YOLOv3:An Incremental Improvement
YOLOv3 借鉴特征金字塔网络 (FeaturePyramidNetwork,FPN) 思想,小尺寸特征图 (深层特征) 用于检测大尺寸物体,而大尺寸特征图 (浅层特征) 检测小尺寸物体,实现效果提升
什么是 YOLOv3?
![]()
- 无论是 YOLOv1,还 YOLOv2,都有一个共同的致命缺陷:只使用了最后一个经过 32 倍降采样的特征图(简称 C5 特征图)。尽管 YOLOv2 使用了 passthrough 技术将 16 倍降采样的特征图(即 C4 特征图)融合到了 C5 特征图中,但最终的检测仍是在 C5 尺度的特征图上进行的,最终结果便是导致了模型的小目标的检测性能较差
- YOLOv3 通 Darknet-53 主干网络,借鉴特征金字塔网络 (FeaturePyramidNetwork,FPN) 思想,小尺寸特征图 (深层特征) 用于检测大尺寸物体,而大尺寸特征图 (浅层特征) 检测小尺寸物体,实现效果提升
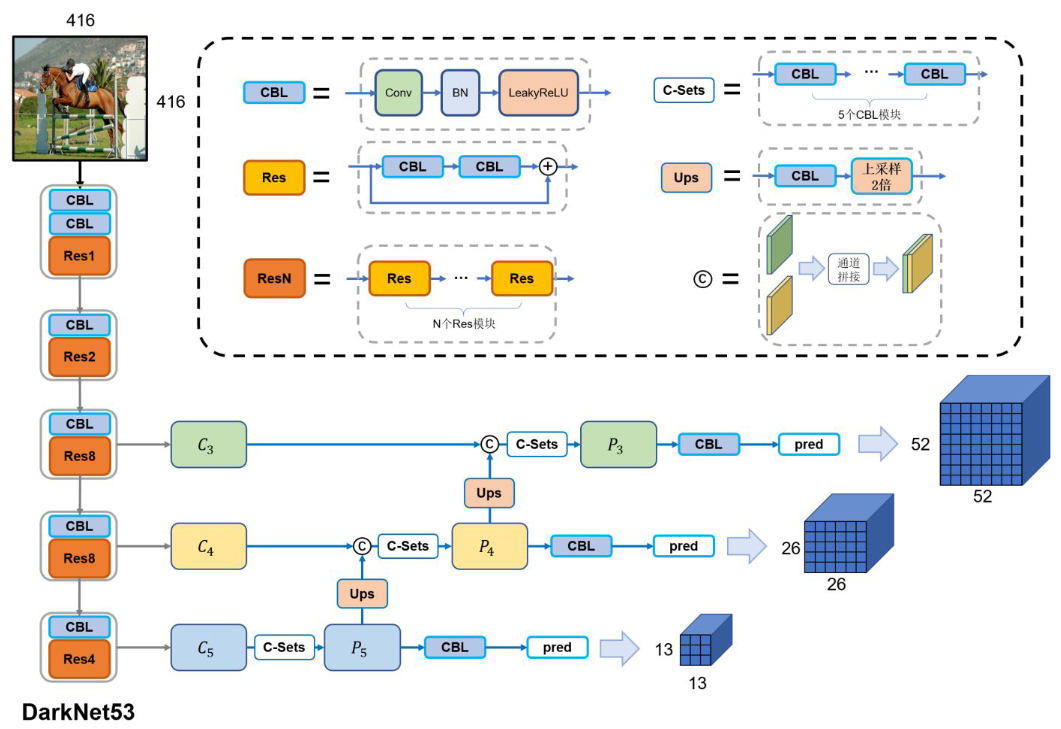
YOLOv3 的网络结构?
![]()
- 输入:416 x 416 x 3 的图片
- 输出:三个输出,分布是 13x13x255、26x26x255、52x52x255,每个输出表示对不同感受野的特征图做目标检测,255 (3x85) 是每个网格使用 3 个先验框,每个先验框计算置信度 (1)、位置 (4)、类别 (80)
YOLOv3 的正负样本判定?
- YOLOv3 同样使用锚框的概念,根据先验框和 gt 框的 IOU 确定正负样本,每个 gt 框分配一个预测框
- 位置判定正负样本: 但是 YOLOv3 引入 multi-head 预测,不能再按照 “映射中心” 的方法给 gt 框分配先验框,因此使用 gt 框与所有先验框的 IOU 来分配先验框
- 正样本: 任取一个 gt 框,与所有 head 的先验框计算 IOU,IOU 最大的预测框为正例。并且一个预测框,只能分配给一个 ground truth。例如第一个 ground truth 已经匹配了一个正例检测框,那么下一个 ground truth,就在余下的 4031 个检测框中,寻找 IOU 最大的检测框作为正例,ground truth 的先后顺序可忽略
- 负样本: 正例除外,与全部 ground truth 的 IOU 都小于阈值,则为负例
- 忽略样本: 正例除外,与任意一个 gt 框的 IOU 大于阈值,则为忽略样例
YOLOv3 多 head 情况下如何分配正样本?
![]()
- 在 Yolov3 的训练策略中,不再像 YOLOv1、YOLOv2 那样,每个 cell 负责中心落在该 cell 中的 ground truth。原因是 Yolov3 一共产生 3 个特征图,3 个特征图上的 cell,中心是有重合的
- 训练时,可能最契合的是特征图 1 的第 3 个 box,但是推理的时候特征图 2 的第 1 个 box 置信度最高。所以 Yolov3 的训练,不再按照 ground truth 中心点,严格分配指定 cell,而是根据预测值寻找 IOU 最大的预测框作为正例

YOLOv3 的损失函数?
- 置信度损失: 计算正、负样本的损失
- 位置损失
- 分类损失: 使用 sigmoid 激活函数替代 YOLOv2 中的 softmax,取消了类别之间的互斥,可以使网络更加灵活
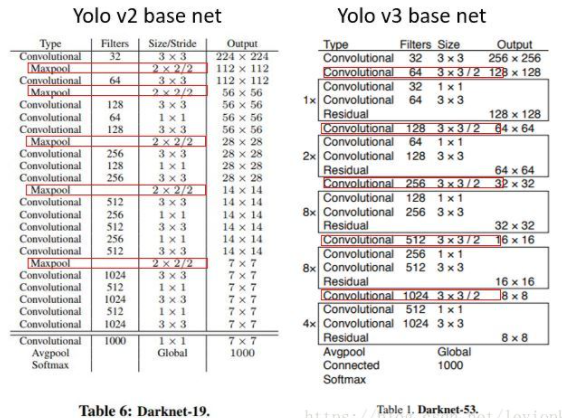
YOLOv3 中的 Darknet53?
![]()
- 在 YOLOv2 使用 Darknet19 基础上加深网络,并且借鉴 ResNet 的思想,添加了大量残差块 (residual block),模型的最大池化层也改为 stride=2 的卷积来实现
YOLOv1、YOLOv2、YOLOv3、YOLOv4、YOLOv5 设置先验框的区别?
- YOLOv1:没有设置先验框,而是使用 2 个框(任意框)直接回归框位置
- YOLOv2:生成及设置先验框:通过聚类得到 5 个先验框,为每个网格放置 5 个先验框,使用 Kmeans 聚类:通过聚类得到 9 个先验框,(10×13),(16×30),(33×23),(30×61),(62×45),(59× 119), (116 × 90), (156 × 198),(373 × 326) ,每个尺度的网格放置 3 个先验框
- YOLOv3:按照 "小尺寸特征图 (深层特征) 用于检测大尺寸物体,而大尺寸特征图 (浅层特征) 检测小尺寸物体" 的思想,前 3 个先验框使用为 52x52 使用;中间 3 个先验框为 26x26 使用;最后 3 个先验框为 13x13 使用
- YOLOv4:YOLOv3 一致
- YOLOv5:在开始训练之前对数据集核查,计算此数据集针对默认锚定框的最佳召回率,当最佳召回率大于或等于 0.98,则不需要更新锚定框;如果最佳召回率小于 0.98,则需要重新计算此数据集的锚定框