YOLOv5
在 YOLOv4 的基础上添加了一些新的改进思路,网络做成了可选择配置的方式
什么是 YOLOv5?
- 在 YOLOv4 的基础上添加了一些新的改进思路,网络做成了可选择配置的方式,分为 Yolov5s、Yolov5l、Yolov5s、Yolo5x 等版本
- 输入端: 在模型训练阶段,提出了一些改进思路:Mosaic 数据增强、自适应锚框计算、自适应图片缩放
- 基准网络: 融合其它检测算法中的一些新思路,主要包括:Focus 结构、快速金字塔池化 (SpatialPyramidPooling-Fast,SPPF)
- Neck 网络: 目标检测网络在 BackBone 与最后的 Head 输出层之间往往会插入一些层,Yolov5 中添加特征金字塔网络 (FeaturePyramidNetwork,FPN)、PANet
- Head 输出层: 输出层的锚框机制与 YOLOv4 相同,主要改进的是训练时的损失函 深度学习的损失函数 #|GIOU loss,以及预测框筛选目标检测基础知识 #|DIOU-NMS
YOLOv5 的网络结构?
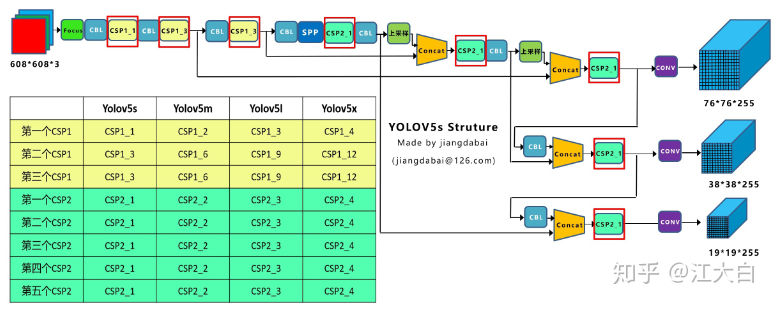
![]()
- 输入:608x608 输出多尺度预测结果:19x19/38x38/76x76
- 网络中的 1、2、3、4、5、6 分别时组成 YOLOv5 的基础组件,即:CBL 模块、Res 模块、CSP1_X、CSP1_X、Focus 结构、SPPF
- YOLOv5 使用了 2 类 CSPNet 结构,CSP1_X 和 CSP2_X,前者用于 BackBone,由 CBL+Res+Concate 组成,后者用于 Neck,由卷积 + Res+Concate 组成
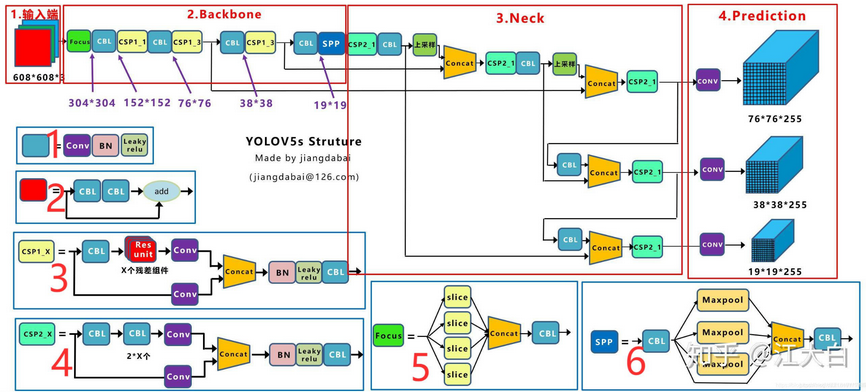
YOLOv5 的 Focus 结构?
![]()
和 YOLOv2 使用传递层(passthroughlayer)相似,通过 slice 操作来对输入图片进行裁剪。原始输入图片大小为 608 * 608 * 3,经过 Slice 与 Concat 操作之后输出一个 304 * 304 * 12 的特征映射;接着经过 Conv 层
Focus 结构可以扩大感受野,提升对大尺度目标的预测能力
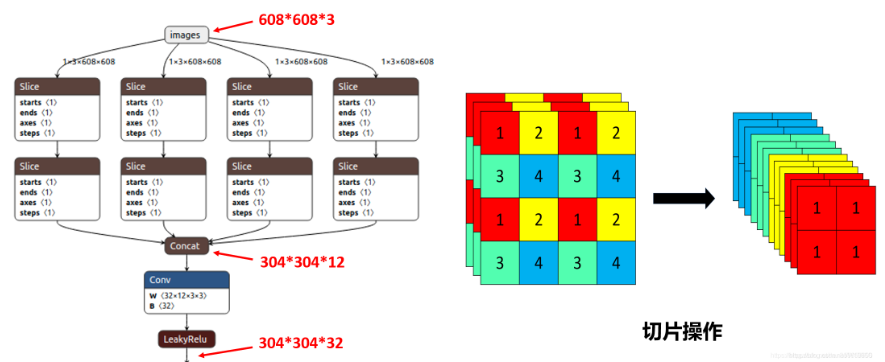
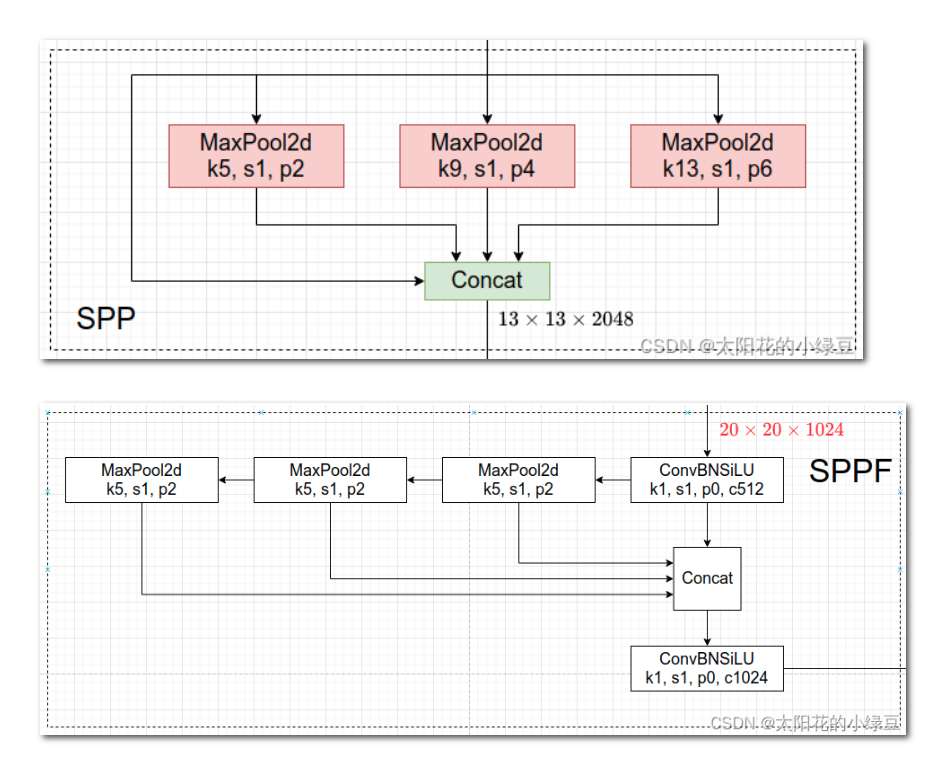
什么是快速金字塔池化 (Spatial Pyramid Pooling - Fast, SPPF) 结构?
![]()
- YOLOv5 改空间空间金字塔池化 (SpatialPyramidPooling,SPP) 得到,主要思想是:将输入串行通过多个不同大小的 MaxPool,然后做进一步融合,两者的作用是一样的,但后者效率更高
- SPPF 结构是将输入串行通过多个 5x5 大小的 MaxPool 层,这里需要注意的是串行两个 5x5 大小的 MaxPool 层是和一个 9x9 大小的 MaxPool 层计算结果是一样的,串行三个 5x5 大小的 MaxPool 层是和一个 13x13 大小的 MaxPool 层计算结果是一样的
1 | class SPPF(nn.Module): |
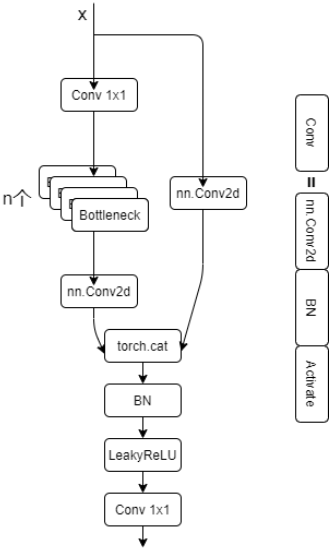
什么是 BottleneckCSP?
- Bottleneck 结构 CSPNet 结合,形成 CSP 瓶颈层
![]()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(BottleneckCSP, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k=1)
self.cv2 = nn.Conv2d(c1, c_, kernel_size=1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, kernel_size=1, bias=False)
self.cv4 = Conv(2 * c_, c2, k=1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.LeakyReLU(0.1, inplace=True)
self.m = nn.Sequential([Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
YOLOv5 的自适应锚框计算原理?
- 在开始训练之前对数据集核查,计算此数据集针对默认锚定框的最佳召回率,当最佳召回率大于或等于 0.98,则不需要更新锚定框;如果最佳召回率小于 0.98,则需要重新计算此数据集的锚定框
- 1)载入数据集,得到数据集中所有数据的 wh
- 2)将每张图片中 wh 的最大值等比例缩放到指定大小 img_size,较小边也相应缩放
- 3)将 bboxes 从相对坐标改成绝对坐标(乘以缩放后的 wh)
- 4)筛选 bboxes,保留 wh 都大于等于两个像素的 bboxes
- 5)使 K-Means 聚类得到 n 个 anchors(K-Means 算法涉及一个白化操作)
- 6)使遗传算法随机对 anchors 的 wh 进行变异,如果变异后效果变得更好(使用 anchor_fitness 方法计算得到的 fitness(适应度)进行评估)就将变异后的结果赋值给 anchors,如果变异后效果变差就跳过,默认变异 1000 次
YOLOv5 的自适应图片缩放原理?
- 训练阶段―
- 直接按比例缩放并填充
![]()
- 直接按比例缩放并填充
- 测试阶段―
- 第一步:计算缩放比例
![]()
- 第二步:计算缩放后的尺寸
![]()
- 第三步:计算黑边填充数值,网络进行了 5 倍下采样,网络填充部分能被 32 整除的部分到最后也是背景,不被 32 整除部分可能参与预测
![]()
- 注意: YOLOv3 与 YOLOv4 中默认填充的数值是 (0,0,0),而 YOLOv5 中默认填充的数值是 (114,114,114)
- 第一步:计算缩放比例




YOLOv5 正样本的匹配策略?
- YOLOv5 使用 3 种方法增加正样本数量
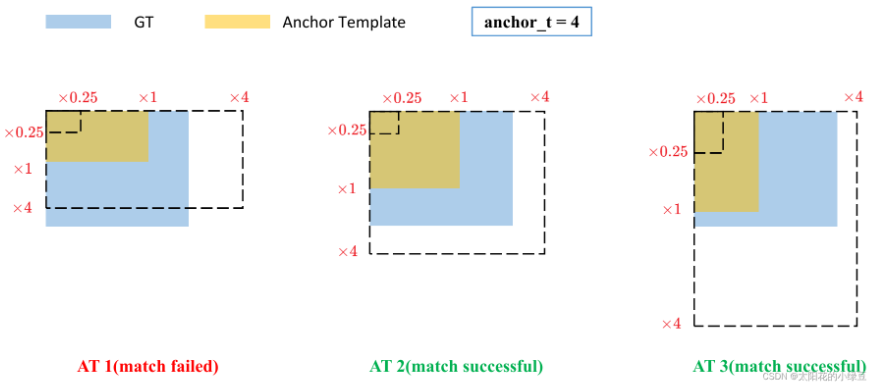
- 1)跨 anchor 预测: 不同于 IOU 匹配,yolov5 采用基于宽高比例的匹配策略,GT 框和先验框宽高相除得 ratio1,先验框与 GT 的宽高相除得到 ratio2,取 ratio1 和 ratio2 的最大值作为最后的宽高比,该宽高比和设定阈值(默认为 4)比较,小于设定阈值的 anchor 则为匹配到的 anchor”
![]()
- 2)跨 grid 预测: GT 框中心点处于 grid1 中,grid1 被选中,为了增加增样本,grid1 的上下左右 grid 为候选网格,因为 GT 中心点更靠近 grid2 和 grid3,grid2 和 grid3 也作为匹配到的网格,根据上步的 anchor 匹配结果,GT 与 anchor2、anchor3 相匹配,因此 GT 在当前层匹配到的正样本有 6 个,分别为: grid1_anchor2,grid1_anchor3,grid2_anchor2,grid2_anchor3,grid3_anchor2, grid3_anchor3
![]()
- 3)跨分支预测: 假设一个 GT 框可以和 2 个甚至 3 个预测分支上的 anchor 匹配,则这 2 个或 3 个预测分支都可以预测该 GT 框, 即一个 GT 框可以由多个预测分支来预测,重复 anchor 匹配和 grid 匹配的步骤,可以得到某个 GT 匹配到 的所有正样本

YOLOv5 损失函数?
- 分类损失: 采用的二值交叉熵损失 BCELoss,注意只计算正样本的分类损失
- obj 损失: 采用的依然是 BCE loss,注意这里的 obj 指的是网络预测的目标边界框与 GT Box 的 CIoU loss。这里计算的是所有样本的 obj 损失
- 定位损失: 采用的是 GIoU loss,注意只计算正样本的定位损失
- 三个预测特征层(P3, P4, P5)上的 obj 损失采用不同的权重。在源码中,针对预测小目 标的预测特征层(P3)采用的权重是 4.0,针对预测中等目标的预测特征层(P4)采用的权重是 1.0,针 对预测大目标的预测特征层(P5)采用的权重是 0.4