Pytorch 模型训练
Pytorch 的训练方式及进行分布式训练的原理、步骤,最后讲解如何进行混合精度训练
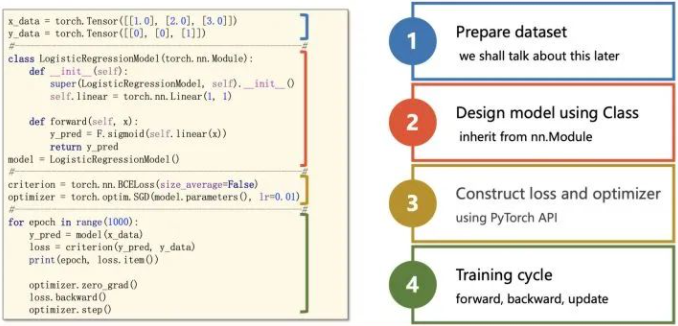
Pytorch 如何从零开始训练模型?
![]()
- 准备数据: 初始化 Pytorch 的数据加载器 DataLoader
- 准备模型: 定义一个网络结构
- 准备损失函数及优化器: 根据模型输出及标签计算损失函数,选择优化器
- 循环训练模型: Pytorch 迭代训练模型
Pytorch 如何对不同层的学习设置不同的学习率变化方式?
- 将优化器中的学习率设为两组(两种)
1
2
3
4optimizer = torch.optim.SGD(params=[ # 初始化优化器,并设置两个param_groups
{'params': model.layer2.parameters()},
{'params': model.layer3.parameters(), 'lr':0.2},
], lr=0.1) # base_lr = 0.1 - 使用 torch. Optim. Lr_scheduler. LambdaLR 为每组参数设置学习率变化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 设置warm up的轮次为100次
warm_up_iter = 10
T_max = 50 # 周期
lr_max = 0.1 # 最大值
lr_min = 1e-5 # 最小值
# 为param_groups[0] (即model.layer2) 设置学习率调整规则 - Warm up + Cosine Anneal
lambda0 = lambda cur_iter: cur_iter / warm_up_iter if cur_iter < warm_up_iter else \
(lr_min + 0.5*(lr_max-lr_min)*(1.0+math.cos( (cur_iter-warm_up_iter)/(T_max-warm_up_iter)*math.pi)))/0.1
# param_groups[1] 不进行调整
lambda1 = lambda cur_iter: 1
# LambdaLR
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=[lambda0, lambda1])
for epoch in range(50):
print(optimizer.param_groups[0]['lr'], optimizer.param_groups[1]['lr'])
optimizer.step()
scheduler.step()
Pytorch 迭代训练模型的步骤?
- 1. 获取数据: 从 DataLoader 获取一批训练数据
- 2. 梯度归零: 将优化器的梯度归零
- 3. 执行推理: 即从模型中获取输入批次的预测
- 4. 计算损失: 计算该组预测与数据集上的标签的损失
- 5. 后向梯度: 计算学习权重的后向梯度
- 6. 梯度更新: 告诉优化器执行一个学习步骤,即根据我们选择的优化算法,根据观察到的该批次的梯度调整模型的学习权重
Pytorch 运行时,提升性能的技巧?
- 在 torch.utils.data.DataLoader 中使用 worker,但这会使内存使用量也会增加
- 在 torch.utils.data.DataLoader 中使用 pinned_memory,减少数据拷贝,详细参考:Pytorch 的 Dataloader 的参数 pin_memory=True 加速训练的原理?
- 避免 CPU 到 GPU 的传输,大量使用 .item () 或 .cpu () 或 .numpy () 调用。这对性能非常不利,因为这些调用中的每一个都将数据从 GPU 传输到 CPU,如果您尝试清除附加的计算图,请改用 .detach ()
- 使用 torch.nn.parallel.DistributedDataParallel 而不是 torch.nn.DataParallel
- 使用 16 位精度,模型权重及输入数据改为 float16
深度学习的大规模分布式训练技术种类?
- Data Parallelism (数据并行): 将大 batch 划分为若干小 barch 分发到不同 device 并行计算,解决单 GPU 显存不足的限制
- Model/Pipeline Parallelism (模型并行): 当单 GPU 无法放下整个模型时,我们还需考虑模型并行 (Model/PipelineParallelism)。如考虑将模型进行纵向切割,不同的 Layers 放在不同的 device 上。或是将某些模块进行横向切割,通过矩阵运算进行加速
- Non-parallelism approach (非并行技术): 一些非并行的技术或者技巧,用于解决训练效率或者训练显存不足等问题
什么是数据并行(Data Parallelism)分布式训练?
- 数据并行 (DataParallelism) 技术,其核心思想是将大 batch 划分为若干小 barch 分发到不同 device 并行计算,解决单 GPU 显存不足的限制
- 每个 worker 存储一份 model 和 optimizer,每轮迭代时,将样本分为若干份分发给各个 worker,实现并行计算.Pytorch 使用 torch.nn.DataParallel 进行分布式训练
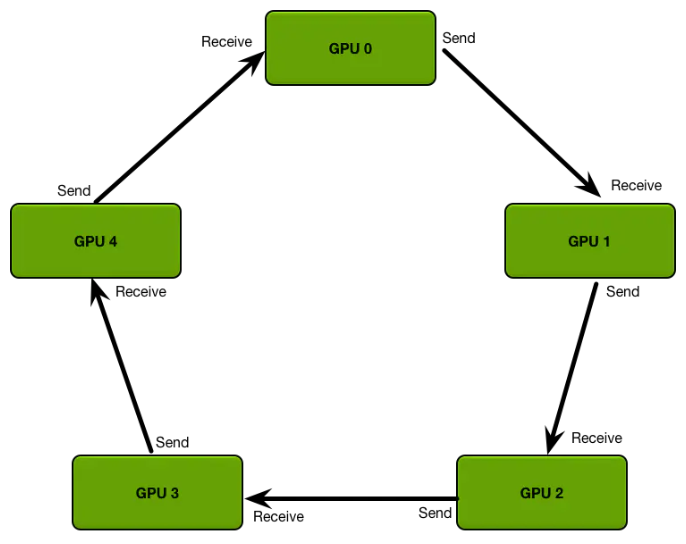
什么是 RingAllReduce 架构?
![]()
- 早期的 TensorFlow 使用的是 PS (ParameterServer) 架构,在结点数量线性增长的情况下,带宽瓶颈格外明显。而随后百度将 Ring-Allreduce 技术运用到深度学习分布式训练,PyTorch 1.0 之后香起来的原因也是因为在分布式训练方面做了较大改动,适配多种通信后端,使用 RingAllReduce 架构
- 每个 GPU 只从左邻居接受数据、并发送数据给右邻居,包括 2 个步骤:(1)scatter-reduce:会逐步交换彼此的梯度并融合,最后每个 GPU 都会包含完整融合梯度的一部分;(2)allgather:GPU 会逐步交换彼此不完整的融合梯度,最后所有 GPU 都会得到完整的融合梯度
Pytorch 如何进行单机单卡训练?
- 默认训练方式就是单机单卡进行的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36# 1. define network
device = "cuda"
net = torchvision.models.resnet18(num_classes=10)
net = net.to(device=device)
# 2. define dataloader
trainset = torchvision.datasets.CIFAR10(root="./data",train=True,download=True,
transform=transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
]
),)
train_loader = torch.utils.data.DataLoader(trainset,batch_size=BATCH_SIZE,shuffle=True,num_workers=4,pin_memory=True)
# 3. define loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(),lr=0.01,momentum=0.9,weight_decay=0.0001,nesterov=True)
print(" ======= Training ======= \n")
# 4. start to train
net.train()
for ep in range(1, EPOCHS + 1):
train_loss = correct = total = 0
for idx, (inputs, targets) in enumerate(train_loader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = net(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
total += targets.size(0)
correct += torch.eq(outputs.argmax(dim=1), targets).sum().item()
if (idx + 1) % 50 == 0 or (idx + 1) == len(train_loader):
print(" == step: [{:3}/{}] [{}/{}] | loss: {:.3f} | acc: {:6.3f}%".format(
idx + 1,len(train_loader),ep,EPOCHS,train_loss / (idx + 1),100.0 * correct / total,)
)
print("\n ======= Training Finished ======= \n")
Pytorch 如何进行单机多卡训练(DP)?
- 用 torch. Nn. DataParallel 包装模型,再设置一些参数即可。需要定义的参数包括:参与训练的 GPU 有哪些,device_ids=gpus;用于汇总梯度的 GPU 是哪个,output_device=gpus [0] 。DataParallel 会自动帮我们将数据切分 load 到相应 GPU,将模型复制到相应 GPU,进行正向传播计算梯度并汇总
- 事实上,DataParallel 也是一个 Pytorch 的 nn. Module,
model = nn.DataParallel(model)表示将 model 赋值给 DataParallel 类的 module 变量,所以访问权重或者设置优化器学习率时,需要加 module1
2
3
4
5
6
7
8# 保存模型
torch.save(net.module.state_dict(), path)
# 加载模型
net=nn.DataParallel(Resnet18())
net.load_state_dict(torch.load(path))
net=net.module
# 优化器使用
optimizer.step() --> optimizer.module.step() - 注意:因为 GIL 锁的限制,DP 的性能是低于 DDP 的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# main.py
import torch
import torch.distributed as dist
gpus = [0, 1, 2, 3]
torch.cuda.set_device('cuda:{}'.format(gpus[0]))
train_dataset = ...
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=...)
model = ...
model = nn.DataParallel(model.to(device), device_ids=gpus, output_device=gpus[0])
optimizer = optim.SGD(model.parameters())
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
# --------------运行方式--------------------
python main.py
单机多卡训练(DP)的原理?
- torch.nn.DataParallel 也是一个 nn.Moudule 类,其核心代码如下:
1
2
3
4inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)
replicas = self.replicate(self.module, self.device_ids[:len(inputs)])
outputs = self.parallel_apply(replicas, inputs, kwargs)
return self.gather(outputs, self.output_device) - 以上代码分别表示的含义时:(1) 把数据平均分为 N 份;(2) 把模型参数复制 N 份;(3) 在 N 个 GPU 上同时运算;(4) 回收 N 个 GPU 的运算结果
Pytorch 如何进行多机多卡训练(DDP)?
- 使用 torch.nn.parallel.DistributedDataParallel 时,将模型和数据加载到多个 GPU 中,依靠多进程来实现控制数据在 GPU 之间的流动,协同不同 GPU 上的模型进行并行训练
- DDP 支持单机多卡和多机多卡,和 DP 只有一个主进程不一样,DDP 每张卡都有一个进程,这就涉及到多进程通信
- 注意:(1)如果训练从随机参数开始,则可能要确保所有 DDP 进程都使用相同的初始值。否则,全局梯度同步将没有意义; (2)由于各个进程模型初始化相同、执行相同的梯度更新,所以各个进程的模型参数永远是相同的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55# 0. set up distributed device
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
torch.cuda.set_device(rank % torch.cuda.device_count())
dist.init_process_group(backend="nccl")
device = torch.device("cuda", local_rank)
print(f"[init] == local rank: {local_rank}, global rank: {rank} ==")
# 1. define network
net = torchvision.models.resnet18(pretrained=False, num_classes=10)
net = net.to(device)
# DistributedDataParallel
net = DDP(net, device_ids=[local_rank], output_device=local_rank)
# 2. define dataloader
trainset = torchvision.datasets.CIFAR10(
root="./data",
train=True,
download=False,
transform=transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)
),
]
))
# DistributedSampler
# we test single Machine with 2 GPUs
# so the [batch size] for each process is 256 / 2 = 128
train_sampler = torch.utils.data.distributed.DistributedSampler(trainset,shuffle=True,)
train_loader = torch.utils.data.DataLoader(trainset,batch_size=BATCH_SIZE,num_workers=4,pin_memory=True,sampler=train_sampler)
# 3. define loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(),lr=0.01 * 2,momentum=0.9,weight_decay=0.0001,nesterov=True)
if rank == 0:
print(" ======= Training ======= \n")
# 4. start to train
net.train()
for ep in range(1, EPOCHS + 1):
train_loss = correct = total = 0
# set sampler
train_loader.sampler.set_epoch(ep)
for idx, (inputs, targets) in enumerate(train_loader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = net(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
total += targets.size(0)
correct += torch.eq(outputs.argmax(dim=1), targets).sum().item()
if rank == 0 and ((idx + 1) % 25 == 0 or (idx + 1) == len(train_loader)):
print(" == step: [{:3}/{}] [{}/{}] | loss: {:.3f} | acc: {:6.3f}%".format(
idx + 1,len(train_loader),ep,EPOCHS,train_loss / (idx + 1),100.0 * correct / total))
if rank == 0:
print("\n ======= Training Finished ======= \n")
多机多卡训练(DDP)的训练步骤?
- (1)各进程的模型进行初始化时执行一次 broadcast 保证各进程模型初始参数一致
- (2)每个进程读取不同的数据进行前向传播,并计算得到 loss 和梯度
- (3)将梯度汇总并求平均,broadcast 到其他进程
- (4)各个进程执行完整的反向传播更新参数
Pytorch 的 DP 与 DDP 的区别?
- DP 只用于单机多卡,DDP 可以用于单机多卡也可用于多机多卡,后者现在是 Pytorch 分布式训练的主流用法。DP 写法比较简单,但即使在单机多卡情况下也比 DDP 慢
- DataParallel 是单进程,多线程,并且只能在单台计算机上运行,而 DistributedDataParallel 是多进程,并且可以在单机和分布式训练中使用
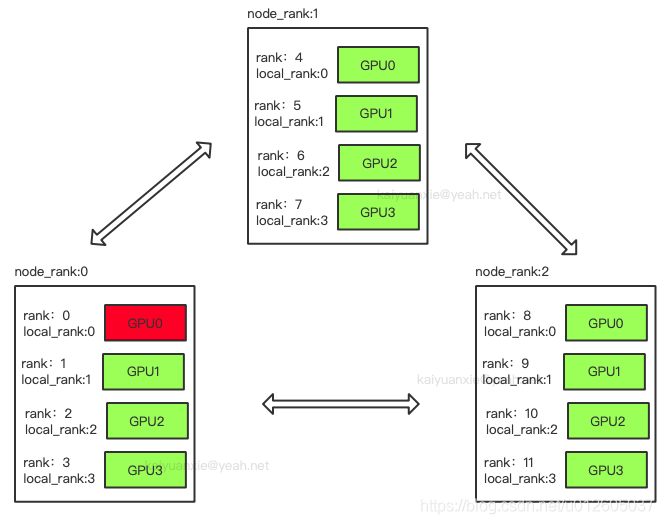
Pytorch 的 DDP 涉及的进程概念?
![]()
- GROUP:进程组,一个分布式任务对应了一个进程组。只有用户需要创立多个进程组时才会用到 group 来管理,默认情况下只有一个 group
- rank: 用于表示进程的编号 / 序号,每一个进程对应了一个 rank 的进程,整个分布式由许多 rank 完成
- node: 物理节点,可以是一台机器也可以是一个容器,节点内部可以有多个 GPU
- node_rank: 物理节点的序号
- nproc_per_node:指每个物理节点上面进程的数量
- local_rank:某个节点上的进程 id
- word size:全局(一个分布式任务)中,rank 的数量
- local_word_size:某个节点上的进程数
如何使用 torch. distributed. init_process_group 初始化进程组?
- 指定 DDP 通讯后端 (backennd) : torch 提供了三种可用的后端,这三类支持的分布式操作有所不同,因此选择的时候,需要考虑具体的场景,CPU 的分布式训练选择 GLOO,GPU 的分布式训练就用 NCCL 即可
- 指定初始化方法 (init_method):(1) 显式指定,可以是 TCP 连接、File 共享文件系统、ENV 环境变量三种方式;(2)显式指定,同时指定 world_size 和 rank 参数
- init_method=‘tcp://ip:port’: 通过指定 rank 0(即:MASTER 进程)的 IP 和端口,各个进程进行信息交换。 需指定 rank 和 world_size 这两个参数
- init_method=‘file 😕/path’: 通过所有进程都可以访问共享文件系统来进行信息共享。需要指定 rank 和 world_size 参数
- init_method=env://:从环境变量中读取分布式的信息 (os.environ),主要包括 。 其中,rank 和 world_size 可以选择手动指定,否则从环境变量读取。MASTER_ADDR, MASTER_PORT, RANK, WORLD_SIZE
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import os, argparse
import torch
import torch.distributed as dist
parse = argparse.ArgumentParser()
parse.add_argument('--init_method', type=str)
parse.add_argument('--rank', type=int)
parse.add_argument('--ws', type=int)
args = parse.parse_args()
# torch.distributed.init_process_group(backend, init_method=None, world_size=-1, rank=-1, store=None,...)
if args.init_method == 'TCP':
dist.init_process_group('nccl', init_method='tcp://127.0.0.1:28765', rank=args.rank, world_size=args.ws)
elif args.init_method == 'ENV':
dist.init_process_group('nccl', init_method='env://')
rank = dist.get_rank()
# 单机多卡情况下,localrank = rank. 严谨应该是local_rank来设置device
torch.cuda.set_device(rank)
tensor = torch.tensor([1, 2, 3, 4]).cuda()
print(tensor)
#-------------------启动命令----------------------
# TCP方法
python3 test_ddp.py --init_method=TCP --rank=0 --ws=2
python3 test_ddp.py --init_method=TCP --rank=1 --ws=2
# ENV方法
MASTER_ADDR='localhost' MASTER_PORT=28765 RANK=0 WORLD_SIZE=2 python3 test_gpu.py --init_method=ENV
MASTER_ADDR='localhost' MASTER_PORT=28765 RANK=1 WORLD_SIZE=2 python3 test_gpu.py --init_method=ENV
如何使用 torch.nn.parallel.DistributedDataParallel 创建分布式模型?
- 和 nn.DataParallel 的方式一样,DDP 模型的初始化一句话,它能帮助我们为不同 GPU 上求得的梯度进行 allreduce(即汇总不同 GPU 计算所得的梯度,并同步计算结果)。allreduce 后不同 GPU 中模型的梯度均为 allreduce 之前各 GPU 梯度的均值
- 注意:在 save 和 load 模型时候,为了减小所有进程同时读写磁盘,一般处理方法是以主进程为主,rank0 先 save 模型,在 map 到其他进程。这样的另外一个好处,在最开始训练时,模型随机初始化之后,保证了所有进程的模型参数保持一致
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20torch.cuda.set_device(local_rank)
model = Model().cuda()
model = DistributedDataParallel(model, device_ids=[local_rank])
CHECKPOINT_PATH ="./model.checkpoint"
if rank == 0:
torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)
# barrier()其他保证rank 0保存完成
dist.barrier()
map_location = {"cuda:0": f"cuda:{local_rank}"}
model.load_state_dict(torch.load(CHECKPOINT_PATH, map_location=map_location))
# 后面正常训练代码
optimizer = xxx
for epoch:
for data in Dataloader:
model(data)
xxx
# 训练完成 只需要保存rank 0上的即可
# 不需要dist.barrior(), all_reduce 操作保证了同步性
if rank == 0:
torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)
如何使用 torch.utils.data.distributed.DistributedSampler 创建 DataLoader?
- 分布式训练数据加载时,Dataloader 需要把所有数据分成 N 份 (N 为 worldsize), 并能正确的分发到不同的进程中,每个进程可以拿到一个数据的子集,不重叠,不交叉。这部分工作靠 DistributedSampler 完成
1
2
3
4
5sampler = DistributedSampler(dataset)
loader = DataLoader(dataset, sampler=sampler)
for epoch in range(start_epoch, n_epochs):
sampler.set_epoch(epoch) # 设置epoch 更新种子
train(loader)
Pytorch DDP 程序的不同启动方式?
- 默认方式:使用环境变量配置各类参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import os, argparse
import torch
import torch.distributed as dist
parse = argparse.ArgumentParser()
parse.add_argument('--init_method', type=str)
parse.add_argument('--rank', type=int)
parse.add_argument('--ws', type=int)
args = parse.parse_args()
# ....
#-------------------启动命令----------------------
# TCP方法
python3 test_ddp.py --init_method=TCP --rank=0 --ws=2
python3 test_ddp.py --init_method=TCP --rank=1 --ws=2
# ENV方法
MASTER_ADDR='localhost' MASTER_PORT=28765 RANK=0 WORLD_SIZE=2 python3 test_gpu.py --init_method=ENV
MASTER_ADDR='localhost' MASTER_PORT=28765 RANK=1 WORLD_SIZE=2 python3 test_gpu.py --init_method=ENV - mp.spawn : 使用(python 的的封装类) 来自动生成多个进程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def fn(rank, ws, nums):
dist.init_process_group('nccl', init_method='tcp://127.0.0.1:28765',
rank=rank, world_size=ws)
rank = dist.get_rank()
print(f"rank = {rank} is initialized")
torch.cuda.set_device(rank)
tensor = torch.tensor(nums).cuda()
print(tensor)
if __name__ == "__main__":
ws = 2
mp.spawn(fn, nprocs=ws, args=(ws, [1, 2, 3, 4]))
#-------------------启动命令----------------------
# python3 test_ddp.py - launch/run :torch 提供的工具,可以以模块的形式直接执行:torch.distributed.launch
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import os
dist.init_process_group('nccl', init_method='env://')
rank = dist.get_rank()
local_rank = os.environ['LOCAL_RANK']
master_addr = os.environ['MASTER_ADDR']
master_port = os.environ['MASTER_PORT']
print(f"rank = {rank} is initialized in {master_addr}:{master_port}; local_rank = {local_rank}")
torch.cuda.set_device(rank)
tensor = torch.tensor([1, 2, 3, 4]).cuda()
print(tensor)
#-------------------启动命令----------------------
# python3 -m torch.distribued.launch --nproc_per_node=2 test_ddp.py
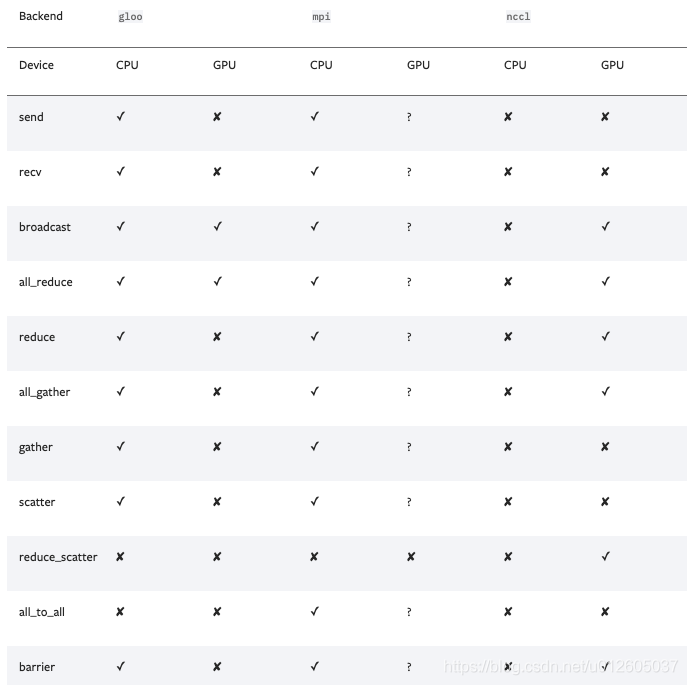
Pytorch 的 DDP 通讯后端 (backennd)?
![]()
- 通讯后端 (backennd) 可选的包括:nccl(NVIDIA 推出)、gloo(Facebook 推出)、mpi(OpenMPI)。从测试的效果来看,如果显卡支持 nccl,建议后端选择 nccl,,其它硬件(非 N 卡)考虑用 gloo、mpi(OpenMPI)
- 通信过程主要是完成模型训练过程中参数信息的传递,如算 accuracy 或者总 loss 时候需要用到 allreduce,主要考虑通信后端和通信模式选择,后端与模式对整个训练的收敛速度影响较大,相差可达 2~10 倍
为什么程序里面的进程用 rank 表示而不用 proc 表示?
什么是 Apex?
- Apex 是 NVIDIA 开源的用于混合精度训练和分布式训练库。Apex 对混合精度训练的过程进行了封装,改两三行配置就可以进行混合精度的训练,从而大幅度降低显存占用,节约运算时间
- 在分布式训练的封装上,Apex 在胶水层的改动并不大,主要是优化了 NCCL 的通信。因此,大部分代码仍与 torch.distributed 保持一致。使用的时候只需要将 torch.nn.parallel.DistributedDataParallel 替换为 apex.parallel.DistributedDataParallel 用于包装模型
第三方分布式训练库 Horovod?
- Horovod 是 Uber 开源的深度学习工具,它的发展吸取了 Facebook"TrainingImageNetIn1Hour" 与百度 "RingAllreduce" 的优点,可以无痛与 PyTorch/Tensorflow 等深度学习框架结合,实现并行训练
- 与 torch.distributed.launch 相似,我们只需要编写一份代码,horovodrun 启动器就会自动将其分配给个进程,分别在个 GPU 上运行。在执行过程中,启动器会将当前进程的(其实就是 GPU 的)index 注入 hvd
第三方分布式训练库 Accelerator?
- huggingface 发布的 Accelerator,专门适用于 Pytorch 的分布式训练框架
什么是 Slurm?
- Slurm,是一个用于 Linux 系统的免费、开源的任务调度工具。它提供了三个关键功能。第一,为用户分配资源 (计算机节点),以供用户执行工作。第二,它提供了一个框架,用于执行在节点上运行着的任务 (通常是并行的任务),第三,为任务队列合理地分配资源
- 通过运行 slurm 的控制命令,slurm 会将写好的 python 程序在每个节点上分别执行,调用节点上定义的 GPU 资源进行运算
如何进行分布式 evaluation?
- torch.utils.data.distributed.DistributedSampler 能够帮助我们分发数据,torch.nn.parallel.DistributedDataParallel、hvd.broadcast_parameters 能够帮助我们分发模型,并在框架的支持下解决梯度汇总和参数更新的问题
- 使用分布式做 evaluation 的时候,一般需要先所有进程的输出结果进行 gather,再进行指标的计算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23import torch
import torch.distributed as dist
dist.init_process_group('nccl', init_method='env://')
rank = dist.get_rank()
torch.cuda.set_device(rank)
tensor = torch.arange(2) + 1 + 2 * rank
tensor = tensor.cuda()
print(f"rank {rank}: {tensor}")
tensor_list = [torch.zeros_like(tensor).cuda() for _ in range(2)]
dist.all_gather(tensor_list, tensor)
print(f"after gather, rank {rank}: tensor_list: {tensor_list}")
dist.barrier()
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
print(f"after reduce, rank {rank}: tensor: {tensor}")
# ------------------命令------------------------
torchrun --nproc_per_node=2 test_ddp.py
# ------------------输出------------------------
rank 1: tensor([3, 4], device='cuda:1')
rank 0: tensor([1, 2], device='cuda:0')
after gather, rank 1: tensor_list: [tensor([1, 2], device='cuda:1'), tensor([3, 4], device='cuda:1')]
after gather, rank 0: tensor_list: [tensor([1, 2], device='cuda:0'), tensor([3, 4], device='cuda:0')]
after reduce, rank 0: tensor: tensor([4, 6], device='cuda:0')
after reduce, rank 1: tensor: tensor([4, 6], device='cuda:1')
什么是 torch.distributed.reduce?
![]()
1
torch.distributed.reduce(tensor, dst, op=, group=None, async_op=False)
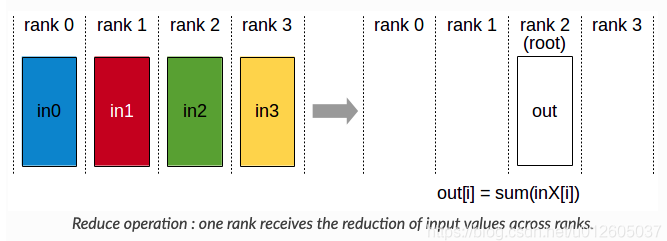
什么是 torch.distributed.all_reduce?
![]()
- 将不同 rank 进程的数据进行操作。比如 sum 操作
![]()
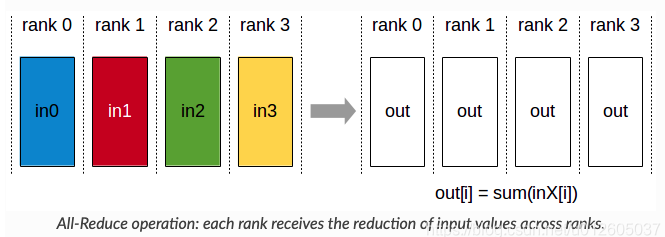

什么是 torch.distributed.all_gather?
![]()
- 对所有的进程进行同步,比如利用 rank0 进行数据的拷贝,而其他进程等待 rank0 完成操作
![]()
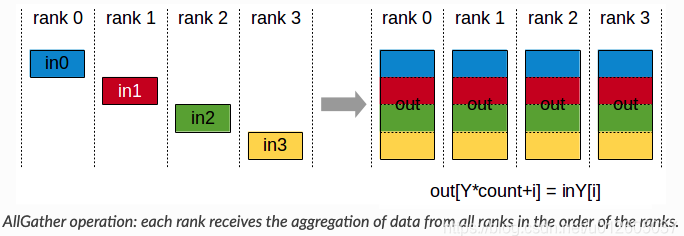

torch.distributed.barrier 的作用?
- 多卡数据分配的处理由 torch.utils.data.distributed.DistributedSampler 完成,但有一些其他任务并没有这么方便的接口来处理多进程的同步问题。一个经典的例子是:很多操作只需要在 worker0 上执行一遍,其他 worker 来取 worker0 的结果就行,比如说预训练模型下载、数据集检查。
- torch.distributed.barrier () 提供了很方便的、类似于 p.join () 的同步手段:每当进程执行到 torch.distributed.barrier () 时,该进程会保持阻塞,直至所有进程都执行到了这句话
分布式训练下 checkpoint 的保存与加载?
- 保存: 一般情况下,我们只需要保存一份 ckpt 即可。 可以用 rank 来指定一个进程保存
- 加载: 加载不同于保存,可以让每个进程独立的加载,也可以让某个 rank 加载后然后进行广播。 值得注意的是,当模型大的情况下,独立加载最好将模型映射到 cpu 上,不然容易出现加载模型 的 OOM
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38def demo_checkpoint(rank, world_size):
setup(rank, world_size)
# setup devices for this process, rank 1 uses GPUs [0, 1, 2, 3] and
# rank 2 uses GPUs [4, 5, 6, 7].
n = torch.cuda.device_count() // world_size
device_ids = list(range(rank * n, (rank + 1) * n))
model = ToyModel().to(device_ids[0])
# output_device defaults to device_ids[0]
ddp_model = DDP(model, device_ids=device_ids)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
CHECKPOINT_PATH = tempfile.gettempdir() + "/model.checkpoint"
if rank == 0:
# All processes should see same parameters as they all start from same
# random parameters and gradients are synchronized in backward passes.
# Therefore, saving it in one process is sufficient.
torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)
# Use a barrier() to make sure that process 1 loads the model after process
# 0 saves it.
dist.barrier()
# configure map_location properly
rank0_devices = [x - rank * len(device_ids) for x in device_ids]
device_pairs = zip(rank0_devices, device_ids)
map_location = {'cuda:%d' % x: 'cuda:%d' % y for x, y in device_pairs}
ddp_model.load_state_dict(
torch.load(CHECKPOINT_PATH, map_location=map_location))
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(device_ids[0])
loss_fn = nn.MSELoss()
loss_fn(outputs, labels).backward()
optimizer.step()
# Use a barrier() to make sure that all processes have finished reading the
# checkpoint
dist.barrier()
if rank == 0:
os.remove(CHECKPOINT_PATH)
cleanup()
多卡后的 batch_size 和 learning_rate 的调整?
- 从理论上来说,lr=batch_sizexbaselr,因为 batch_size 的增大会导致你 update 次数的减少,所以为了达到相同的效果,应该是同比例增大的。但是更大的 lr 可能会导致收敛的不够好,尤其是在刚开始的时候,如果你使用很大的 lr,可能会直接爆炸,所以可能会需要一些 warmup 来逐步的把 lr 提高到你想设定的 lr
- 实际应用中发现不一定要同比例增长,有时候可能增大到 batch_size/2 倍的效果已经很不错了。在我的实验中,使用 8 卡训练,则增大 batch_size8 倍,learning_rate4 倍是差不多的
什么是 SyncBN?
- 多卡 BN 在默认情况下计算单张卡下的 mean 和 var,并在单张卡下维护自己的 BN 参数。解决办法有 SyncBN 与 GruopNormalization
- SyncBN 完成 BN 以尽可能模拟单卡场景,尽管会降低 GPU 利用率,但可以提高模型在多卡场景下的表现
1
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
Pytorch 实现指数移动平均(EMA)?
- 指数加权平均 (exponentially weighted averges) 是一种给予近期数据更高权重的平均方法,使用 EMA 对模型的参数做平均,以求提高测试指标并增加模型鲁棒
- 在深度学习的优化过程中,是 t 时刻的模型权重 weights,是 t 时刻的影子权重(shadow weights)。模型权重在最后的 n 步内,会在实际的最优点处抖动,所以我们取最后 n 步的平均,能使得模型更加鲁棒
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40class EMA():
def __init__(self, model, decay):
self.model = model
self.decay = decay
self.shadow = {}
self.backup = {}
def register(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
self.shadow[name] = param.data.clone()
def update(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
assert name in self.shadow
new_average = (1.0 - self.decay) * param.data + self.decay * self.shadow[name]
self.shadow[name] = new_average.clone()
def apply_shadow(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
assert name in self.shadow
self.backup[name] = param.data
param.data = self.shadow[name]
def restore(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}
# 初始化
ema = EMA(model, 0.999)
ema.register()
# 训练过程中,更新完参数后,同步update shadow weights
def train():
optimizer.step()
ema.update()
# eval前,apply shadow weights;eval之后,恢复原来模型的参数
def evaluate():
ema.apply_shadow()
# evaluate
ema.restore()
为什么指数移动平均(EMA) 对模型训练有利?
- EMA 对第 i 步的梯度下降的步长增加了权重系数,相当于做了一个 learning rate decay
- 第 n 时刻的模型权重(weights)
![]()
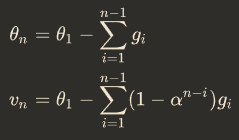
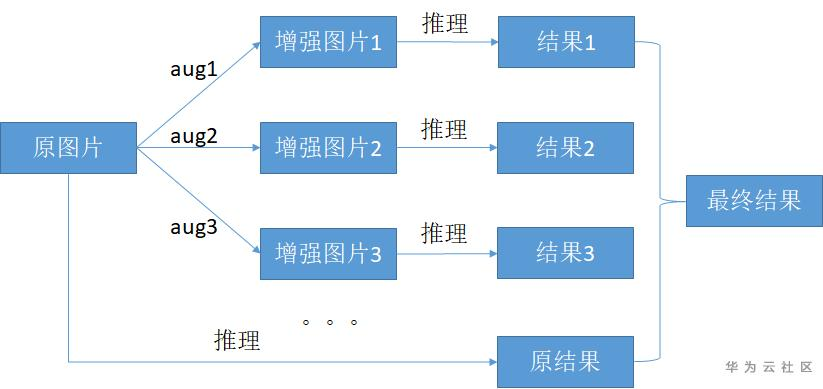
什么是测试时增强(test time augmentation, TTA) ?
![]()
- 通过对原图做增强操作,获得很多份增强后的样本与原图组成一个数据组,然后用这些样本获取推理结果,最后把多份的推理结果按一定方法合成得到最后的推理结果再进行精度指标计算
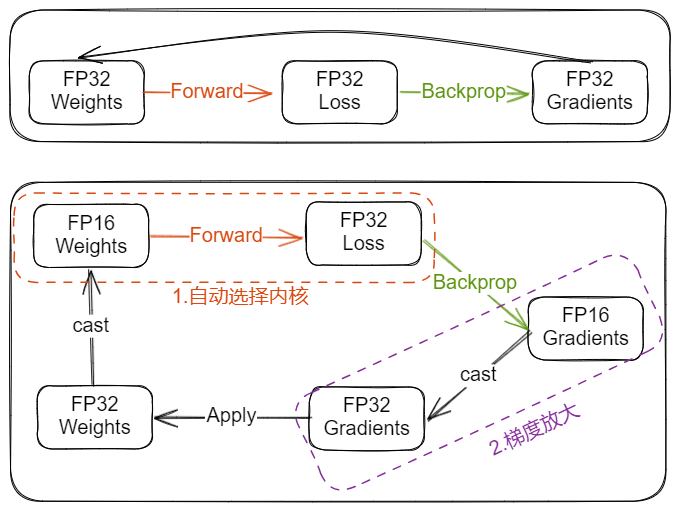
什么是混合精度训练?
![Drawing-2023-04-06-10.55.11.excalidraw]()
- AMP (自动混合精度)指 Float32 与 Float16 的混合,那为什么不单独使用 Float32 或 Float16,原因是:在某些情况下 Float32 有优势,而在另外一些情况下 Float16 有优势。而相比于之前的默认的 torch. FloatTensor,torch. HalfTensor 的劣势不可忽视
- 上图虚线框分别是混合精度训练与 Loss scaling,通常 cast 操作所带来的开销是有限的,当使用 float16 /bfloat16 在前向计算及反向传播过程中取得的计算性能收益大于 cast 所带来的开销时,开启 AMP 训练将得到更优的训练性能
- 好处:1) 减少显存占用:FP16 的内存占用只有 FP32 的一半,自然地就可以帮助训练过程节省一半的显存空间,可以增加 batchsize ;2)加快训练和推断的计算: 与普通的空间时间 Trade-off 的加速方法不同,FP16 除了能节约内存,还能同时节省模型的训练时间
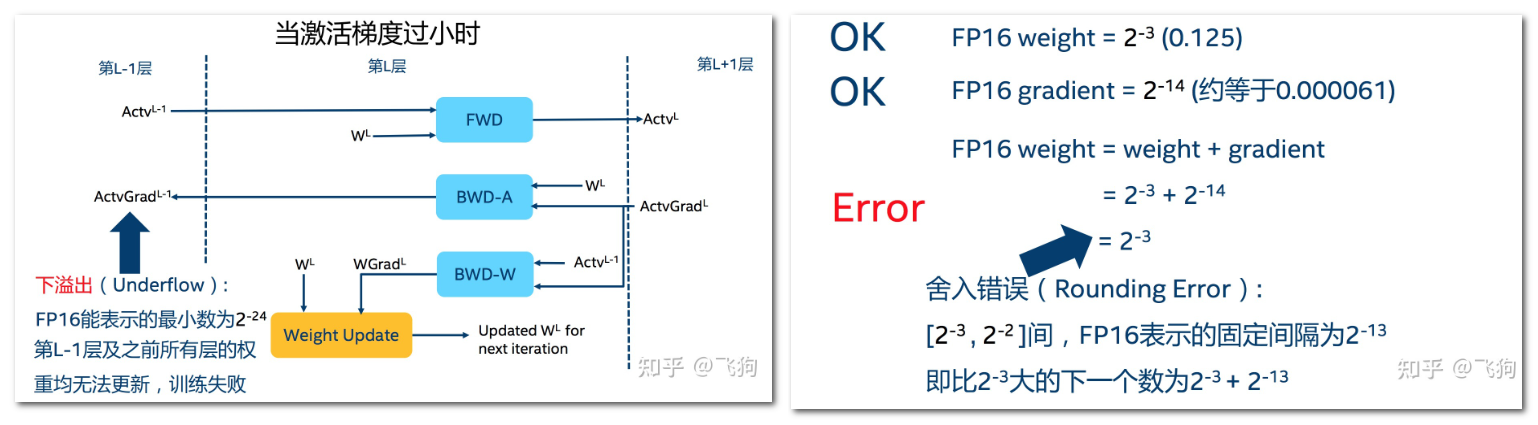
混合精度训练的缺点及解决办法?
![]()
- 坏处:1)溢出错误: 由于 FP16 的动态范围比 FP32 位的狭窄,在计算过程中很容易出现上溢出(Overflow)和下溢出(Underflow),溢出之后就会出现 "NaN" 的问题;2)舍入误差指的是当梯度过小时,小于当前区间内的最小间隔时,该次梯度更新可能会失败
- 解决办法:1)混合精度训练,在内存中用 FP16 做储存和乘法从而加速计算,而用 FP32 做累加;2)Loss scaling,即使了混合精度训练,还是存在无法收敛的情况,原因是激活梯度的值太小,造成了溢出。可以通过使用 torch.cuda.amp.GradScaler,通过放大 loss 的值来防止梯度的 underflow(只在 BP 时传递梯度信息使用,真正更新权重时还是要把放大的梯度再 unscale 回去)
混合精度训练的原理?
![Drawing-2023-04-06-10.55.11.excalidraw]()
- 总结:在前向和反向时使用 FP16,整个过程变成:权重从 FP32 转成 FP16 进行前向计算,得到 loss 之后,用 FP16 计算梯度,再转成 FP32 更新到 FP32 的权重上
- 1) 输入:使用 FP 16 输入
- 2) 前向计算:存储了 FP 32 的权重副本,实际计算时转为 FP 16
- Loss 计算:loss 计算可能涉及 exp,log 操作,为了避免下溢风险,使用 FP 32 计算
- loss scale:将计算出来的 loss 乘上比例因子,scaled_loss=loss*loss_scale
- 5) 反向计算:计算各个参数的梯度
- loss unscale:梯度计算完成后,将各梯度缩小相应倍数
- 7) 梯度规约:累加很多 FP 16 可能造成数据下溢,因此选择在 FP32 规约
- 8) 参数更新:根据梯度是否溢出选择是否进行参数更新并动态调整 loss_scale,若更新,直接在 FP32 精度上更新
Pytorch 使用混合精度训练模型?
- AMP (自动混合精度)是由 PyTorch 1.6 的 torch. cuda. amp 模块带来的
- autocast:当进入 autocast 上下文后,在这之后的 cuda ops 会把 tensor 的数据类型转换为半精度浮点型,从而在不损失训练精度的情况下加快运算。而不需要手动调用. half (), 框架会自动完成转换。不过,autocast 上下文只能包含网络的前向过程 (包括 loss 的计算),不能包含反向传播,因为 BP 的 op 会使用和前向 op 相同的类型
- GradScaler:scaler 的大小在每次迭代中动态估计,为了尽可能减少梯度 underflow,scaler 应该更大;但太大,半精度浮点型又容易 overflow(变成 inf 或 NaN)。所以,动态估计原理就是在不出现 if 或 NaN 梯度的情况下,尽可能的增大 scaler 值。在每次 scaler. step (optimizer) 中,都会检查是否有 inf 或 NaN 的梯度出现。如果出现 inf 或 NaN,scaler.step (optimizer) 会忽略此次权重更新 (optimizer.step ()),并将 scaler 的大小缩小;如果没有出现 inf 或 NaN, 那么权重正常更新,并且当连续多次 (growth_interval 指定) 没有出现 inf 或 NaN,则 scaler.update () 会将 scaler 的大小增加
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21from torch.cuda.amp import autocast, GradScaler
# 创建model,默认是torch.FloatTensor
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
# 在训练最开始之前实例化一个GradScaler对象
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
# 前向过程(model + loss)开启 autocast
with autocast():
output = model(input)
loss = loss_fn(output, target)
# Scales loss. 为了梯度放大.
scaler.scale(loss).backward()
# scaler.step() 首先把梯度的值unscale回来.
# 如果梯度的值不是 infs 或者 NaNs, 那么调用optimizer.step()来更新权重,
# 否则,忽略step调用,从而保证权重不更新(不被破坏)
scaler.step(optimizer)
# 准备着,查看是否要增大scaler
scaler.update()
参考: