GAN:Generative Adversarial Networks
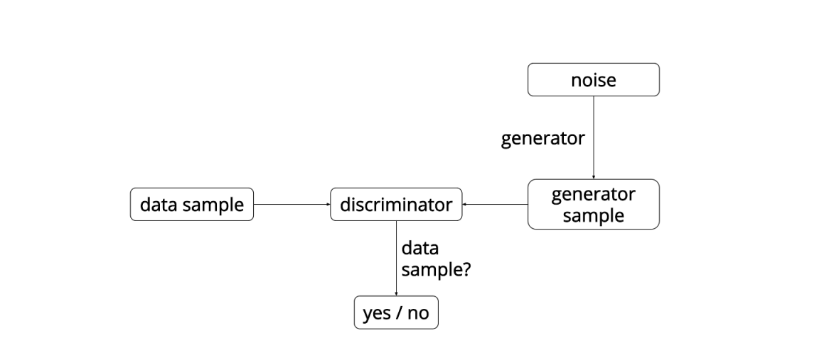
非监督的学习过程,由一个生成网络与一个判别网络组成,其中生成网络生成样本,判别网络区分的是生成样本还是真实样本,在训练后期判别器判定概率接近 0.5,然后拿生成器去生成图像
噪声 -> 随机图片,随机图片
什么是生成对抗网络 (Generative Adversarial Network, GAN)?
![]()
生成对抗网络是非监督式学习方法,由一个生成网络与一个判别网络组成
生成对抗网络本质就是两个网络协同训练,首先生成网络从潜在空间中随机取样作为输入,其输出结果需要尽量模仿训练集中的真实样本。判别网络的输入则为真实样本或生成网络的输出,其目的是将生成网络的输出从真实样本中尽可能分辨出来。通过两个网络相互对抗、不断调整参数,最终目的是使判别网络无法判断生成网络的输出结果是否真实
生成对抗网络 GAN 的原理?
![]()
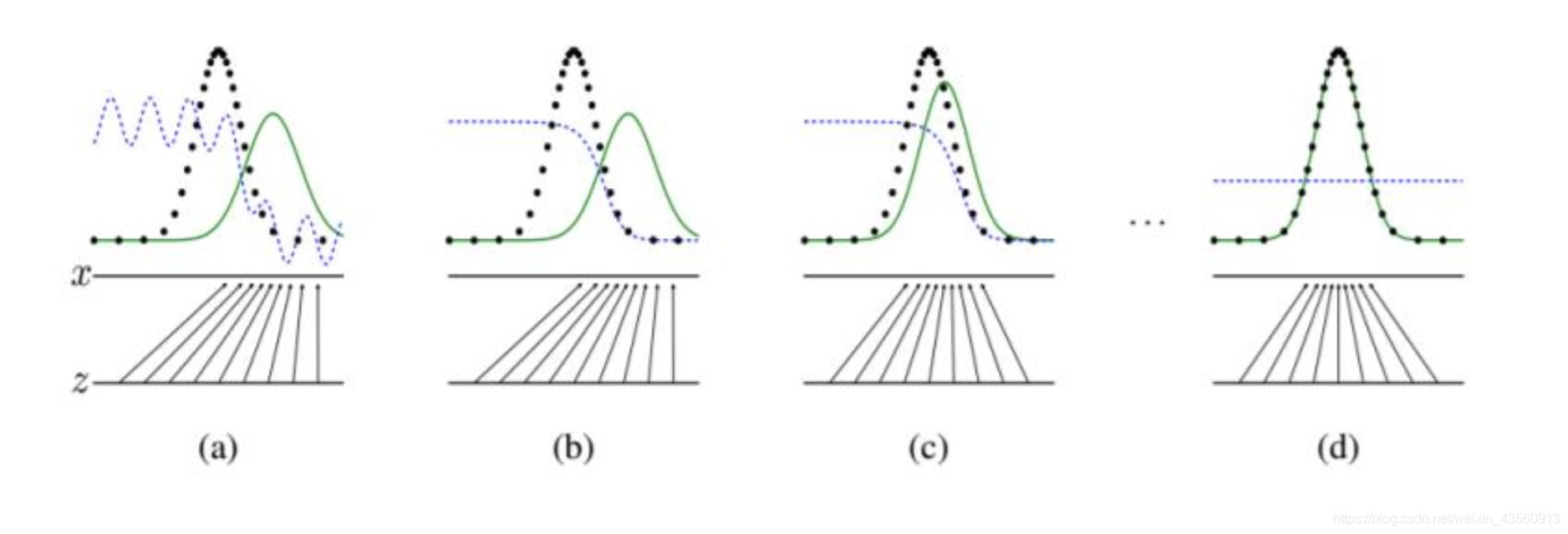
图中的黑色虚线表示真实的样本的分布情况,蓝色虚线表示判别器判别概率的分布情况,绿色实线表示生成样本的分布。Z 表示噪声,Z->x 表示通过生成器之后的分布的映射情况
生成器:目的是从 Z->x (绿线),并且通过网络学习不断使得生成样本分布 (绿线) 接近真实分布 (黑线)
判别器:目的是区分出生成样本 / 真实样本,可以看出网络前期能轻易判别,训练后期判断概率接近 0.5,就是无法判别生成样本
当判别器无法判别生成样本时,意味着生成器生成的样本可以 “以假乱真” 了
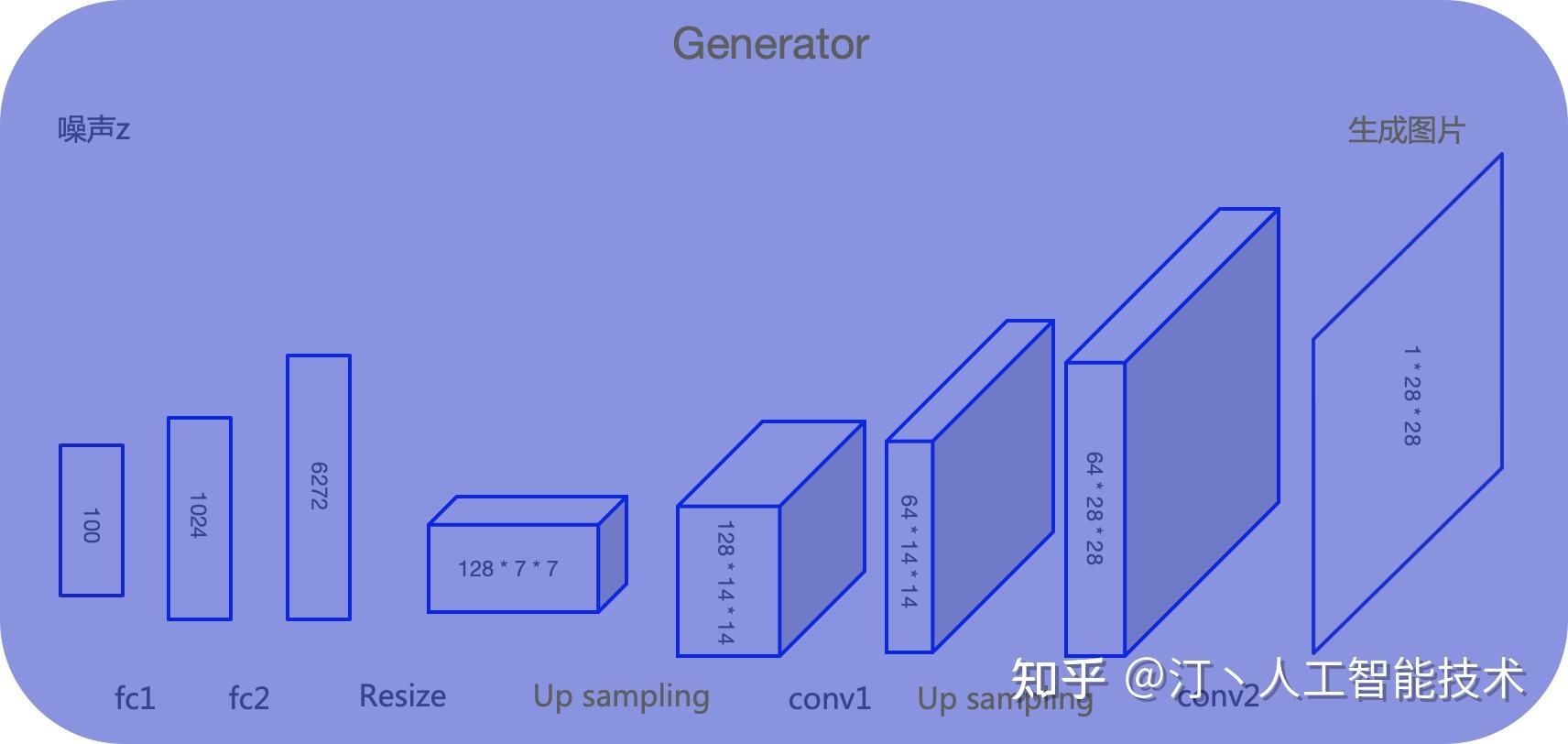
生成器为什么可以从随机数中生成图片?
![]()
生成器 G 是一个生成图片的网络,可以采用多层感知机、卷积网络、自编码器等。它接收一个随机的噪声 z,通过这个噪声生成图片,记做 G (z)
随机噪声不是完全随机的,如果是完全随机,生成器没法拟合出一个稳定的分布,结果就不可控,因此通常从一个先验的随机分布产生噪声。常用的随机分布:高斯分布、均匀分布
生成对抗网络如何训练?
![]()
在训练过程中,生成器 G 的目标就是尽量生成真实的图片去欺骗判别器 D。而 D 的目标就是尽量把 G 生成的图片和真实的图片区分开。这样,G 和 D 构成了一个动态的 “博弈过程”,训练损失计算如下,其中 D (x) 表示对真实样本的识别概率、1-D (G (z)) 表示对生成样本的识别概率:
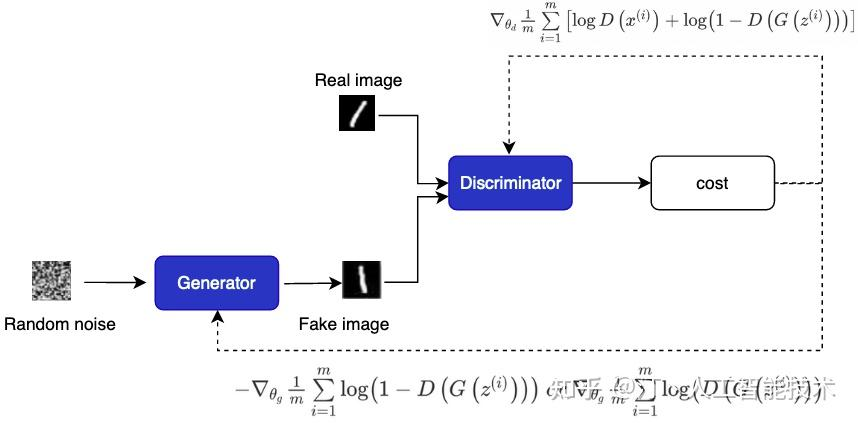
- 先训练鉴别器 D:将真实图片打上真标签 1 和生成器 G 生成的假图片打上假标签 0,一同组成 batch 送入判别器 D,对判别器进行训练。计算 loss 时使判别器对真实图像输入的判别趋近于真,对生成的假图片的判别趋近于假。此过程中只更新判别器的参数,不更新生成器的参数。此时 D (x)、1-D (G (z)) 都应该越大判别效果越好,所以损失函数变为:
- 再训练生成器 G: 将高斯分布的噪声 z 送入生成器 G,将生成的假图片打上真标签 1 送入判别器 D。计算 loss 时使判别器对生成的假图片的判别趋近于真。此过程中只更新生成器的参数,不更新判别器的参数。此时 D (x)、1-D (G (z)) 应该越小生成样本越真实,所以损失函数为:
训练 GAN 需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到。还没有找到很好的达到纳什均衡的方法,所以训练 GAN 相比 VAE 或者 PixelRNN 是不稳定的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31imgs=batch # 一个batch的数据
# 根据当前batch,生成真实样本标签和假样本标签
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
# 真实样本
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# 训练生成器:生成样本,并使得生成样本接近真实样本
# -----------------
optimizer_G.zero_grad()
# 随机生成输入
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# 生成batch个样本
gen_imgs = generator(z)
# 计算生成的假样本与真实标签的损失,减少这个损失,相当于让生成样本更接近真实标签
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# 训练辨别器:辨别真实样本和生成样本,使得生成样本更接近假标签,真实样本更接近真标签
# ---------------------
optimizer_D.zero_grad()
# 计算真实样本和真实标签的差距,让辨别器分得出真实样本
real_loss = adversarial_loss(discriminator(real_imgs), valid)
# 计算生成样本和假标签的差距,让辨别器分得出生成样本
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()生成对抗网络训练不稳定的原因?
超参数敏感:指网络的结构设定、学习率、初始化状态等超参数对网络的训练过程影响较大,微量的超参数调整将可能导致网络的训练结果截然不同。如图所示,图 (a) 为 GAN 模型良好训练得到的生成样本,图 (b) 中的网络由于没有采用 Batch Normalization 层等设置,导致 GAN 网络训练不稳定,无法收敛,生成的样本与真实样本差距非常大
![]()
模式崩塌:指模型生成的样本单一,多样性很差的现象。由于判别器只能鉴别单个样本是否采样自真实分布,并没有对样本多样性进行显式约束,导致生成模型可能倾向于生成真实分布的部分区间中的少量高质量样本,以此来在判别器中获得较高的概率值,而不会学习到全部的真实分布。模式崩塌现象在 GAN 中比较常见,如图所示,在训练过程中,通过可视化生成网络的样本可以观察到,生成的图片种类非常单一,生成网络总是倾向于生成某种单一风格的样本图片,以此骗过判别器
![]()
什么是纳什平衡?
![]()
指的是参与者的一种策略组合,在该策略上,任何参与人单独改变策略都不会得到好处,即每个人的策略都是对其他人的策略的最优反应。换句话说,如果在一个策略组合上,当所有其他人都不改变策略时,没有人会改变自己的策略,则该策略组合就是一个纳什均衡
经典例子:警察抓住两个共同犯案的疑犯,这两个疑犯被分开审讯,其判刑结果如上图,A\B 都坦白判刑 8 年,其中一个人坦白一个人不招供,则分别判刑 0/10,两个人都不招供则都判刑 1 年。从奖惩说明看都不招供才是最优解,判刑最少。其实并不是这样,A 和 B 无法沟通,于是从各自的利益角度出发,于是嫌疑犯 A/B 想法相同,都依据各自的理性而选择招供,这种情况就被称为纳什均衡点
在 GAN 网络中,生成器和判别器最终训练完成时,生成器生成的样本分布接近真实样本分布时,判别器以 0.5 的概率分别生成样本,即无法判别真假,此时达到纳什平衡



参考:
- https://zh.wikipedia.org/wiki/ 生成对抗网络
- 三十分钟理解博弈论 “纳什均衡” - 知乎
- GAN 相关知识点 - 纳什均衡、模型崩塌、WGAN 原理、EM 距离、JS 散度等_gan js 散度_muxinzihan 的博客 - CSDN 博客
- 深度学习进阶篇 [8]:对抗神经网络 GAN 基本概念简介、纳什均衡、生成器判别器、解码编码器详解以及 GAN 应用场景 - 知乎
- 图解 生成对抗网络 GAN 原理 超详解_生成对抗网络 gan 原理_DFCED 的博客 - CSDN 博客
- GAN tricks - Yi’s site
- Tips On Training Your GANs Faster and Achieve Better Results | by Tushar Mittal | Intel Student Ambassadors | Medium