目标检测认识 01 - 检测原理
目标检测原理汇总
目标检测原理
以前不清楚目标检测的时候,老是对一个问题不明白:一张图片上目标数量不定,但神经网络的最后输出一定是定长的,那怎么预测一张图上的多个目标呢?
就拿我们最熟悉的分类来说:已知分类模型的最后输出等于类别数量 (N),而且计算损失的时候也是输出 (N) 与 gt (N) 等长度的向量计算,也就是说每个输出都参与损失的计算 (假设是多标签分类)
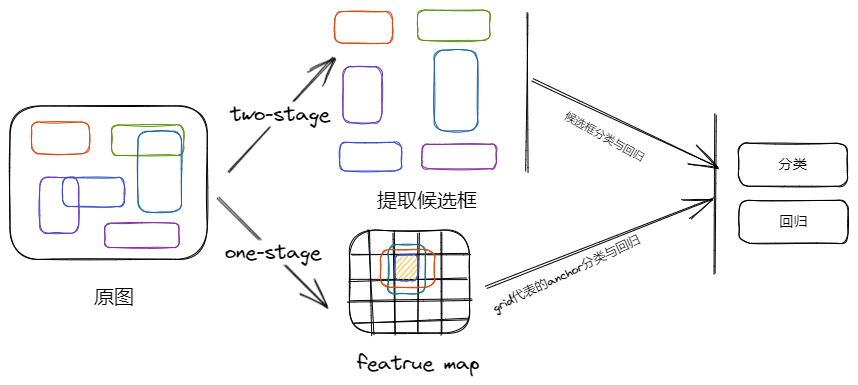
但是目标检测情况有点不一样,即图片上的目标数量是未知的,有 2 种思路去解决模型输出的问题
- 基于候选框的目标检测:先生成能覆盖住目标大量的获选框,然后将网络输出固定为框的分类及定位预测
- 基于 grid 的目标检测:直接输入全图,然后模型设计大量的输出,然后选择某些输出去监督网络的学习,最后过滤所有输出,找到预测框
无论是先生成大量获选框、还是设计大量的输出,都是为了使用 “大数量” 的输出确保覆盖目标数量不定的图片
基于候选框的目标检测
第一步:先将候选框计算出来
第二步:将候选框以定长的特征表示
第三步:基于定长的特征使用 SVM 或神经网络对获选框进行分类与回归
| 模型 | 原理 | 备注 |
|---|---|---|
| RCNN | 1. 通过选择性搜索确定候选框 2. 通过多次推理候选框、SPP 或者 ROI Pooling 获得候选框定长特征 3. 通过神经网络或 SVM 对候选框进行分类与回归 | 选择性搜索 + SVM |
| SPPNet | 1. 通过选择性搜索确定候选框 2. 通过多次推理候选框、SPP 或者 ROI Pooling 获得候选框定长特征 3. 通过神经网络或 SVM 对候选框进行分类与回归 | 选择性搜索 + 空间金字塔池化 SPP+SVM |
| FastRCNN | 1. 通过选择性搜索确定候选框 2. 通过多次推理候选框、SPP 或者 ROI Pooling 获得候选框定长特征 3. 通过神经网络或 SVM 对候选框进行分类与回归 | 选择性搜索 + ROI Pooling + 神经网络分类与回归 |
| FasterRCNN | 1. 通过 RPN 使用神经网络学习提出获选框 2. 通过 ROI Pooling 将获选框特征转为固定 2 D featrue map,然后使用神经网络进行分类与回归 | 锚框 + RPN+ROI Pooling + 神经网络分类与回归 |
| FPN | 1. 通过 RPN 使用神经网络学习提出获选框 2. 通过 ROI Pooling 将获选框特征转为固定 2 D featrue map,然后使用神经网络进行分类与回归 | 特征金字塔 + RPN+ROI Pooling + 神经网络分类与回归(多 head) |
基于 grid 的目标检测
第一步:把最后一层特征的 cell 当作目标关联信息 (中心、左上角、右下角)
第二步:对每个 cell 进行分类和回归,相当于在原图上对目标检测分类与回归
| 模型 | anchor | 输出 | 备注 |
|---|---|---|---|
| YOLOv1 | ✅ | 该系列方法首次提出,每个 cell 预测 1 个类别,多个 box,B x 5+C | 该系列首个模型 |
| YOLOv2 | ✅ | 每个 cell 的 bbox 预测类别、置信度、位置 B x(5+C) | 该系列第一次引入锚框 |
| YOLOv3 | ✅ | 每个 cell 的 bbox 预测类别、置信度、位置 B x(5+C)+ 多 head | 使用 FPN + 多 head |
| YOLOv4 | ✅ | 每个 cell 的 bbox 预测类别、置信度、位置 B x(5+C)+ 多 head | 使用 PAN + 多 head |
| YOLOv5 | ✅ | 每个 cell 的 bbox 预测类别、置信度、位置 B x(5+C)+ 多 head | 灵活的模型切换 ++ 多 head |
| YOLOv7 | ✅ | 每个 cell 的 bbox 预测类别、置信度、位置 B x(5+C)+ 多 head | 参数一致性的模型缩放策略 ++ 多 head |
| SSD | ✅ | 每个 cell 的 bbox 预测类别、置信度、位置 B x(5+C)+ 多 head | YOLOv 1 + 多个 featrue map 的多 head |
| DSSD | ✅ | 每个 cell 的 bbox 预测类别、置信度、位置 B x(5+C)+ 多 head | SSD + 反卷积上采样 + 多 head |
| YOLOF | ✅ | 每个 cell 的 bbox 预测类别、置信度、位置 B x(5+C)+ 单 head | 单 head 就实现检测 |
| RetinaNet | ✅ | 每个 cell 的 bbox 预测类别、位置 B x(4+C)+ 单 head | 使用 FPN + 多 head |
| YOLOv6 | ❌ | 每个 cell 预测 1 个分类、1 个置信度、1 个位置(xywh),C+1+4 + 多 head | 在 YOLOv 6 的基础上增加重参数化 |
| YOLOv8 | ❌ | 每个 cell 的 bbox 预测类别、位置 B x(4+C)+ 多 head | 在 YOLOv7 的基础上设计 anchor-free,配合 TAL 正样本匹配 |
| YOLOv10 | ❌ | 每个 cell 的 bbox 预测类别、位置 B x(4+C)+ 多 head + 双 head | 在 YOLOv 8 的基础上设计双 head,抛弃 NMS |
| YOLOX | ❌ | 每个 cell 预测 1 个分类、1 个置信度、1 个位置(xywh),C+1+4 + 多 head | 在 YOLOv 3 的基础上,去掉 anchor |
| CornerNet | ❌ | 每个 cell 预测 1 个分类 heatmaps、1 个编码 embding、1 个中心偏差 offset (xy),C+1+2 | 另辟蹊径,检测目标左上角和右下角 |
| CenterNet | ❌ | 每个 cell 预测 1 个分类 heatmaps、1 个宽高 (wh)、1 个中心偏差 offset (xy),C+2+2 | 另辟蹊径,检测目标的中心点及宽高 |
| FCOS | ❌ | 每个 cell 预测 1 个分类 heatmaps、1 个中心打分(xy)、1 个宽高 (whwh),C+1+4 + 多 head | 另辟蹊径,检测目标的中心点及中心到四周的距离 |
| PP-YOLOE | ❌ | 每个 cell 的 bbox 预测类别、位置 B x(4+C)+ 多 head | 基于 YOLOv5 提出的 anchor-free 模型 |
| RT-DETR | ❌ | 每个 cell 的 bbox 预测类别、位置 300 x(4+C),300 是解码器自定义数量 | 基于 DETR 提出的更加高效的目标检测模型,应用了最小化不确定性 |
输出预测框
目标检测输出结果一般不是直接的结果,而是要进行一系列加工
对于 RNN、SPPNet、FastRCNN 而言,其输入是选择性搜索的候选框,输出是 SVM 结果 + 分类结果 + 位置回归结果
其解码如下:
(1) SVM 结果:确定获选框内是否有目标,如果有目标进行以下步骤
(2) 分类结果 + 位置回归结果:直接输出就是预测框结果
对于 Faster RCNN、FPN 及 YOLO 系列等基于 grid 的目标检测模型,其输出是 (B, G, 置信度 + num_class+box),
其解码如下:
- 编码时,首先根据置信度得到预测位置,然后取出预测位置的分类打分、中心偏差、宽高,位置结合中心偏差和宽高映射,将预测结果还原到原图上
- 其次 NMS,一般是置信度分类打分作为预测框的分数,然后参与 NMS,得到的结果就是解码结果
注意:
- 多个 head,无非就是将所有 head 的预测信息汇总到原图后再进行 NMS
- 对于无置信度输出的模型,如 RetinaNet,直接进行 NMS 即可,或者把分类分数当作置信度
- 其他非 anchor 预测模型,首先是从 heatmap 上解出分类 topK 比分的位置,然后根据再进行 NMS,如 CornerNet、CenterNet、FCOS