EAST:An Efficient and Accurate Scene Text Detector
EAST 基于 FCN 输出,对每个 grid 进行文本行预测,可实现旋转矩形框、任意四边形框的预测
什么是 EAST ?
![EAST-20230408144126]()
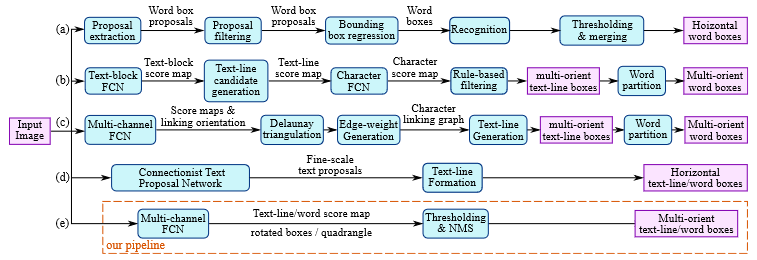
- (a)、(b)、(c)、(d)都是几种常见 stat-of-the-art 的文本检测过程,算法思想遵循之前 two-stage 的方法,一般都需要先提出候选框,过滤后对剩下的候选框要进行回归操作得出更精细的边框信息,然后再合并候选框等
- EAST 基于 FCN 输出特征,类似 anchor-free 的目标检测模型,预测每个 grid 的代表的文本行信息,然后使用 NMS(非极大值抑制)合并预测后的信息,可实现矩形、选择矩阵和四边形的文本检测,不能实现弯曲文本的检测
EAST 的网络结构?
![EAST-20230408144126-1]()
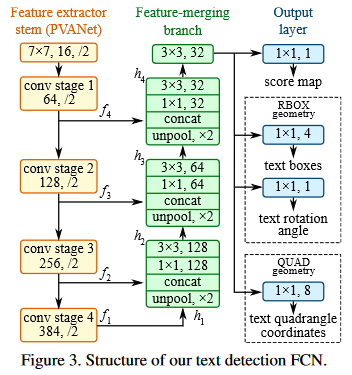
- FCN 特征提取:通过特征提取和特征融合两个步骤,最后取 C 2 特征输入预测头
- 预测结果的输出层:假设 C 2 特征大小为 CHW,对于 HW 的每个 grid 输出 2 个分支,第一个分支是置信度 (1),第二个分支是框位置,框位置如果是旋转矩形,则输出 4 (xyxy)+1(angle),如果是任意的四边形,则输出 8 (xy * 4)
EAST 的标签分配?
- 检测 head 没有设置 anchor,直接按映射位置确定正样本,文本行比较大,可以按照多正样本匹配
EAST 的标签生成?
![EAST-20230408144127]()
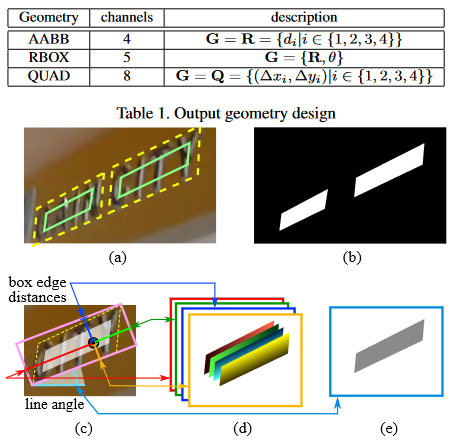
- 垂直或水平矩阵框 (AABB):只需要 4 个值就可描述;旋转矩形框 (RBOX) : AABB 的基础上增加角度,共 5 个值描述;任意四边形(QUAD):需要 4 个点 8 个值去描述
EAST 的损失函数?
- 分割损失 :使用 blance 的交叉熵
- 位置损失 :直接使用 L 1 或者 L 2 损失去回归文本区域将导致损失偏差朝更大更长,所以使用 IOU loss 监督 AABB 或 RBOX 类型框的位置;对于 QUAD 类型的回归框,使用尺度归一化的 smooth L 1 损失
EAST 如何解析模型输出
- 模型输出包括 2 部分,1)score map:检测框的置信度,1 个参数;2)text boxes:对于检测形状为 RBOX,检测框的位置(x, y, w, h)+ 旋转角度 (angle),5 个参数;对于检测形状为 QUAD,则输出任意四边形检测框的位置坐标,(x 1, y 1), (x 2, y 2), (x 3, y 3), (x 4, y 4),8 个参数
- 取 topK 的 score map 对应的预测框,然后采用 Locality-Aware NMS 过滤这些预测框,得到最终结果
参考: