模型部署基础知识
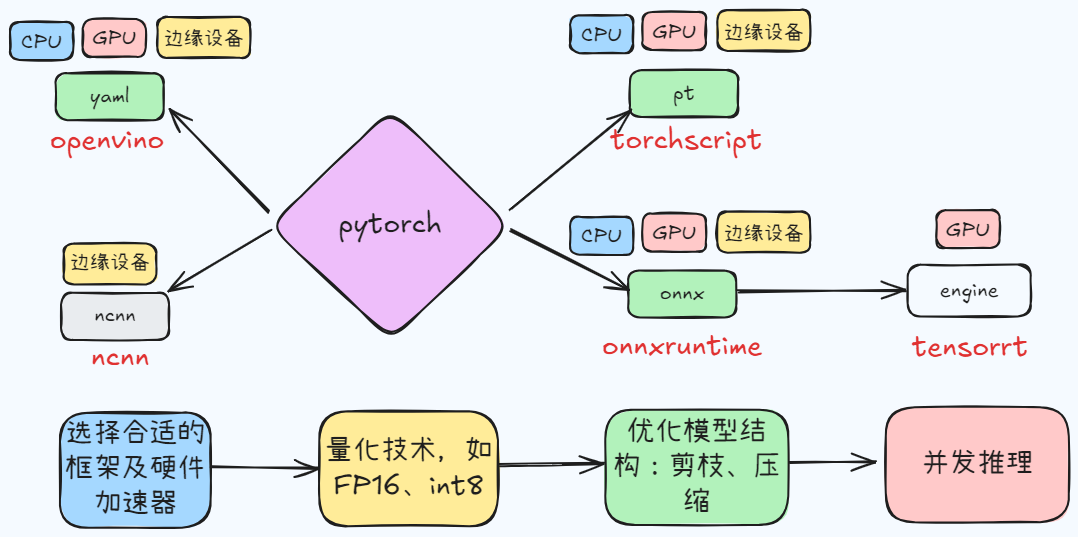
从模型部署的转换、压缩讲起,然后总结移动端的模型部署,目前部署思路如上
什么是模型转换?
- 在现实场景中,咱们常常会遇到这样一个问题,即某篇论文的结果很棒,可是做者提供的训练模型是使用 pytorch 训练的,而我本身却比较擅长用 tensorflow,此时需要进行模型转换
- 模型转换: 将使用不一样训练框架训练出来的模型相互联系起来,用户能够进行快速的转换,节省了大量的人力和物力花销,比较有名的包括 mmdnn、ONNX 等
模型转换工具 mmdnn?
![]()
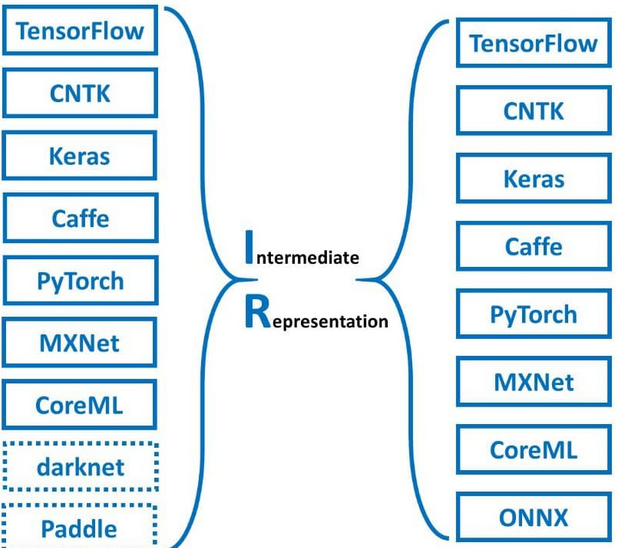
- MMDNN 是一套帮助用户在不一样的深度学习框架之间进行交互操做的工具。例如,模型转换和可视化。转换 caffe、keras、mxnet、tensorflow、cntk、pytorch onnx 和 coreml 之间的模型
- MMDNN 包含了一个关键的概念,那就是 Intermediate Representation - 中间表示,即这个工具首先将输入框架的模型转换为 IR,而后经过 IR 转换成另一个框架所支持的模型
什么是模型压缩加速?
- 利用数据集对已经训练好的深度模型进行精简,进而得到一个轻量且准确率相当的网络,压缩后的网络具有更小的结构和更少的参数,可以有效降低计算和存储开销,便于部署再受限的硬件环境中
为什么需要模型压缩和加速?
![]()
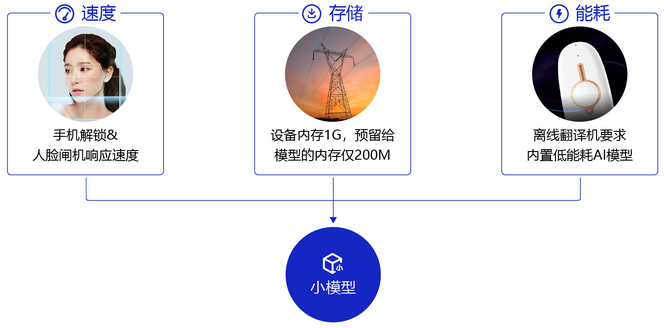
- 速度要求高: 比如像人脸闸机、人脸解锁手机等应用,对响应速度比较敏感,需要做到实时响应
- 存储有限: 比如电网周边环境监测这个应用场景中,要图像目标检测模型部署在可用内存只有 200M 的监控设备上,且当监控程序运行后,剩余内存会小于 30M,在许多网络结构中,如 VGG-16 网络,参数数量 1 亿 3 千多万,占用 500MB 空间,需要进行 309 亿次浮点运算才能完成一次图像识别任务
- 耗能低: 离线翻译这种移动设备内置 AI 模型的能耗直接决定了它的续航能力
为什么模型可以压缩?
- 虽然一般的神经网络都有上百万的参数, 但是并不是所有的参数都在模型中发挥作用,部分参数作用有限、表达冗余,甚至会降低模型的性能。
- 论文《Predicting parameters in deep learning》 提出,很多的深度神经网络仅仅使用很少一部分(5%)权值就足以预测剩余的权值。该论文还提出这些剩下的权值甚至可以直接不用被学习。也就是说,仅仅训练一小部分原来的权值参数就有可能达到和原来网络相近甚至超过原来网络的性能
目前有哪些深度学习模型压缩方法?
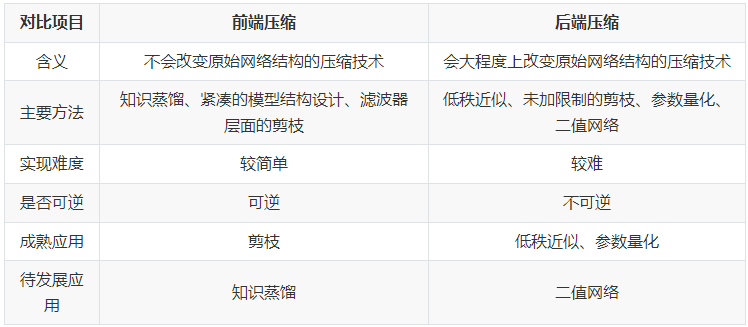
- 目前深度学习模型压缩方法可分为前端压缩和后端压缩
![]()
总体压缩效果评价指标有哪些?
- 网络压缩评价指标包括运行效率、参数压缩率、准确率。与基准模型比较衡量性能提升时,可以使用提升倍数 (speedup) 或提升比例 (ratio)
- 参数压缩率: 统计网络中所有可训练的参数,根据机器浮点精度转换为字节 (byte) 量纲,通常保留两位有效数字以作近似估计.
- 运行效率: 可以从网络所含浮点运算次数 (FLOP)、网络所含乘法运算次数 (MULTS) 或随机实验测得的网络平均前向传播所需时间这 3 个角度来评价
压缩和加速方法如何选择?
- 1)对于在线计算内存存储有限的应用场景或设备,可以选择参数共享和参数剪枝方法,特别是二值量化权值和激活、结构化剪枝.其他方法虽然能够有效的压缩模型中的权值参数,但无法减小计算中隐藏的内存大小
- 2)如果在应用中用到的紧性模型需要利用预训练模型,那么参数剪枝、参数共享以及低秩分解将成为首要考虑的方法.相反地,若不需要借助预训练模型,则可以考虑紧性滤波设计及知识蒸馏方法.
- 3)若需要一次性端对端训练得到压缩与加速后模型,可以利用基于紧性滤波设计的深度神经网络压缩与加速方法.
- 4)一般情况下,参数剪枝,特别是非结构化剪枝,能大大压缩模型大小,且不容易丢失分类精度.对于需要稳定的模型分类的应用,非结构化剪枝成为首要选择.
- 5)若采用的数据集较小时,可以考虑知识蒸馏方法.对于小样本的数据集,学生网络能够很好地迁移教师模型的知识,提高学生网络的判别性.
- 6)主流的5个深度神经网络压缩与加速算法相互之间是正交的,可以结合不同技术进行进一步的压缩与加速,此外对于特定的应用场景,如目标检测,可以对卷积层和全连接层使用不同的压缩与加速技术分别处理
改变网络结构设计为什么会实现模型压缩、加速?
- 使用分组卷积 (Group Convolution) 减少了 1/g 的参数量
- 随着卷积通道数的增加,深度可分离卷积 (depthwise separable convolution) 的运算量相对于传统卷积更少
- 卷积层的输入和输出特征通道数相等时 MAC (内存访问成本) 最小
- 过多的 group 操作会增大 MAC,从而使模型速度变慢
- 模型中分支数量越少,模型速度越快
- 减少元素级操作
影响神经网络速度的 4 个因素?
- FLOPs (FLOPs 就是网络执行了多少 multiply-adds 操作)
- MAC (内存访问成本)
- 并行度 (如果网络并行度高,速度明显提升)
- 计算平台 (GPU,ARM)
目前主流的深度学习部署平台及部署框架?
![]()
- 主流的深度学习部署设备包含 GPU、CPU、ARM
- 模型部署框架则有英伟达推出的 TensorRT,谷歌的 Tensorflow 和用于 ARM 平台的 tflite,开源的 caffe,百度的飞浆,腾讯的 NCNN

什么是 OpenVIO ?
- openVIO 是 Intel 官方针对 Intel cpu 推出的一款加速工具。该工具专一于边缘端的推理;用户可使用该工具对 Intel 的 CPU/GPU/FPGA 等产品进行加速;能够直接调用优化好的 Opencv 和 OpenVX 包,参考: Intel® Distribution of OpenVINO™ Toolkit
- OpenVIO 不只能够用来执行基于深度学习的一些 CV 任务,并且能够用来执行一些传统的 CV 任务。除此以外,它还能够对特定的硬件进行加速。经过 openVIO,你可让你的算法在 CPU 端实现 4~5 倍的加速,它让你的算法运行在 CPU 端成为了可能,在不少应用场景下面会具备更高的性价比
什么是 NCNN ?
- 2017 年 7 月腾讯优图开源的移动端模型部署框架, 参考:GitHub - Tencent/ncnn: ncnn is a high-performance neural network inference framework optimized for the mobile platform
- 1)NCNN 考虑了手机端的硬件和系统差异以及调用方式,架构设计以手机端运行为主要原则。
- 2)无第三方依赖,跨平台,手机端 CPU 的速度快于目前所有已知的开源框架(以开源时间为参照对象)。
- 3)基于 ncnn,开发者能够将深度学习算法轻松移植到手机端高效执行,开发出人工智能 APP
什么是 MNN ?
- MNN 是一个轻量级的深度神经网络推理引擎,在端侧加载深度神经网络模型进行推理预测。参考:GitHub - alibaba/MNN: MNN is a blazing fast, lightweight deep learning framework, battle-tested by business-critical use cases in Alibaba
- 目前,MNN 已经在阿里巴巴的手机淘宝、手机天猫、优酷等 20 多个 App 中使用,覆盖直播、短视频、搜索推荐、商品图像搜索、互动营销、权益发放、安全风控等场景。此外,IoT 等场景下也有若干应用
移动端模型部署框架 QNNPACK 的特点?
- 2018 年 10 月 Facebook 开源的移动端模型部署框架,全称:Quantized Neural Network PACKage(量化神经网络包),参考:GitHub - pytorch/QNNPACK: Quantized Neural Network PACKage - mobile-optimized implementation of quantized neural network operators
- 1)低密度卷积优化函数库;
- 2)可在手机上实时运行 Mask R-CNN 和 DensePose;
- 3) 能在性能受限的移动设备中用 100ms 以内的时间实施图像分类;
移动端模型部署框架 Prestissimo 特点?
- 2017 年 11 月九言科技开源的移动端模型部署框架, 参考:GitHub - in66-dev/In-Prestissimo: A very fast neural network computing framework optimized for mobile platforms.QQ group: 676883532 【验证信息输:绝影】
- 1)支持卷积神经网络,支持多输入和多分支结构
- 3)精炼简洁的 API 设计,使用方便
- 4)提供调试接口,支持打印各个层的数据以及耗时
- 5)不依赖任何第三方计算框架,整体库体积 500K 左右(32 位 约 400k,64 位 约 600k)
- 5)纯 C++ 实现,跨平台,支持 android 和 ios
- 6)模型为纯二进制文件,不暴露开发者设计的网络结构
移动端模型部署框架 TNN 特点?
- 由腾讯优图实验室打造,移动端高性能、轻量级推理框架,同时拥有跨平台、高性能、模型压缩、代码裁剪等众多突出优点。参考:TNN/ at master · Tencent/TNN · GitHub
- TNN 框架在原有 Rapidnet、NCNN 框架的基础上进一步增强了移动端设备的支持以及性能优化,同时也借鉴了业界主流开源框架高性能和良好拓展性的优势,
移动端模型部署框架 Paddle-Mobile 特点?
- 百度开源的移动端模型部署框架, 参考:GitHub - PaddlePaddle/Paddle-Lite: Multi-platform high performance deep learning inference engine (飞桨多端多平台高性能深度学习推理引擎)
- 1)高性能支持 ARM CPU
- 2)支持 Mali GPU
- 3)支持 Andreno GPU
- 4)支持苹果设备的 GPU Metal 实现
- 5)支持 ZU5、ZU9 等 FPGA 开发板
- 6)支持树莓派等 arm-linux 开发板
移动端模型部署框架 Paddle Lite 特点?
- 是 Plader Mobile 的更新版本,这是一个开源的深度学习框架,旨在使在移动、嵌入式和物联网设备上执行推理变得容易。它与飞桨和其余来源的预训练模型兼容,参考:github.com/PaddlePaddle/Paddle Lite
移动端模型部署框架 MACE( Mobile AI Compute Engine)特点?
- 2018 年 4 月小米开源的移动端模型部署框架, 参考:GitHub - XiaoMi/mace: MACE is a deep learning inference framework optimized for mobile heterogeneous computing platforms.
- Mobile AI Compute Engine (MACE) 是一个专为移动端异构计算设备优化的深度学习前向预测框架。 MACE 覆盖了常见的移动端计算设备(CPU,GPU 和 DSP),并且提供了完整的工具链和文档,用户借助 MACE 能够很方便地在移动端部署深度学习模型。MACE 已经在小米内部广泛使用并且被充分验证具有业界领先的性能和稳定性
移动端模型部署框架 SNPE 特点?
- SNPE 是高通的一个神经网络框架,该平台具备普遍的异构计算功能,这些功能通过精心设计,能够在设备上运行通过训练的神经网络,而无需链接到云,参考:Qualcomm Neural Processing SDK for AI - Qualcomm Developer Network
- Qualcomm® 人工智能(AI)神经处理 SDK 旨在帮助开发人员在 Snapdragon 移动平台(不管是 CPU,GPU 仍是 DSP)上运行通过 Caffe / Caffe2,ONNX 或 TensorFlow 训练的一个或多个神经网络模型
移动端模型部署框架 FeatherCNN?
- 腾讯 AI 开源的移动端模型部署框架 基于 ARM 架构的高效 CNN 推理库,该项目支持 Caffe 模型,且具有高性能、易部署、轻量级三大特性,参考:GitHub - Tencent/FeatherCNN: FeatherCNN is a high performance inference engine for convolutional neural networks.
- 1)高性能:无论是在移动设备(iOS / Android),嵌入式设备(Linux)还是基于 ARM 的服务器(Linux)上,FeatherCNN 均能发挥最先进的推理计算性能;
- 2)易部署:FeatherCNN 的所有内容都包含在一个代码库中,以消除第三方依赖关系。因此,它便于在移动平台上部署。FeatherCNN 自身的模型格式与 Caffe 模型完全兼容。
- 3)轻量级:编译后的 FeatherCNN 库的体积仅为数百 KB
移动端模型部署框架 TensorFlow Lite 特点?
- 2017 年 11 月谷歌 tensorflow 嵌入式部署版本,是一种用于设备端推断的开源深度学习框架,该工具专一于模型优化和模型部署,使得 tensorflow 的整个生态更加完善,首先使用 tensorflow 训练好的模型,而后经过 tflite 进行模型加速,最终将其部署在 android 或者 ios 设备上 。参考:github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/lite
- TensorFlow Lite 可以与 Android 8.1 中发布的神经网络 API 完美配合,即便在没有硬件加速时也能调用 CPU 处理,确保模型在不同设备上的运行。 而 Android 端版本演进的控制权是掌握在谷歌手中的,从长期看,TensorFlow Lite 会得到 Android 系统层面上的支持
移动端模型部署框架 PocketFlow 特点?
- 2018 年 9 月腾讯提出的全球首个自动模型压缩框架,一款面向移动端 AI 开发者的自动模型压缩框架,集成了当前主流的模型压缩与训练算法,结合自研超参数优化组件实现了全程自动化托管式的模型压缩与加速,参考:GitHub - Tencent/PocketFlow: An Automatic Model Compression (AutoMC) framework for developing smaller and faster AI applications.
- 开发者无需了解具体算法细节,只须要指定所需的压缩比或加速比,而后 PocketFlow 将自动选择适当的超参数来生成高效的压缩模型以进行部署
模型压缩工具 model-compression?
- 是一个基于 Pytorch 的模型压缩工具,参考:GitHub - 666DZY666/micronet: micronet, a model compression and deploy lib. compression: 1、quantization: quantization-aware-training(QAT), High-Bit(>2b)(DoReFa/Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference)、Low-Bit(≤2b)/Ternary and Binary(TWN/BNN/XNOR-Net); post-training-quantization(PTQ), 8-bit(tensorrt); 2、 pruning: normal、regular and group convolutional channel pruning; 3、 group convolution structure; 4、batch-normalization fuse for quantization. deploy: tensorrt, fp32/fp16/int8(ptq-calibration)、op-adapt(upsample)、dynamic_shape
- 1)量化:任意位数 (16/8/4/2 bits)、三值 / 二值
- 2)剪枝:正常、规整、针对分组卷积结构的剪枝
- 3)分组卷积结构
- 4)针对特征 (A) 二值的 BN 融合
参考: