YOLOv4:Optimal Speed and Accuracy of Object Detection
YOLOv4 在 YOLOv3 的基础上进行大量的 trick 改进,包括使用 CSPDarkNet53,PAN 等网络
什么是 YOLOv4?
![]()
- 在 YOLOv4 中 CSPDarknet53 作为 BackBone 和空间金字塔池化 (SpatialPyramidPooling,SPP) 块用于增加感受野,将显着特征分离,并没有降低网络运行速度;PAN 用于来自不同主干级别的参数聚合 YOLOv3 头用于预测头
- 改进网络 CSPDarknet53、SPP、PAN、DropBlock 正则化、CmBN (Crossmini-BatchNormalization)
- 改进数据预处理 Mixup 数据增强、标签平滑 (Classlabelsmoothing)
- 改进模型训练 CIOU loss、自我对抗训练 SAT (Self-adversarial-training) 数据增强
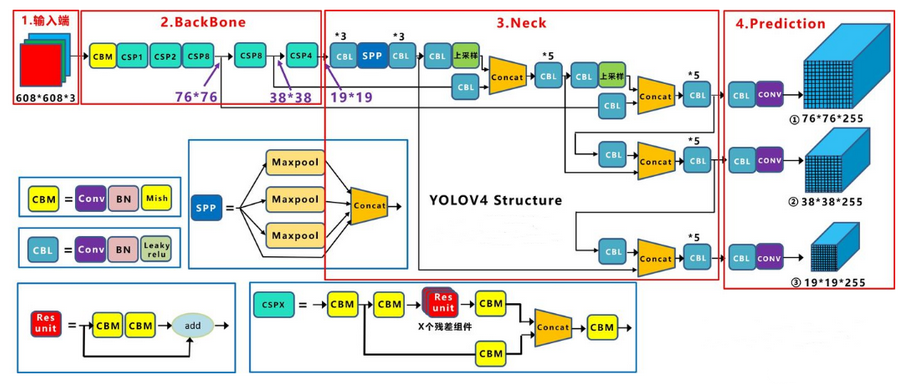
YOLOv4 的网络结构?
![]()
- 输入:608x608x3 的图片
- 输出:3 个输出,76x76x255、38x38x255、19x19x255,其中 YOLOv3 网络结构含义一致,表示每个网格使用 3 个先验框,每个先验框计算置信度 (1)、位置 (4)、类别 (80)
- YOLOv4 = CSPDarknet53+ 空间金字塔池化 (SpatialPyramidPooling,SPP)+ PAN+ YOLOv3 的检测头
YOLOv4 的正负样本判定?
- YOLOv1-YOLOv3 均采取 single-anchor (1 个真实框分配 1 个先验框进行预测) 的方式,而 YOLOv4 采用 multi-anchor (1 个真实框分配多个先验框进行预测)
- 正负样本判定: 只要真实框与某个先验框的 IOU 大于阈值,该先验框就是正样本,反之是负样本,不再考虑忽略样本
YOLOv4 如何制作正样本?
- YOLOv4 使用 YOLOv3 的检测头,因此其正样本制作方式 YOLOv3 制作正样本制作方式一样
YOLOv4 的损失函数?
- YOLOv3 损失函数 box 位置损失替换 CIoU loss ,其他部分的损失一样
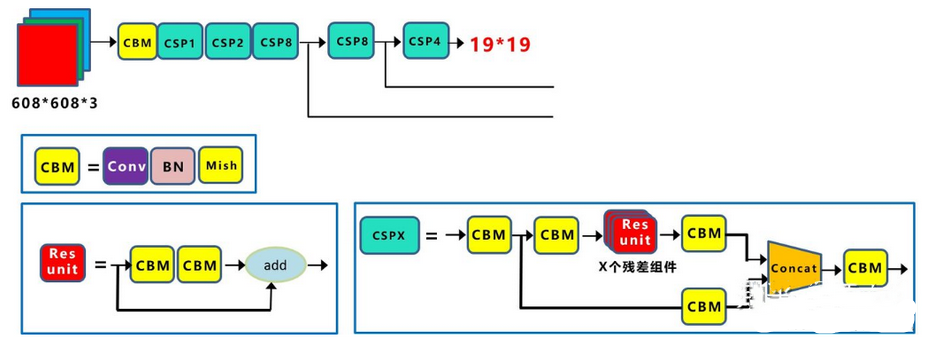
YOLOv4 的主干网络 CSPDarknet53?
- CSPDarknet53 是 YOLOv3 主干网 Darknet-53 的基础上,借鉴 CSPNet (Cross-Stage-Partial-connections) 的经验产生的
![]()
- CBM: Yolov4 网络结构中的最小组件,由 Conv+Bn+Mish 激活函数三者组成
- CSPX: 借鉴了 CSPNet 网络结构,由 CBM 组件和 X 个 Res unint 模块 Concate 组成
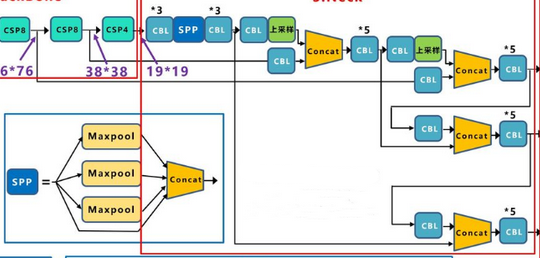
YOLOv4 的颈部网络组成?
- 特征增强模块,主要由 CBL 组件,SPP 模块和 FPN+PAN 的方式组成
![]()
- CBL 组件: Conv+Bn+Leaky_relu 激活函数三者组成
- 空间金字塔池化 (SpatialPyramidPooling,SPP): 采用 1×1,5×5,9×9,13×13 的最大池化的方式,进行多尺度融合
- PAN: FPN 层自顶向下传达强语义特征,而 PAN 则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合,加速了不同尺度特征的融合,进一步提高特征提取的能力
YOLOv4 的 Bag of freebies 有哪些?
- 用于 backbone: Mosaic 数据增强,DropBlock 正则化,标签平滑 (Classlabelsmoothing)
- 用于检测器的 BoF:CIOU loss,CmBN (Crossmini-BatchNormalization),DropBlock 正则化,Mosaic 数据增强,自我对抗训练 SAT (Self-adversarial-training) 数据增强,消除网格敏感性,对单个 ground-truth 使用多个 anchor,学习率余弦衰减,最佳超参数,Random training shapes
YOLOv4 的 Bag of specials 有哪些?
- 用于 backbone 的 BoS: 激活函数 Mish,CSPNet,多输入加权残差连接 (Weighted-Residual-Connections,MiWRC)
- 用于检测器的 Bos: 激活函数 Mish,SPPNet,CBAM 的通道注意力模块(ChannelAttentionModule,CAM),PAN ,DIOU Loss
YOLOv4 为什么要进行 Mosaic 数据增强呢?
- 小目标的 AP 一般比中目标和大目标低很多。而 Coco 数据集中小目标占比达到 41.4%,数量比中目标和大目标都要多。但在所有的训练集图片中,只有 52.3% 的图片有小目标,而中目标和大目标的分布相对来说更加均匀一些