Pytorch 读取数据
总结了 PyTorch 中关于数据加载和处理的关键概念,包括 Dataset, DataLoader, Sampler, 和自定义数据集的方法
实践地址: Github-BuildData
深度学习传统读取数据的方式?

- 定义一个读取图片的函数
- 定义一个数据预处理的函数
- 定义一个数据增强的函数
- 定义一个随机读取 batchsize 个数据的函数
- 多次调用随机读取函数获取数据
使用深度学习传统读取数据的方式有那些缺点?
- 一般数据使用 numpy 处理,当数据量很大时,内存占用很大
- 需要提前读取数据,每次训练占用时间过多
- 使用单线程读取数据,读取效率低下
- 扩展性差,对数据进行预处理及增强时,写法很用优雅
Pytorch 数据读取的一般流程?
- 读取 txt 或 csv 文件,得到 train 和 val 相应的 names list 和 label (也就是图像存放的地址和图像相应的标签)
- 对读取到的 label 进行处理,比如挑出一共存在几类,为分类定数字标签 (比如狗对于 0,猫对于 1)
- 将读取到的数据制作为 dataset 类,即可以通过__getitem__去索引
- 利用 transform_datasets 包装创建好的 dataset 类,对图像进行图像增强技术,可以在训练的时候实时进行图像变化 (也包括对图像的尺寸变化)
- 最后利用 dataloader 包装 transform_datasets,确定 batch_size 和 num_workers, 得到 train 和 val 的 dataloader 类,方法参考: 初始化 Pytorch 的数据加载器 DataLoader
- 利用 DeviceDataLoader 类将得到的 dataloader 类迁移到使用的 device (GPUs or CPU)
什么是 Pytorch 的 Dataset?
- 该 Dataset 类负责访问和处理单个数据实例,通过继承并实现 torch.utils.data.Dataset 类完成
- 该类可以通过 3 种方式进行初始化
- torchvision 构建常用数据集的 Dataset
- Pytorch 的 Map-stylec 初始化 Dataset
- Pytorch 的 Iterable-style 初始化 Dataset
Pytorch 如何实现自定义 Map-style 的 Dataset?
- 自定义该 Dataset 类中都应该继承 torch.utils.data.Dataset
- 其中两个私有成员函数必须被重载,否则将会触发错误提示,1)__getitem__函数的作用是根据索引 index 遍历数据;2)__len__函数的作用是返回数据集的长度
1
2
3
4
5
6
7
8# 定义dataset
class MyMapDataset(torch.utils.data.Dataset):
def __init__(self,data):
self.data=data
def __getitem__(self,idx):
return self.data[idx]
def __len__(self):
return len(self.data)
Pytorch 如何实现自定义 Iterable-style 的 Dataset?
- 自定义该 Dataset 都应该继承 torch.utils.data.IterableDataset 的子类,需要实现__iter__() 协议,表示对数据样本的一轮迭代
1
2
3
4
5class MyIterableDataset(torch.utils.data.IterableDataset):
def __init__(self,data):
self.data=data
def __iter__(self):
return iter(self.data) - iter () 方法会得到一个迭代器,每次调用 next () 会得到下一个样本。无法使用索引取元素。所以就不能使用采样器采样得到索引,在使用索引得到样本。
- 这种类型的数据集特别适用于当被调用时 iter (dataset), 可以返回一个从数据库、远程服务器或什至生成的日志读取的数据流实时,此时需要在训练期间进行增量加载
Pytorch 如何使用 ImageFolder 方法初始化 Dataset 类的?
- 即初始化 torchvision.datasets.ImageFolder 类,当数据被文件夹分类存储时,可使用该方法构建数据集索引
- 使用方法
1
2dataset = dataset.ImageFolder(root=data_root, shuffle=True, batch_size=args.batch_size,
num_workers=args.workers)
什么是 Pytorch 的 DataLoader (数据加载器)?
- 用于按 batchsize 读取训练数据的数据加载器,通过初始化类 torch.utils.data.DataLoader 获得
- DataLoader 默认按照数据顺序进行采样,如果需要特殊采样,需要自定义采样器 torch.utils.data.Sampler
- DataLoader 可以对数据进行打乱,可并行加载数据
如何初始化 Pytorch 的 DataLoader?
- 从 Sampler (数据采样器) 中提取数据实例,分批收集它们,然后返回它们以供您的训练循环使用,通过向 torch.utils.data.DataLoader 传入已经构建好的 Dataset 实现
- 参数设置情况
- dataset (Dataset) – 加载数据的数据集。
- shuffle (bool, optional) – 设置为 True 时会在每个 epoch 重新打乱数据 (默认: False)
- batch_size (int, optional) – 每个 batch 加载多少个样本 (默认: 1)
- sampler (Sampler, optional) – 定义从数据集中提取样本的策略。如果指定,则忽略 shuffle 参数
- num_workers (int, optional) – 用多少个子进程加载数据。0 表示数据将在主进程中加载 (默认: 0)
- collate_fn (callable, optional) – 拼接方式
- drop_last (bool, optional) – 如果数据集大小不能被 batch size 整除,则设置为 True 后可删除最后一个不完整的 batch。如果设为 False 并且数据集的大小不能被 batch size 整除,则最后一个 batch 将更小。(默认: False) dataset (Dataset) – 加载数据的数据集
- pin_memory (bool, optional) – 是否将数据保存在 pin memory 区,保留可加速训练
- 使用例子
1
2
3
4# 利用之前创建好的ShipDataset类去创建数据对象
train_dataset = MyDataset(data_path, augment=transform)
# 利用dataloader读取我们的数据对象,并设定batch-size和工作现场
train_loader = DataLoader(train_dataset, batch_size=16, num_workers=4, shuffle=False, **kwargs)
Pytorch 使用数据加载器 DataLoader 进行训练?
- 构建 3 组数据集,分别是 train,val,test,得到 3 组 DataLoader
- 迭代 train 数据集进行训练,并评估模型在 val 数据集上效果
1
2
3
4
5for epoch in range(max_epoch):
for i, data in enumerate(train_loader):
data = image.to(data) # 将tensor数据移动到device当中
optimizer.zero_grad()
output = model(data) # model模型处理(n,c,h,w)格式的数据,n为batch-size
Pytorch 上 DataLoader 参数之间存在互斥关系?
- 如果 sampler 和 batch_sampler 都为 None,那么 batch_sampler 使用 Pytorch 已经实现好的 BatchSampler,而 sampler 分两种情况:1)若 shuffle=True,则 sampler=RandomSampler (dataset) ;2)若 shuffle=False,则 sampler=SequentialSampler (dataset)
- 如果你自定义了 batch_sampler,那么以下参数都必须使用默认值:batch_size, shuffle,sampler,drop_last
- 如果你自定义了 sampler,那么 shuffle 需要设置为 False
Pytorch 中 DataLoader 加载数据的原理?

- 先用采样器采样,采样一次得到一个样本的索引
- 使用 batch_sampler 生成长度为 batch_size 的索引列表
- 使用数据整合函数 collate_fn 将 batch_size 长度的列表整理成 batch 样本(tensor 格式)
什么是 Pytorch 的 Sampler (数据采样器)?
- torch.utils.data.Sampler 采集器基类,每个采样器子类必须提供一个__iter__方法,提供一种迭代数据集元素的索引的方法,以及返回迭代器长度的__len__方法
1
2
3
4
5
6
7class Sampler(object):
def __init__(self, data_source):
pass
def __iter__(self):
raise NotImplementedError
def __len__(self):
raise NotImplementedError
什么是 Pytorch 的 BatchSampler (批数据采样器)?
- class torch.utils.data.BatchSampler (sampler, batch_size, drop_last) 包装另一个采样器以生成小批量索引
什么是 Pytorch 的 DistributedSampler (分布式数据采样器)?
- class torch.utils.data.distributed.DistributedSampler (dataset, num_replicas=None, rank=None, shuffle=True, seed=0, drop_last=False) 将数据加载限制到数据集子集的采样器
Pytorch 上自定义 Sampler (数据采样器) 步骤?
- 根据 Dataset 定义 Sampler,使用默认 BatchSampler,可进行粗粒度采样顺序调整
- 根据 Dataset 定义 BatchSampler,在此基础上定义 BatchSampler,可进行细粒度采样顺序调整
Pytorch 上 Sequential Sampler(顺序采样)?
- class torch.utils.data.SequentialSampler (data_source) 样本元素顺序排列,始终以相同的顺序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class SequentialSampler(Sampler):
def __init__(self, data_source):
self.data_source = data_source
def __iter__(self):
return iter(range(len(self.data_source)))
def __len__(self):
return len(self.data_source)
# 定义数据和对应的采样器
data = list([17, 22, 3, 41, 8])
seq_sampler = sampler.SequentialSampler(data_source=data)
# 迭代获取采样器生成的索引
for index in seq_sampler:
print("index: {}, data: {}".format(str(index), str(data[index])))
# 结果
#index: 0, data: 17
#index: 1, data: 22
#index: 2, data: 3
#index: 3, data: 41
#index: 4, data: 8
Pytorch 上 Random Sampler(随机采样)?
- class torch.utils.data.RandomSampler (data_source, replacement=False, num_samples=None, generator=None) 样本元素随机,没有替换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48class RandomSampler(Sampler):
def __init__(self, data_source, replacement=False, num_samples=None):
self.data_source = data_source
# 采样是否重复
self.replacement = replacement
# 重复采样时,获取的数据量可以超过原有数据量
self._num_samples = num_samples
if not isinstance(self.replacement, bool):
raise ValueError("replacement should be a boolean value, but got "
"replacement={}".format(self.replacement))
if self._num_samples is not None and not replacement:
raise ValueError("With replacement=False, num_samples should not be specified, "
"since a random permute will be performed.")
if not isinstance(self.num_samples, int) or self.num_samples <= 0:
raise ValueError("num_samples should be a positive integer "
"value, but got num_samples={}".format(self.num_samples))
def num_samples(self):
# dataset size might change at runtime
if self._num_samples is None:
return len(self.data_source)
return self._num_samples
def __iter__(self):
n = len(self.data_source)
if self.replacement:
# 生成的随机数可能重复
return iter(torch.randint(high=n, size=(self.num_samples,), dtype=torch.int64).tolist())
# 生成不重复的随机数
return iter(torch.randperm(n).tolist())
def __len__(self):
return self.num_samples
# 例子1:定义数据和对应的采样器
data = list([17, 22, 3, 41, 8])
ran_sampler = sampler.RandomSampler(data_source=data, replacement=True)
# 得到下面的输出
#index: 0, data: 17
#index: 4, data: 8
#index: 3, data: 41
#index: 4, data: 8
#index: 2, data: 3
# 例子2:定义数据和对应的采样器
data = list([17, 22, 3, 41, 8])
ran_sampler = sampler.RandomSampler(data_source=data)
#index: 0, data: 17
#index: 2, data: 3
#index: 3, data: 41
#index: 4, data: 8
#index: 1, data: 22
Pytorch 上 Subset Random Sampler(子集随机采样)?
- torch.utils.data.SubsetRandomSampler,样本元素从指定的索引列表中随机抽取,没有替换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class SubsetRandomSampler(Sampler):
def __init__(self, indices):
# 数据集的切片,比如划分训练集和测试集
self.indices = indices
def __iter__(self):
# 以元组形式返回不重复打乱后的“数据”
return (self.indices[i] for i in torch.randperm(len(self.indices)))
def __len__(self):
return len(self.indices)
# 定义数据和对应的采样器
data = list([17, 22, 3, 41, 8])
sub_sampler_train = sampler.SubsetRandomSampler(indices=data[0:2])
sub_sampler_val = sampler.SubsetRandomSampler(indices=data[2:])
# 下面是train输出
#index: 17
#index: 22
#*************
# 下面是val输出
#index: 8
#index: 41
#index: 3
Pytorch 上 Weighted Random Sampler(加权随机采样)?
- torch.utils.data.WeightedRandomSampler,样本元素来自于、[0,…,len (weights)-1],给定概率(weights)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29class WeightedRandomSampler(Sampler):
def __init__(self, weights, num_samples, replacement=True):
if not isinstance(num_samples, _int_classes) or isinstance(num_samples, bool) or \
num_samples <= 0:
raise ValueError("num_samples should be a positive integer "
"value, but got num_samples={}".format(num_samples))
if not isinstance(replacement, bool):
raise ValueError("replacement should be a boolean value, but got "
"replacement={}".format(replacement))
# weights用于确定生成索引的权重,此处对应的是“样本”的权重而不是“类别的权重”
self.weights = torch.as_tensor(weights, dtype=torch.double)
self.num_samples = num_samples
# 用于控制是否对数据进行有放回采样
self.replacement = replacement
def __iter__(self):
# 按照加权返回随机索引值
return iter(torch.multinomial(self.weights, self.num_samples, self.replacement).tolist())
def __len__(self):
return self.num_samples
# 位置[0]的权重为0,位置[1]的权重为10,其余位置权重均为1.1
weights = torch.Tensor([0, 10, 1.1, 1.1, 1.1, 1.1, 1.1])
wei_sampler = sampler.WeightedRandomSampler(weights, 6, True)
# 下面是输出:
#index: 1
#index: 2
#index: 3
#index: 4
#index: 1
#index: 1
在训练 GAN 的过程中,一次只训练一个类别据说有助于模型收敛,如何自定义 Sampler 实现该数据加载方式?
- 定义 Dataset 类 + 自定义一个 Sampler 类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36class Data(Dataset):
def __init__(self):
self.img = torch.cat([torch.ones(2, 2) for i in range(50)], dim=0)
self.num_classes = 2
self.label = torch.tensor(
[random.randint(0, self.num_classes - 1) for i in range(50)]
)
def __getitem__(self, index):
return self.img[index], self.label[index]
def __len__(self):
return len(self.label)
class CustomSampler(Sampler):
def __init__(self, data):
self.data = data
def __iter__(self):
indices = []
for n in range(self.data.num_classes):
index = torch.where(self.data.label == n)[0]
indices.append(index)
indices = torch.cat(indices, dim=0)
return iter(indices)
def __len__(self):
return len(self.data)
d = Data()
s = CustomSampler(d)
dl = DataLoader(d, 8, sampler=s)
for img, label in dl:
print(label)
#结果
#tensor([0, 0, 0, 0, 0, 0, 0, 0])
#tensor([0, 0, 0, 0, 0, 0, 0, 0])
#tensor([0, 0, 0, 0, 0, 0, 0, 0])
#tensor([0, 1, 1, 1, 1, 1, 1, 1])
#tensor([1, 1, 1, 1, 1, 1, 1, 1])
#tensor([1, 1, 1, 1, 1, 1, 1, 1])
#tensor([1, 1]) - 有 batch 中包含了两种不同类型的标签,为了达到目的,我们还需要再定义一个 BatchSampler 类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55class CustomBatchSampler:
def __init__(self, sampler, batch_size, drop_last):
self.sampler = sampler
self.batch_size = batch_size
self.drop_last = drop_last
def __iter__(self):
batch = []
i = 0
sampler_list = list(self.sampler)
for idx in sampler_list:
batch.append(idx)
if len(batch) == self.batch_size:
yield batch
batch = []
if (
i < len(sampler_list) - 1
and self.sampler.data.label[idx]
!= self.sampler.data.label[sampler_list[i + 1]]
):
if len(batch) > 0 and not self.drop_last:
yield batch
batch = []
else:
batch = []
i += 1
if len(batch) > 0 and not self.drop_last:
yield batch
def __len__(self):
if self.drop_last:
return len(self.sampler) // self.batch_size
else:
return (len(self.sampler) + self.batch_size - 1) // self.batch_size
d = Data()
s = CustomSampler(d)
bs = CustomBatchSampler(s, 8, False)
dl = DataLoader(d, batch_sampler=bs)
for img, label in dl:
print(label)
# 结果
# drop_last = False
#tensor([0, 0, 0, 0, 0, 0, 0, 0])
#tensor([0, 0, 0, 0, 0, 0, 0, 0])
#tensor([0, 0, 0, 0, 0, 0, 0, 0])
#tensor([0])
#tensor([1, 1, 1, 1, 1, 1, 1, 1])
#tensor([1, 1, 1, 1, 1, 1, 1, 1])
#tensor([1, 1, 1, 1, 1, 1, 1, 1])
#tensor([1])
#drop_last = True
#tensor([0, 0, 0, 0, 0, 0, 0, 0])
#tensor([0, 0, 0, 0, 0, 0, 0, 0])
#tensor([0, 0, 0, 0, 0, 0, 0, 0])
#tensor([1, 1, 1, 1, 1, 1, 1, 1])
#tensor([1, 1, 1, 1, 1, 1, 1, 1])
#tensor([1, 1, 1, 1, 1, 1, 1, 1])
Pytorch 上 DataLoader、Dataset、Sampler 是什么关系?

- torch.utils.data.DataLoader:结合一个 Dataset 和一个 Sampler,不关心如何提供数据,只关心如何给模型 1 个 batch 的数据
- torch.utils.data.Dataset:数据抽象类,所有实现类必须实现__getitem__() 和 __ len__() 方法,目的是通过
样本下标从磁盘或者数据增强获得数据 - torch.utils.data.Sampler:采样抽象类,决定加载数据的顺序,所有实现类必须实现__iter__() 和 __ len__() 方法,目的是提供 1 个 batch 的
样本下标 - DataLoader 读取数据时,首先使用 Sampler 获取一个 batch 数据的下标,然后按下标读取 Dataset 上的数据
1
2
3
4
5
6
7
8
9
10
11# DataLoader.next源代码
class DataLoader(object):
...
def __next__(self):
if self.num_workers == 0:
indices = next(self.sample_iter) # Sampler
batch = self.collate_fn([self.dataset[i] for i in indices]) # Dataset
# 数据拷贝至显卡
if self.pin_memory:
batch = _utils.pin_memory.pin_memory_batch(batch)
return batch
Pytorch 数据整合函数 collate_fn?
- collate_fn 的作用就是将一个 batch 的数据进行合并操作。默认的 collate_fn 是将 img 和 label 分别合并成 imgs 和 labels,所以如果你的__getitem__方法只是返回 img, label, 那么你可以使用默认的 collate_fn 方法
- 如果你每次读取的数据有 img, box, label 等等,那么你就需要自定义 collate_fn 来将对应的数据合并成一个 batch 数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34def collate_fn(batch):
batch.sort(key=lambda x: len(x[1]), reverse=True)
img, label = zip(*batch)
pad_label = []
lens = []
max_len = len(label[0])
for i in range(len(label)):
temp_label = [0] * max_len
temp_label[:len(label[i])] = label[i]
pad_label.append(temp_label)
lens.append(len(label[i]))
return img, pad_label, lens
custom_loader = DataLoader(dset, batch_size=8, shuffle=True, collate_fn=collate_fn)
img, label, lens = custom_loader.__iter__().__next__()
# img内容
#('./train/img/520_7.png',
#'./train/img/977_36.png',
#'./train/img/2205_1.png',
#'./train/img/697_15.png',
#'./train/img/552_2.png',
#'./train/img/529_12.png',
#'./train/img/238_4.png',
#'./train/img/2600_2.png')
# label内容
#[['D', 'E', 'F', 'I', 'N', 'I', 'T', 'I', 'O', 'N'],
#['G', 'E', 'R', 'I', 'E', 'W', 'E', 0, 0, 0],
#['M', 'O', 'R', 'T', 'O', 'N', 0, 0, 0, 0],
#['Y', 'O', 'U', 'R', 0, 0, 0, 0, 0, 0],
#['C', 'O', 'M', 0, 0, 0, 0, 0, 0, 0],
#['9', '3', '0', 0, 0, 0, 0, 0, 0, 0],
#['1', 0, 0, 0, 0, 0, 0, 0, 0, 0],
#['G', 0, 0, 0, 0, 0, 0, 0, 0, 0]]
# lens内容
# [10, 7, 6, 4, 3, 3, 1, 1]
Pytorch 数据整合函数 collate_fn 与数据采样函数的关系?
- 采样器 sampler/batch_sampler 返回的都是样本索引,collate_fn 的输入是批量大小的样本列表。所以在传给 collate_fn 前要根据索引取样本
1
2
3
4
5
6
7
8# may-style
for indices in batch_sampler:
yield collate_fn([dataset[i] for i in indices])
# iterable-style
# iterable-style的索引其实是没用的,只是用来控制采样的个数。同时,能看到collatefn函数的输入参数是样本列表(长度为batch_size)
dataset_iter = iter(dataset)
for indices in batch_sampler:
yield collate_fn([next(dataset_iter) for _ in indices])
Pytorch 的 Dataloader 参数 pin_memory=True 加速训练的原理?

- GPU 是没法直接读取 pageable 内存里的数据的,所以需要先创建一个临时的缓冲区(pinned memory),把数据从 pageable 内存拷贝 pinned 内存上,然后 GPU 才能从 pinned 内存上读取数据,但是将数据从 pageable 内存拷贝到临时的 pinned 内存是有时间开销的,从一开始就把一部分内存给锁住,这样一来就减少了 Host 内部的开销,避免了 CPU 内存拷贝时间
- 虚拟内存: 使用部分磁盘空间代替内存的过程,其中虚拟内存被划分为很多页,它们是寻址的单元,页的大小至少是 4096 个字节
- 换出内存: 如果某页的物理内存被标记为 ** 换出状态,** 那么该页被踢出内存,如果下次需要该页时,需要重新加载到内存上,消耗时间
- ** 锁页 (pinned page) 操作:** 标记内存中的某些页不可被换出,下次需要直接访问即可
Pytorch 的 Dataloader 参数 num_worker 的作用?
- 表示 Dataloader 一次创建多少个 worker (worker 是工作进程),先
batch_sampler将指定 batch 分配给指定 worker,worker 将它负责的 batch 加载进 RAM - num_workers=0 表示只有主进程去加载 batch 数据,这个可能会是一个瓶颈
- num_workers = 1 表示只有一个 worker 进程用来加载 batch 数据,而主进程是不参与数据加载的。这样速度也会很慢
num_worker设置得大,好处是寻 batch 速度快,因为下一轮迭代的 batch 很可能在上一轮 / 上上一轮… 迭代时已经加载好了。坏处是内存开销大,也加重了 CPU 负担(worker 加载数据到 RAM 的进程是 CPU 复制的嘛)
如何使用 torchvision 构建常用数据集的 Dataset?
- 使用 torchvision.datasets 即可
1
2
3
4
5
6
7
8
9
10
11
12# 1.利用torchvision加载常见数据
>>> datasets=torchvision.datasets.MNIST(root='../ConvertMnist/mnist_data',download=True,train=True,transform=torchvision.transforms.ToTensor())
# 2.初始化Dataloader
>>> dataloader=torch.utils.data.DataLoader(datasets,batch_size=16,shuffle=True)
>>> for batch in dataloader:
... data,label=batch
... print(data.shape,label.shape)
... print(label)
... break
...
torch.Size([16, 1, 28, 28]) torch.Size([16])
tensor([2, 2, 1, 1, 3, 5, 4, 4, 5, 1, 7, 2, 6, 6, 9, 6])
如何在数据集上使用 ImageFolder 构建 Datasets 实例?
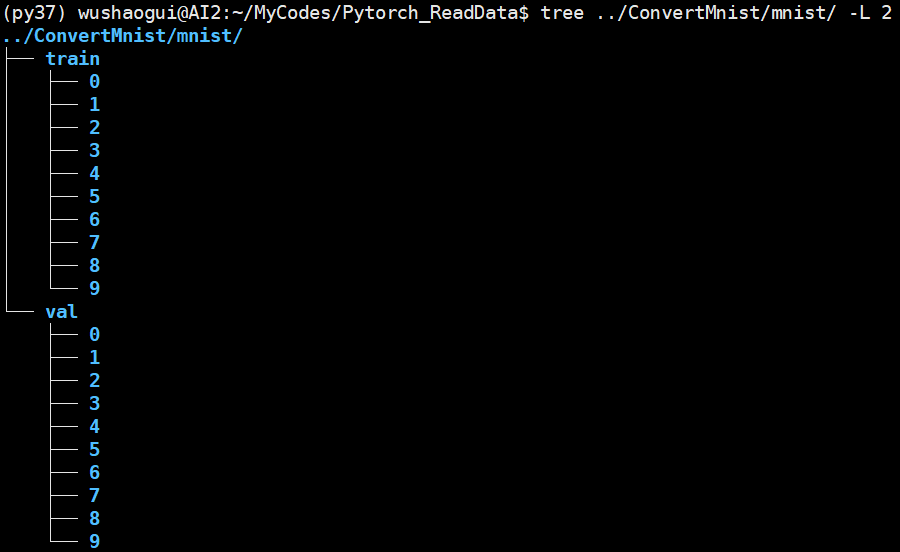
- 第一步:确保数据按照:** 文件夹 / 类别 1 子文件夹,类别 2 子文件夹,…]** 的方式排列
![Pytorch读取数据-20250117150137]()
- 第二步:直接使用 ImageFolder 读取文件夹
1
2
3
4
5
6
7
8
9
10
11
12
13# 1.利用torchvision的ImageFolder加载常见数据
root_dir='../ConvertMnist/mnist/'
datasets=torchvision.datasets.ImageFolder(root=root_dir,transform=torchvision.transforms.ToTensor())
# 2.初始化Dataloader
dataloader=torch.utils.data.DataLoader(datasets,batch_size=16,shuffle=True)
for batch in dataloader:
data,label=batch
print(data.shape,label.shape)
print(label)
break
torch.Size([16, 3, 28, 28]) torch.Size([16])
tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1])
如何在数据集上自定义 Datasets 类?
- 第一步:继承并实现 torch.utils.data.Dataset 类
1
2
3
4
5
6
7class MyMapDataset(torch.utils.data.Dataset):
def __init__(self,data):
self.data=data
def __getitem__(self,idx):
return self.data[idx]
def __len__(self):
return len(self.data) - 第二步:初始化 Dataloader
1
2
3
4
5
6
7
8>>> data=list(range(0,12)) #[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
>>> dataset=MyMapDataset(data)
>>> dataloader=torch.utils.data.DataLoader(dataset,batch_size=4)
>>> for batch in dataloader:
... print(batch)
tensor([0, 1, 2, 3])
tensor([4, 5, 6, 7])
tensor([ 8, 9, 10, 11])
如何在数据集上自定义 IterableDataset 类?
- 第一步:继承并实现 torch.utils.data.IterableDataset
1
2
3
4
5class MyIterableDataset(torch.utils.data.IterableDataset):
def __init__(self,data):
self.data=data
def __iter__(self):
return iter(self.data) - 第二步:初始化 Dataloader
1
2
3
4
5
6
7
8>>> data=list(range(0,12)) #[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
dataset=MyIterableDataset(data)
dataloader=torch.utils.data.DataLoader(dataset,batch_size=4)
for batch in dataloader:
... print(batch)
tensor([0, 1, 2, 3])
tensor([4, 5, 6, 7])
tensor([ 8, 9, 10, 11])
参考: