DragGan:Interactive Point-based Manipulation on the Generative Image Manifold
DragGan 通过在图片定义起始点、目标点,实现起始点所在物体向目标点移动,实现图片的编辑
图 + 交互 -> 条件图片,条件图片
什么是 DragGan ?
![]()
- DragGAN 允许通过交互的方式编辑图像生成效果,交互过程是定义起点(红色)和目标点 (蓝色),红点所在的图像语义信息将移动到蓝点
- 同时,通过选定一个灵活区域,使得图片修改只在掩码内进行,而保持其它区域不变,可是控制图像的许多空间属性,如姿态、形状、表达式和布局

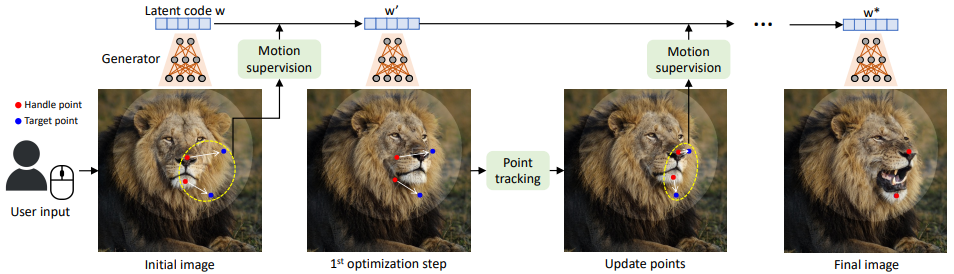
DragGan 的原理?
![]()
- DragGAN 实现时不是一下子从起始点移动到目标点,而是一步一步递归向目标点移动,所以 DragGAN 要实现以下两个过程
- 运动监督:监督新生成的图像从起始点向目标点移动
- 点跟踪:获取移动后新的起始点,然后作为监督信息输入到下一次运动监督中
DragGan 如何实现运动监督?
![]()
- 运动监督是指输入图像 + 运动监督信息,生成借鉴监督信息的图片
- 考虑到生成器产生的中间特征更有区分性,DragGan 没有直接将监督信息输入生成器,而是在 StyleGAN2 的第 6 块之后的特征映射 F 做监督,首先通过双线性插值调整 F 的大小以与最终图像相同的分辨率
- 上图定义起始点 p 向目标点 t 的学习过程,为了将一个手柄点𝒑𝑖移动到目标点𝒕𝑖,我们的想法是监督𝒑𝑖周围的一个小斑块(红色圆圈),通过一个小的步骤(蓝色圆圈)向𝒕𝑖移动。我们使用 Ω1 (𝒑𝑖,𝑟1) 来表示距离𝒑𝑖小于𝑟1 的像素,那么我们的运动监督损失
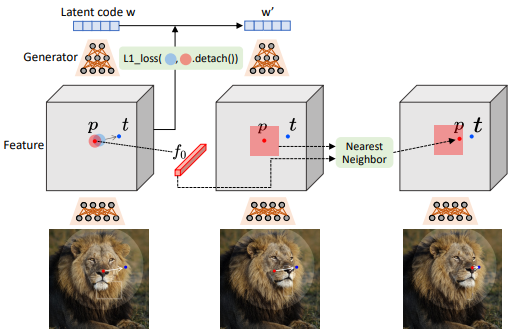
- 其中 F(𝒒)为 F 在像素𝒒处的特征值, 为指向𝒑𝑖到𝒕𝑖的归一化向量(𝒅𝑖= 0 if 𝒕𝑖=𝒑𝑖),F0 为初始图像对应的特征映
- 通过损失函数,可以这样理解前半部分是让 handle point 沿着 handle point——>target point 这条直线不断靠近 target point;后半部分让用户划分的变动范围以外的内容(即掩码)保持和初始图像不变
DragGan 如何实现点跟踪?
![]()
- 由于运动监督过程中,每次向目标点移动的步长无法估计,所以要进行下一次运动估计时,需要先确定 "新的起始点位置",DragGan 通过简单计算确定运动监督前后 p 的位置变换,而不需要使用神经网络
- 只需要找到在移动的过程中有哪些点和 fi 最相似(也就是公式中要 min 的东西,它这里使用距离公式衡量相似度),那么这个点就是我们寻找的轨迹点,也就实现了点跟踪,其中 表示 pi 附近的点, $$p_i:=\quad arg\min_{q_i\in\Omega_2\left (p_i,r_2\right)}||F^{\prime}(q_i)-f_i||_1.$$
DragGan Mask 的作用?
![]()
- 当给狗的头上加上掩码时,其他区域几乎固定不变,只有头部移动。如果没有掩码,这个操作会移动整个狗的身体。这也表明,基于点的操作通常有多种可能的解,而 GAN 将倾向于在从训练数据中学习到的图像流形中找到最接近的解。掩模功能可以帮助减少歧义,并保持某些区域的固定

参考: