ERNIE-ViLG:Unified Generative Pre-training for Bidirectional Vision-Language Generation
通过 mask 掉注意力,在同一个网络内实现文生图、图生文
- 文本编码 +(图像编码)-> 自回归 -> 新图像编码 ->dVAE decoder-> 条件图片
- 图像编码 +(文本编码)-> 自回归 -> 文本编码 -> 标题,文生图、图生文
什么是 ERNIE-ViLG ?
![]()
- 一种使用 Transformer 模型进行双向图像文本生成的统一预训练方法,其中图像和文本生成都被表述为自回归生成任务
- 已有基于图像离散表示的文本生成图像模型主要采用两阶段训练,文本生成视觉序列和根据视觉序列重建图像两个阶段独立训练,文心 ERNIE-ViLG 提出了端到端的训练方法,将序列生成过程中 Transformer 模型输出的隐层图像表示连接到重建模型中进行图像还原,为重建模型提供语义更丰富的特征
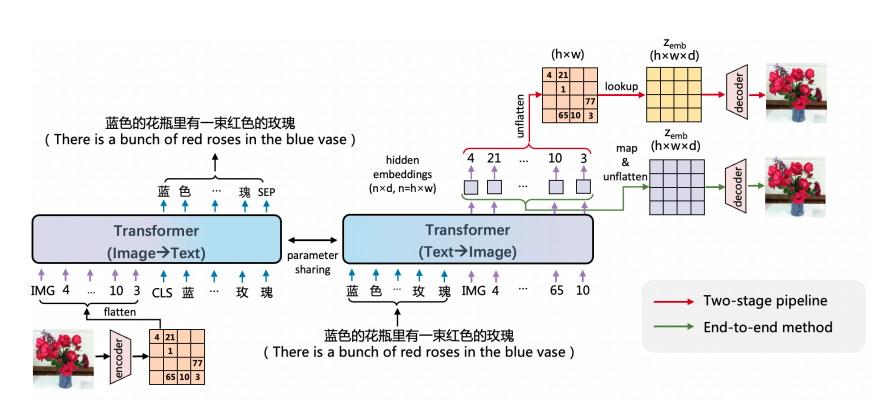
ERNIE-ViLG 的网络结构?
![]()
- 图像通过矢量变分自动编码器(VQVAE)表示为一个离散的表征序列,被用作参数 Tranformer 的输入 / 输出,用于自回归图像 - 文本 / 文本 - 图像生成,其目地是最大化似然函
- 图生文:对于图像到文本的生成,Tranformer 将图像离散序列作为输入,生成相应的文本序列
- 文生图:对于文本到图像的合成,文本被输入到 Tranformer 以生成相应的视觉离散序列,然后图像离散序列被用于重建图像
- 除了传统的两阶段管道模式外 ERNIE-ViLG 的文本到图像的合成还可以端到端训练,如图 的绿色路径。最后一个 Transformer 层输出的图像标记的隐藏嵌入被非线性映射到 z_emb。由于避免了不可导出的 ID 映射操作,因此梯度可以从重构器向后传播到生成器。因此,可以进行端到端的训练
ERNIE-ViLG 如何优化 transformer?
![]()
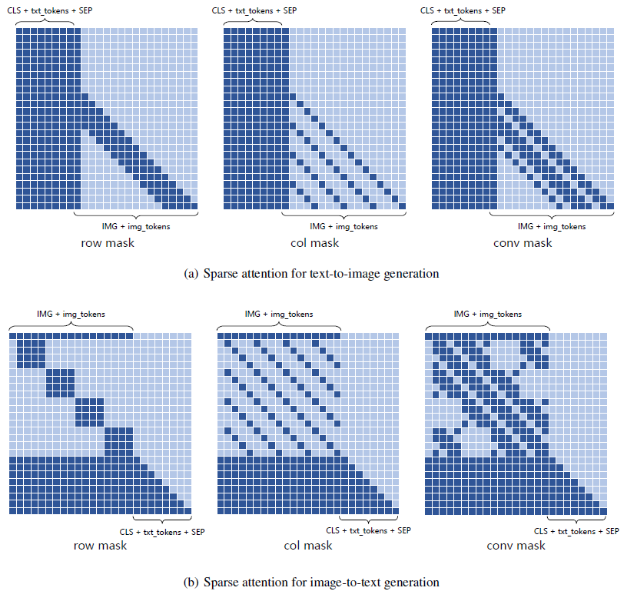
- 视觉序列 z 的长度 n 通常很大(通常大于 1024)以减少图像的信息损失,这导致 Transformer 模型在训练和推理过程中的计算成本和内存消耗相对较高
- 稀疏注意力机制:上图分别是文生图、图生文的 3 种注意力,一起构成稀疏注意力
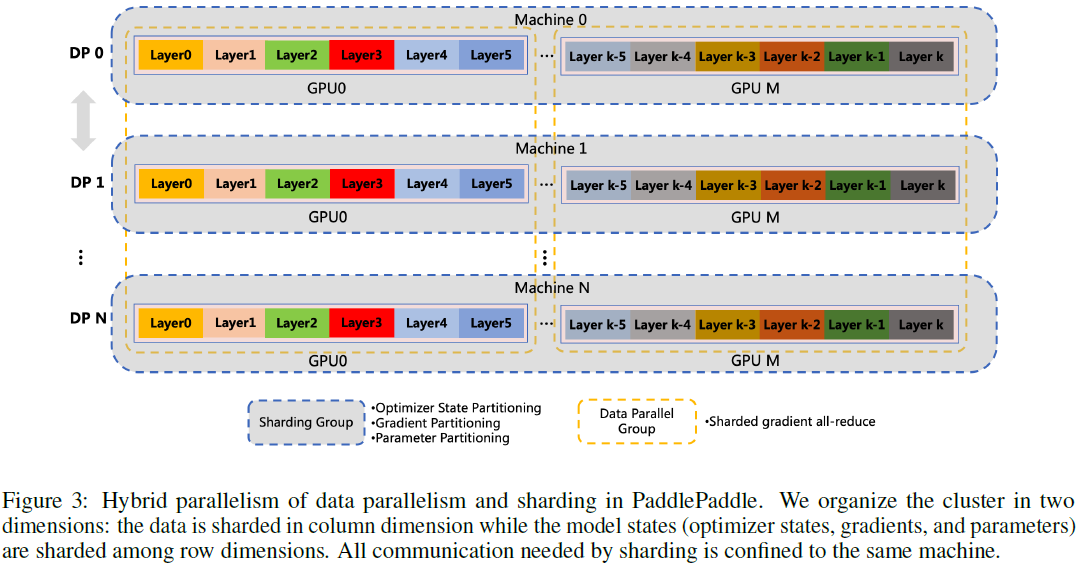
ERNIE-ViLG 的大规模分布式训练策略?
![]()
- 采用组分片数据并行(Group Sharded data parallelism)技术,通过跨多个设备划分优化器状态、梯度和参数来消除内存冗余。 此外,还应用激活重新计算和混合精度来减少 GPU 内存占用并提高吞吐量。 此外,引入了 Optimizer-offload 将分片优化器状态和主参数交换到 CPU,这大大减少了 GPU 内存占用
参考: