片变成高斯噪声,然后使用神经网络逐步去噪,还原图片。推理时,从标准高斯分布采样,逐步去躁,直至执行 t 次去躁
- 条件引导:分为 Classifier-guidance、Free-guidance 两种:1)Classifier-guidance 通过在去躁过程影响采样均值,完成引导,所以这里需要训练:不同时刻噪声图片 -> 条件的网络,比如如果是类别引导,就需要不同时刻噪声图片 -> 类别,条件还可以是 seg、sketch、text 等;2)Free-guidance 通过将条件加入到加躁过程,一起训练,实际训练玩玩是随机将条件置空,使得网络具备无条件、有条件的预测能力,最后通过权重将两种情况线性组合
- 提升质量:DDPM 不一定从原图开始做,可以从中间隐变量开始,比如 VAE 的中间潜变量,去躁后再通过 VAE 的 decoder 还原为图片,如此既降低成本,又提高泛化能力,如 stablediffusion

按最终控制效果分,生成图片有那几种方式?
- 从最初的类别粗浅的控制,到后续主体目标等精细的控制,目前已经到交互式控制层面
- 符合特定类别的图片:CGAN、CVAE、ADM
- 符合文本描述的图片:StackGAN、DALL-E、GLIDE、DALL-E-2
- 符合引用图片(rgb/mask/sketch/pose)的图片:SDG、ControlNet
- 目标主体不变,变化布局、风格的图片:DiffusionAutoencoders、 P2P、BlendDiffusion
- 目标主体不变,按照交互方式变化的图片:DragGan、DragDiffusion
DDPM 的条件控制方式?
| 方法 | 思路 | 优点 | 缺点 | |
|---|---|---|---|---|
| DDPM | 根据马尔科夫链和贝叶斯定理,将图片生成分为扩散和去躁两个过程,通过神经网络估计每一个时间步的噪声 | - | 需要多次递推,才能生成图片 | |
| image-guidance | 无训额外训练,通过计算噪声图片与引用图片在低通滤波器的特征差异,引导去躁过程 | 无训额外训练 | 引导不够准确 | ILVR |
| Classifier-guidance | 直接在原有训练好的扩散模型上,通过外部的分类器来引导生成期望的图像。唯一需要改动的地方其实只有 sampling 过程中的高斯采样的均值,也即采样过程中,期望噪声图像的采样中心越靠近判别器引导的条件越好 | 不用额外训练扩散模型 | 需要基于噪声图片训练分类器 | ADM 、SDG 、 |
| Free-guidance | 将引导信息直接和加躁图片训练,恢复时是加引导噪声图片和未加引导噪声图片的线性组合 | 不需要单独训练引导器 | 需要大量的成本训练噪声估计器 | CFDG、GLIDE、DiffusionAutoencoders、StableDiffusion-LDM、DALL-E-2 |
| CLIP-guidance | 解决文本对数据如果利用文本生成图片的过程,一般在训练过程中直接使用交叉注意力融合图片特征和文本特征 | CLIP 可以对生成图片和文本匹配度打分排序 | CLIP 如果应用到扩散模型,需要基于加躁图片重新训练 | Imagen、DALL-E-2 |
| 指标 | 源与目标 | 描述 | 优缺点 |
|---|---|---|---|
| IS | 生成图片 VS 类别 | InceptionNetV 3 输出生成图片的类别,然后计算生成图片到各个类别的距离(熵),越小越生成效果越好 | - |
| FID | 生成图片 VS 真实图片 | InceptionNetV 3 输出真实图片、生成图片的特征矩阵,然后计算两个特征矩阵的距离,越小越相似 | - |
| PPL | 生成图片 VS 目标图片 | 评估利用生成器从一个图片变道另一个图片的距离,越小越好 | - |
| CLIP Score | 生成图片 VS 预设文本 | 评估生成图片和输入文本的距离,越小越相似 | - |
| SSIM | 生成图片 VS 目标图片 | SSIM 从亮度、对比度以及结构量化图像的属性,用均值估计亮度,方差估计对比度,协方差估计结构相似程度 | - |
| PSNR | 生成图片 VS 目标图片 | 衡量最大值信号和背景噪音之间的图像质量参考值 | - |
| PD | 生成图片 VS 目标图片 | 评估生成图片和真实图片的距离,越小越相似 | - |
| LPIPS | 生成图片 VS 目标图片 | 用于度量两张图像之间的差别,分块进行分析 | - |
图像生成的评价指标 IS (Inception Score)?
- IS 基于 InceptionNetV3,输入是图像,输出是 1000 维的向量,即属于某一类的概率。IS 用来衡量 GAN 网络的两个指标:生成图片质量、图片多样性,生成的图片,足够清晰且生成类别多样,所有 IS 越大越
- 清晰度:IS 对于生成的图片 x 输入到 InceptionNetV3 中产生一个 1000 维的向量 y。其中每一维代表数据某类的概率。对于清晰的图片来说,y 的某一维应该接近 1,其余维接近 0。即对于类别 y 来说, p (y|x) 的熵很小(概率比较确定)
- 多样性:对于所有的生成图片,应该均匀分布在所有的类别中。比如共生成 10000 张图片,对于 1000 类别,每一类应该生成 10 张图片。即 的熵很大,总体分布接近均匀分布
- 缺点:(1)InceptionNetV 3 是在 ImageNet 1000 分类训练的,在 CIFAR-10 上结果是 4.664 bit,在随机噪声图片上结果是 6.512 bit,真实的图片数据集 CIFAR-10 居然和随机噪声图片的结果相近,所以不能使用在一个数据集上训练分类模型,评估在另一个数据集上训练的生成模型;(2)神经网络中权值的细节改变可能很大的影响 IS 分数;(3)Inception Score 高的图片不一定真实;(4)Inception Score 低的图片不一定差
图像生成的评价指标 FID (Fréchet Inception Distance)?
- 衡量真实图像和生成图像的特征向量之间距离的一种度量,FID 使用 InceptionNetV3 全连接前的 2048 维向量作为图片的 feature,其中 r, g 表示真实图片和生成图片的特征, 表示真实、生成图片特征均值, 表示真实、生成图片特征的协方差矩阵, 表示矩阵对角线上元素的综合,矩阵论中称为矩阵的迹 $$FID=||\mu_r-\mu_g||2+Tr(\Sigma_r+\Sigma_g-2(\Sigma_r\Sigma_g){1/2})$$
- FID 在最佳情况下的得分为 0.0,表示两组图像相同。分数越低代表两组图像越相似,或者说二者的统计量越相似
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33import numpy
from numpy import cov
from numpy import trace
from numpy import iscomplexobj
from numpy.random import random
from scipy.linalg import sqrtm
def calculate_fid(act1, act2):
# calculate mean and covariance statistics
mu1, sigma1 = act1.mean(axis= 0), cov(act1, rowvar= False) # (2048,) (2048, 2048)
mu2, sigma2 = act2.mean(axis= 0), cov(act2, rowvar= False) # (2048,) (2048, 2048)
# calculate sum squared difference between means
ssdiff = numpy.sum((mu1 - mu2)* 2.0) # -10.6
# calculate sqrt of product between cov
covmean = sqrtm(sigma1.dot(sigma2)) # (2048, 2048)
# check and correct imaginary numbers from sqrt
if iscomplexobj(covmean): # True
covmean = covmean.real # (2048, 2048)
# calculate score
fid = ssdiff + trace(sigma1 + sigma2 - 2.0*covmean) # 306
return fid
act1 = random(20480)
act1 = act1.reshape((10, 2048))
act2 = random(20480)
act2 = act2.reshape((10, 2048))
fid = calculate_fid(act1, act1)
print( 'FID (same): %.3f'% fid) # 0
fid = calculate_fid(act1, act2)
print( 'FID (different): %.3f'% fid) # 306
图像生成评价指标 PPL (Perceptual Path Length)?
![]()
- 给出两个随机噪声 z 1, z 2,为求得两点的感知路径长度 (Perceptual Path Length, PPL),采用微分的思想。把两噪声点插值路径细分成多个小段,求每个小段的长度,再求平均
- PPL 评估利用生成器从一个图片变道另一个图片的距离,越小越好。其中 表示细小分段,用 1 e-4 替代,d 表示 perceptual distance,使用预训练的 VGG 来衡量,G 表示生成器,slerp 是球面线性插值,一种插值方式,t 是插值参数,服从均匀分
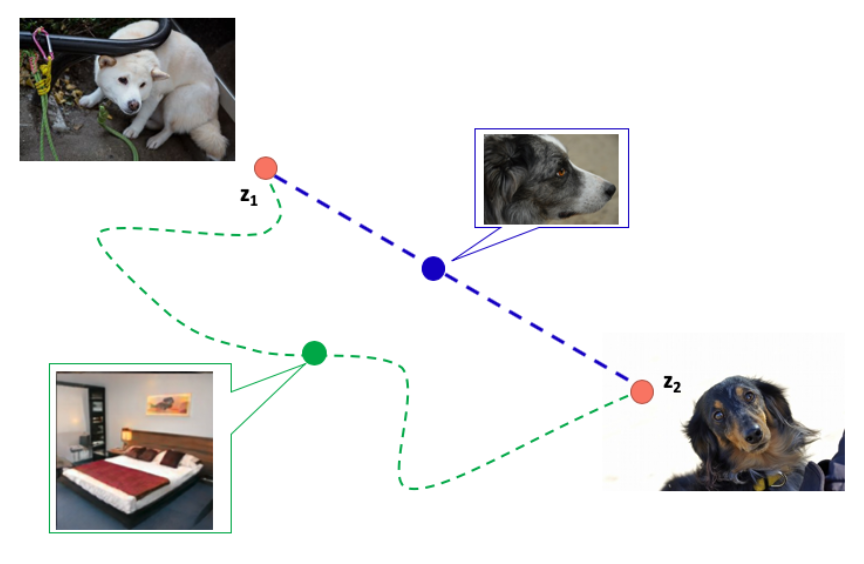
- 在优秀的 GAN 网络中,得到的结果应该是 perceptual 距离也是最短的,类似 z 1 变换到 z 2 时,其移动路线应该是蓝色的,而不是绿色的
图像生成评价指标 CLIP Score?
CLIP Score通过学习自然语言和图像对之间的语义关系来捕捉它们之间的意义关系。将自然语言和图像对分别转换为特征向量,然后计算它们之间的余弦相似度- 当
CLIP Score较高时,图像 - 文本对之间的相关性更高。CLIP Score评估自然语言和图像对之间的匹配度和相关性。值越大(接近 1),评估越高
图像的结构相似性指数(structural similarity index,SSIM)?
- 用于量化两幅图像间的结构相似性的指标。与 L2 损失函数不同,SSIM 仿照人类的视觉系统实现了结构相似性的有关理论,对图像的局部结构变化的感知敏感
- SSIM 从亮度、对比度以及结构量化图像的属性,用均值估计亮度,方差估计对比度,协方差估计结构相似程度。SSIM 值的范围为 0 至 1,越大代表图像越相似。如果两张图片完全一样时,SSIM 值为 1
图像的峰值信噪比 (Peak Signal to Noise Ratio, PSNR)?
- 一种评价图像质量的度量标准,衡量最大值信号和背景噪音之间的图像质量参考值。PSNR 的单位为 dB,其值越大,图像失真越少。一般来说,PSNR 高于 40 dB 说明图像质量几乎与原图一样好;在 30-40 dB 之间通常表示图像质量的失真损失在可接受范围内;在 20-30 dB 之间说明图像质量比较差;PSNR 低于 20 dB 说明图像失真严重
- 给定一个大小为 m×n 的灰度图 I 和噪声图 K,均方误差 (MSE, Mean Square Error) 公
图像的感知距离(Perceptual Distance, PD)?
- 类似计算感知损失的过程 PerceptualLosses 的损失函数
图像块相似度 (Learned Perceptual Image Patch Similarity, LPIPS)?
- 用于度量两张图像之间的差别,该度量标准学习生成图像到 Ground Truth 的反向映射强制生成器学习从假图像中重构真实图像的反向映射,并优先处理它们之间的感知相似度
- 给定 Ground Truth 图像参照块 x 和含噪声图像失真块 x0,感知相似度度量公式如下,其中 l 表示第 l 个特征层
通过蒸馏减少扩散模型的采样步数有哪些方法?
- 渐进式(progressive distillation):目标是将一个步骤很多的教师扩散模型蒸馏为一个步骤较少的学生模型,一般通过反复迭代的方式进行
- 条件引导蒸馏(guided diffusion distillation):将 Classifier-Free Guidance 扩散模型蒸馏为采样步骤更少的学生模型,该方法可以分解为两个阶段,第一个阶段是 w-condition 蒸馏,第二阶段是与第二节类似的渐进式蒸馏
- step distillation:与常规扩散模型不同,Step Distillation 使用的扩散模型预测速度 效果优于预测噪声 ,即 UNet 输出速度 而不是噪声
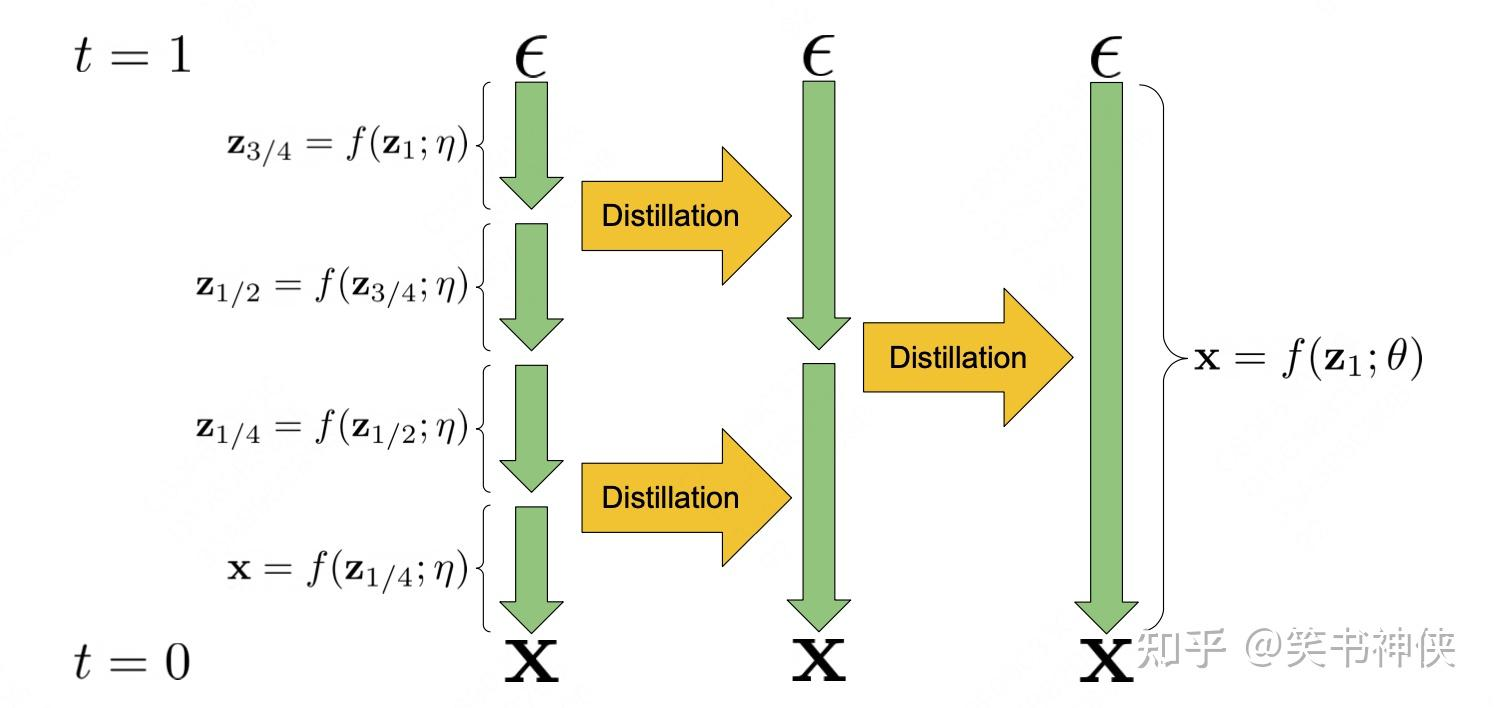
扩散模型的渐进式(progressive distillation)?
![]()
- 将一个步骤很多的教师扩散模型蒸馏为一个步骤较少的学生模型,一般通过反复迭代的方式进行
- 教师采样器 通过 4 个确定性步骤将随机噪声 ε 映射到样本 x,学生采样器 只需一步即可学习到这种映射关系
什么是图像风格迁移?
![]()
- 所谓风格迁移,就是让一张图片具有其原本的内容 content,同时具有另一张图片(通常是艺术作品)的风格 style
- 风格迁移难点:在于如何保留内容的同时模拟目标图片的风格,内容就是图片本身,风格是图片的整体表现,没有直接量化指标,在风格迁移领域使用 Gram 矩阵评估一张图片的风格,比较两种图片的 Gram 矩阵,可以得出两种图片的风格距离

参考:
- 机器学习 “判定模型” 和 “生成模型” 有什么区别? - 知乎
- 各种生成模型:VAE、GAN、flow、DDPM、autoregressive models_AI 强仔的博客 - CSDN 博客
- 生成模型 (四): 扩散模型 - 知乎
- FID 图像质量评估指标_fid 指标 - CSDN 博客
- 生成专题 2 | 图像生成评价指标 FID - 知乎
- FID 图像质量评估指标_fid 指标 - CSDN 博客
- IS、FID、PPL,GAN 网络评估指标 - 知乎
- 基于扩散模型的文本引导图像生成算法 - CSDN 博客
- Text-to-Image 图像生成系列之 GLIDE - 知乎
- 有真实参照的图像质量的客观评估指标:SSIM、PSNR 和 LPIPS - 知乎
- 扩散模型算法加速之一:跨步蒸馏 - 知乎