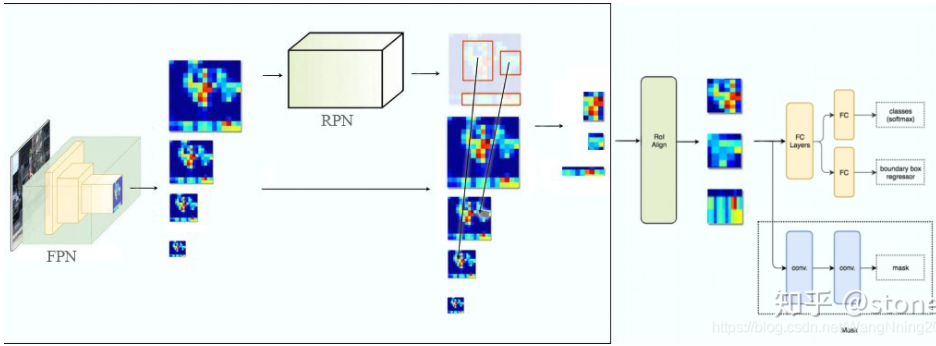
MaskRCNN
实例分割的第一个模型,创造性地结合 Faster RCNN 和 FCN,分别完成实例的定位、分类及 Mask 生成,同时为了解决 ROI Pooling 的量化误差问题,提出 ROI Align 替换
什么是 Mask RCNN?
![]()
- 在 FasterRCNN] 的基础上新增 FCN 分割模块,黑色部分为原来的 Faster-RCNN,红色部分为在 Faster 网络上的修改。
- 另一个改进是通过 ROIAlign 替换 Faster RCNN 的感兴趣区域池化 (RoIPooling),解决图像和网络输出的对齐问题,极大提升语义分割的效果
- 可以认为是目标检测 + 语义分割的结合,更具体一点就:RPN+ROIAlign+Fast RCNN+ FCN
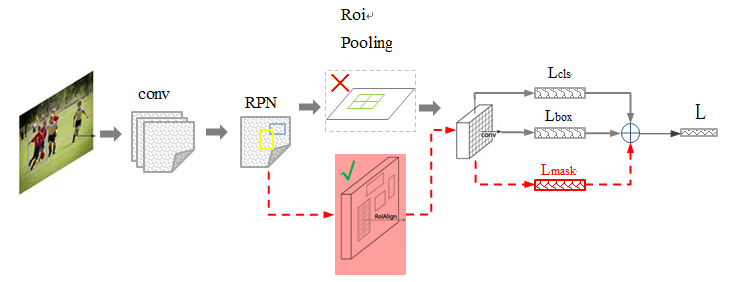
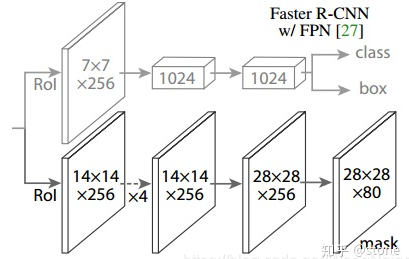
Mask RCNN 的网络结构?
![]()
骨干网络: 使用 ResNet + 特征金字塔网络 (FeaturePyramidNetwork, FPN) 提取多尺度的特征
感兴趣区域的池化: 采用 ROIAlign 而不是 Faster RCNN 的感兴趣区域池化 (RoIPooling)
box 分类与回归: FasterRCNN 一致
object mask: 使用 FCN
Mask RCNN 使用 FPN 生成多尺度的特征图,ROIAlign 使用哪个尺度的特征图?
- 假设 FPN 产生了特征金字 [P2, P3, P4, P5, P6],通过下列公式决定宽 w 和高 h 的 ROI 到底要从哪个 Pk 来切
- 其中 224 表示预训练 ImageNet 图片大小,k0 表示面积为 wxh=224x224 的 ROI 所在层级,论文将 k0 设置为 p4,如果 ROI 小于 224,比如说 122x122,则使用 k0-1=4-1=3 层特征池化
- 这种做法很合理,大尺度的 ROI 要从低分辨率的 feature map 上切,有利于检测大目标,小尺度的 ROI 要从高分辨率的 feature map 上切,有利于检测小目标
Mask RCNN 的损失函数?
- 总的损失函数
- 表示 bounding box 的分类损失值:使交叉熵损失 (CrossEntropyLoss)
- 表示 bounding box 的回归损失值:使平滑绝对值损失 (Smooth L1 Loss)
- 表示 mask 部分的损失值:使二值交叉熵损失 BCELoss ,该损失一般配合 sigmoid 函数使用
Mask RCNN 的训练过程?
- 主干网络部分:将图片送入到 CNN 特征提取网络得到特征图
- RPN 部分:对特征图的每一个像素位置设定固定个数的 ROI(Anchor),然后将 ROI 区域送入 RPN 网络进行二分类 (前景和背景) 以及坐标回归,以获得精炼后的 ROI 区域
- ROIAlign 部分:对获得的 ROI 区域执 ROIAlign 操作,即先将原图和 feature map 的 pixel 对应起来,然后将不同目标的 feature map 转为相同大小的 featrue
- 目标检测部分:对这些 ROI 区域进行多类别分类,得到预测的目标位置及类别
- 分割部分:最后目标检测得到的所有目标输入 FCN,得到每个目标的掩码预测结果
Mask RCNN 如何对目标进行分割预测?
![]()
- 经过 ROIAlign 获得 ROI 区域特征后,对每个像素进行分类,实现分割
Mask RCNN 如何进行关键点检测任务?
- 让 Mask RCNN 预测 k 个 mask,每个 mask 对应一个关键点类型,比如左肩、右肘,使用 cross entropy loss,鼓励网络只检测一个关键点
什么是 ROIAlign?
![MaskRCNN-20230408143911]()
- ROIPooling 和 RoIAlign 的目的都是为了获取目标定长的特征,都是经历:原图目标 -> 特征图区域 -> 池化特征 2 次映射过程
- ROIPooling:映射时经历两次取整,一次是目标 -> 特征图,一次是特征图 -> 池化,这样的操作对语义分割这种位置敏感的模型影响较大
- RoIAlign:映射时并没有取整的过程,可以全程使用浮点数操作,最后通双线性插值 (BilinearInterpolation) 计算浮点数位置的像素值 (特征值)
ROIAlign 如何计算池化结果?
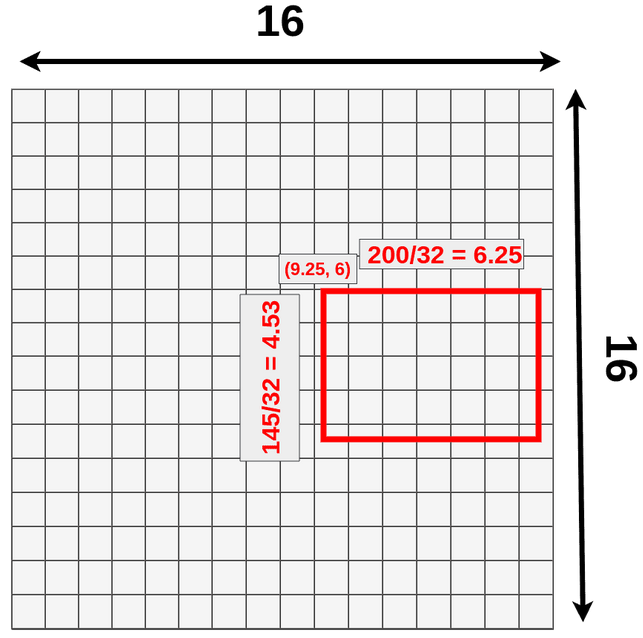
- 假设模型输入是:3x512x512,经过特征提取得到 512x16x16 的特征,即数据下采样 512/16=32 倍,现有目标位置 (192,296),大小 145x200
![]()
- ROI 映射: 计算得到该目标在特征图上位置为:(296/32=9.25, 192/32=6),大小为 (200/32=6.25, 145/32=4.53),ROIAlign 保留小数
![]()
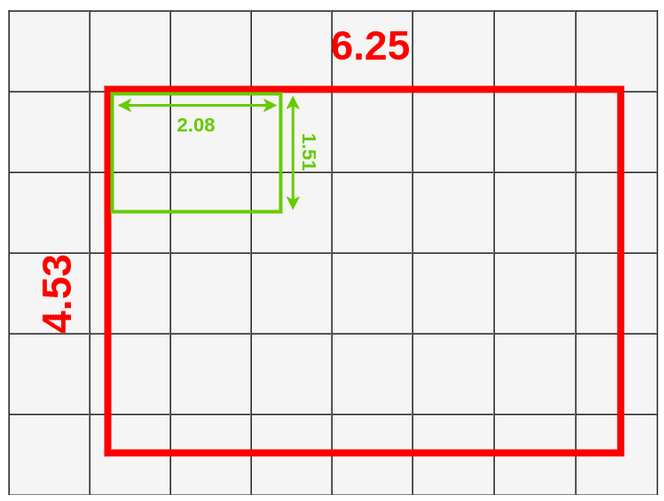
- 将 ROI 区域划分为大小相等的 9 个框,每个框的宽高为 (6.25,4.53)/3=(2.08,1.51)
![]()
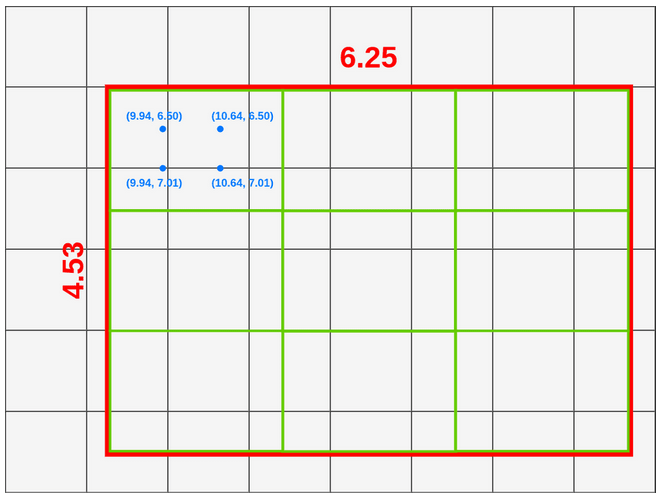
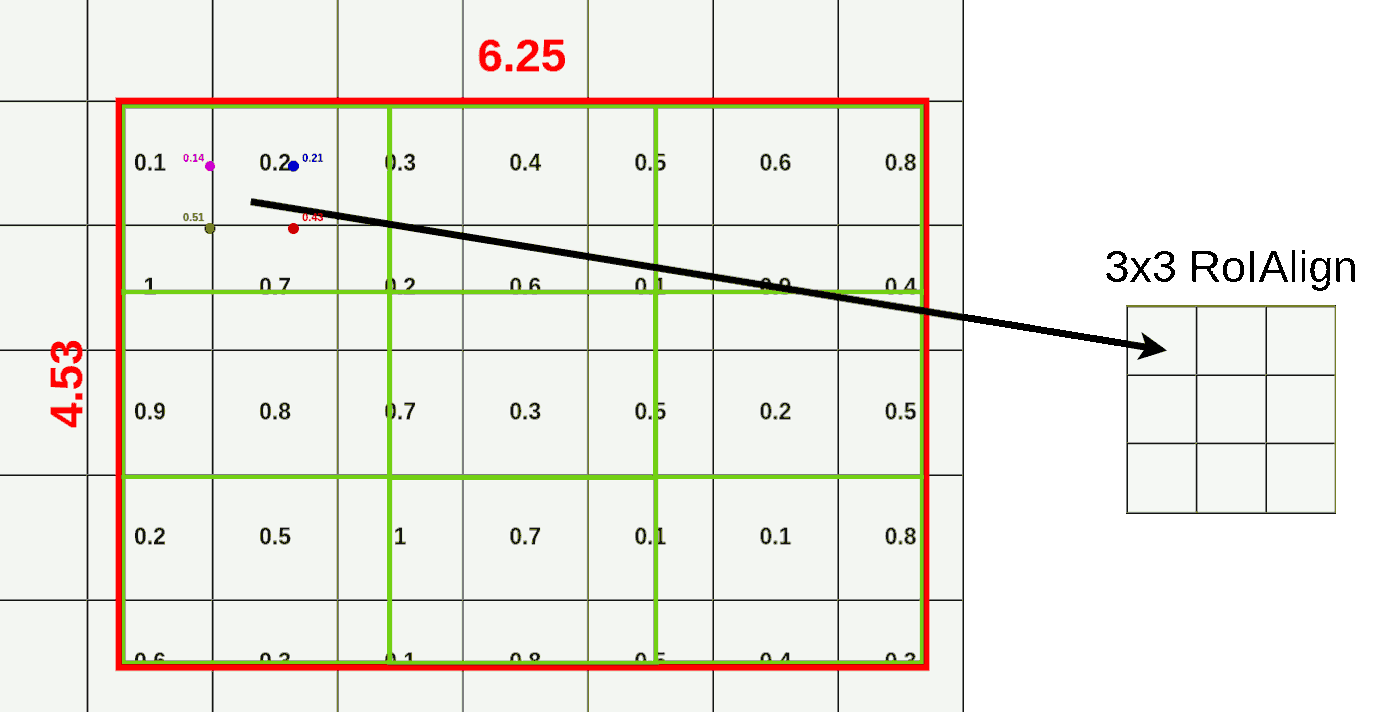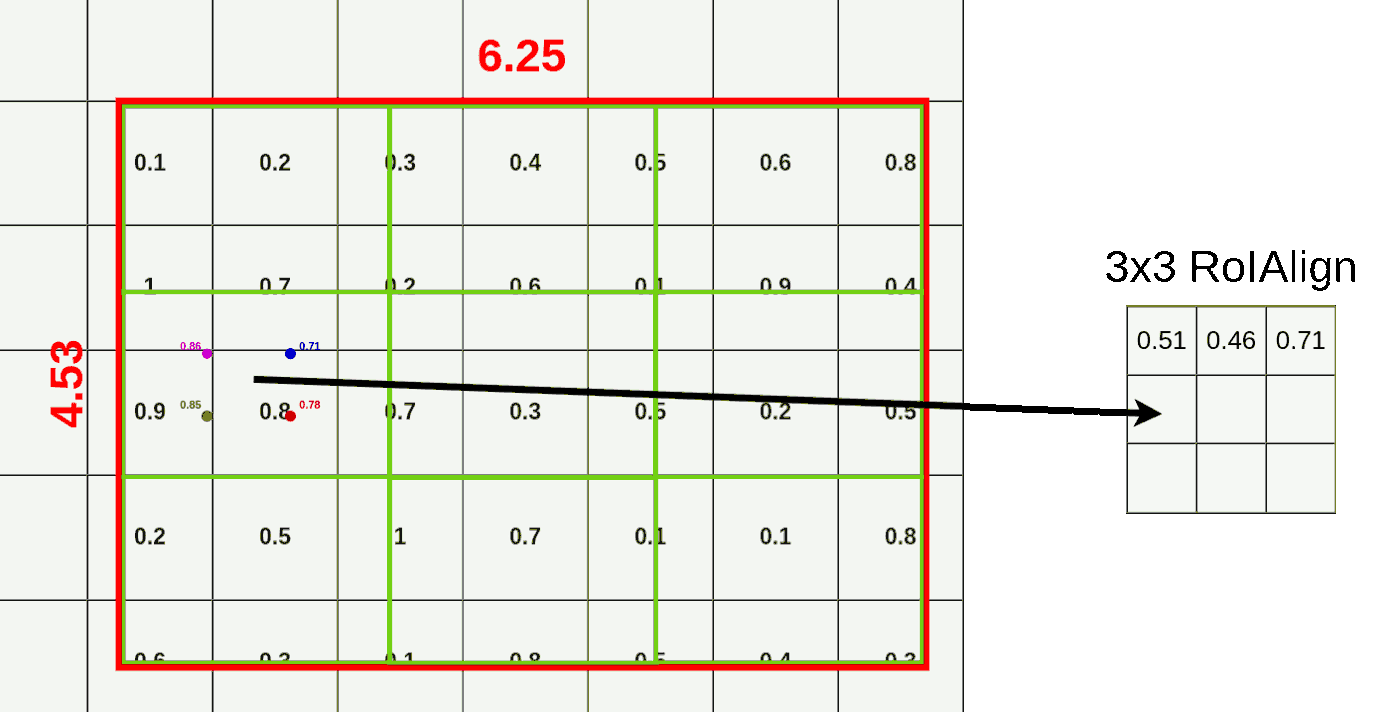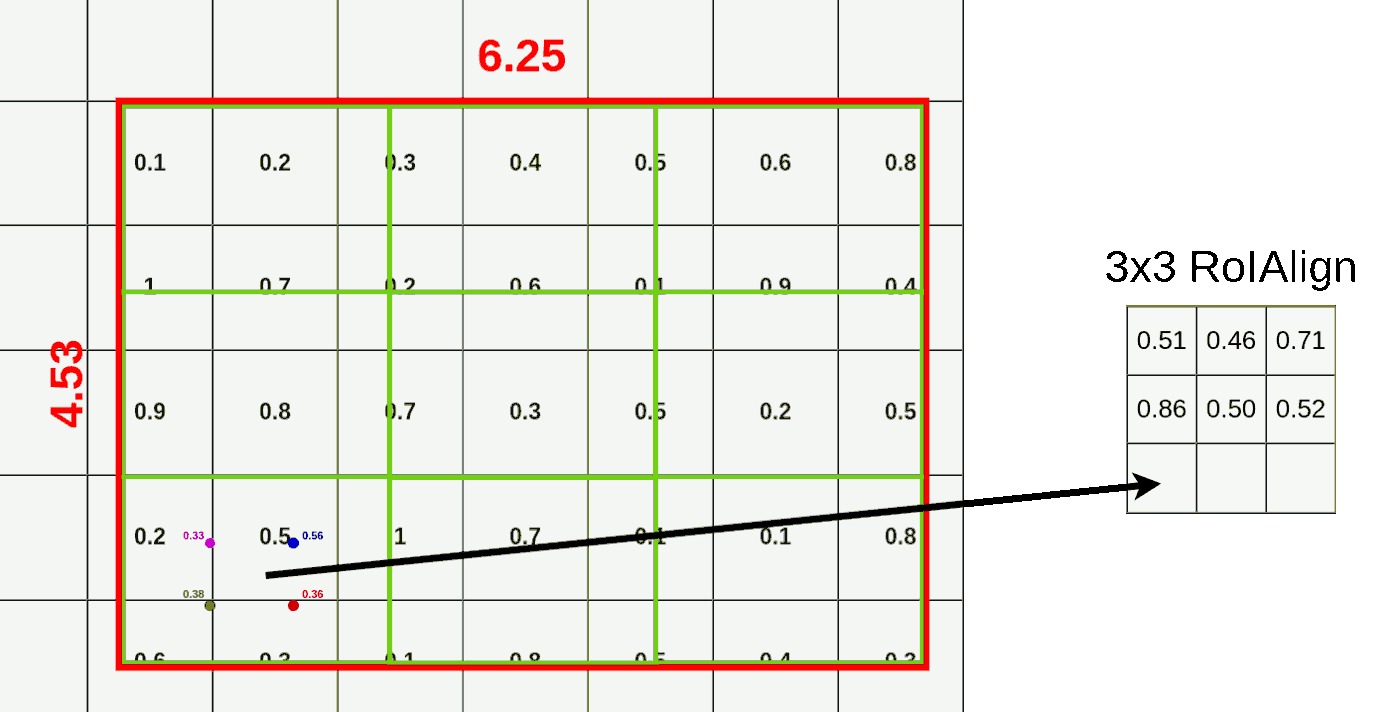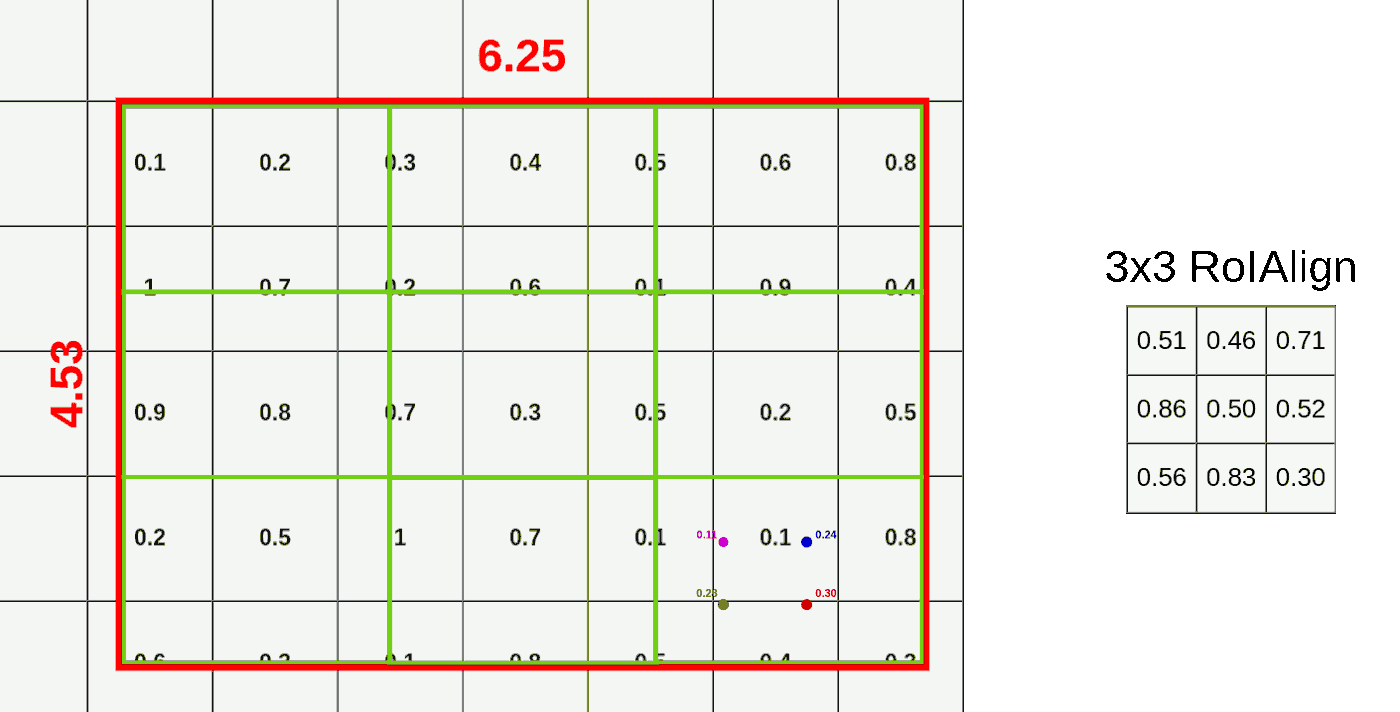
- 在每个框内取 4 个采样点,取样方法为将框横纵方向进行 3 等分,取框内的划分点作为采样点,如第一个点坐标 (X_box+(box_width/3) x1, Y_box+(box_height/3) x1)=(9.94, 6.50) 、第二个点坐标 (X_box+(box_width/3) x1, Y_box+(box_height/3) x2) =(9.94, 7.01)…
![]()
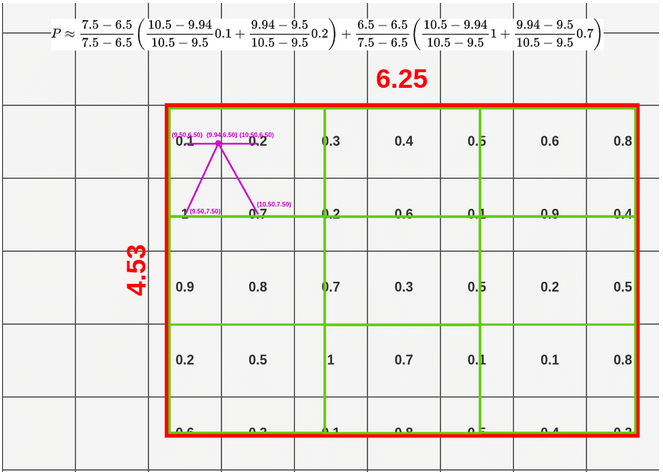
- 计算采样点的数值:按双线性插值 的原理,按照采样点与单元中心的距离计算采样点数值,依次计算采样点值
![]()
- ROI 区域池化:根据一个 bin 内的 4 个采样点,使用最大池化获得该区域的池化特征,依次使用上述方法计算,可以得到所有 bin 的池化结果
![]()
为什么在语义分割中使用 ROIAlign,而不使用 ROIPool?
![]()
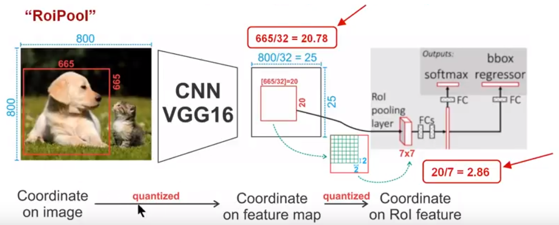
- 如图所示,这是一个 Faster-RCNN 检测框架。输入一张 的图片,图片上有一个 的包围框(框着一只狗)
- 第一次量化: 图片经过主干网络提取特征后,特征图缩放步长(stride)为 32。因此,图像和包围框的边长都是输入时的 1/32。800 正好可以被 32 整除变为 25。但 665 除以 32 以后得到 20.78,带有小数,于是 RoI Pooling 直接将它量化成 20
- 第二次量化: 接下来需要把框内的特征池化 的大小,因此将上述包围框平均分割成 个矩形区域。显然,每个矩形区域的边长为 2.86,又含有小数。于是 ROI Pooling 再次把它量化到 2
- 经过这两次量化,候选区域已经出现了较明显的偏差(如图中绿色部分所示),更重要的是,该层特征图上 0.1 个像素的偏差,缩放到原图就是 3.2 个像素。那么 0.8 的偏差,在原图上就是接近 30 个像素点的差别,这一差别不容小觑
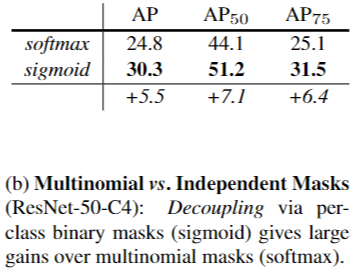
Mask RCNN 目标分类为什么不使用类别竞争机制 (softmax)?
![MaskRCNN-20230408143914-1]()
- 使用 sigmoid (二分类) 和使用 softmax (多类别分类) 的 AP 相差很大,证明了分离类别和 mask 的预测是很有必要的
- 假设 FPN 产生了特征金字 [P2, P3, P4, P5, P6],通过下列公式决定宽 w 和高 h 的 ROI 到底要从哪个 Pk 来切