深度学习显存占用及计算量分析
本文分析了深度学习在训练、推理时的显存占用,主要包括:网络参数值、网络参数梯度值、输入 + 每层输出、优化器参数
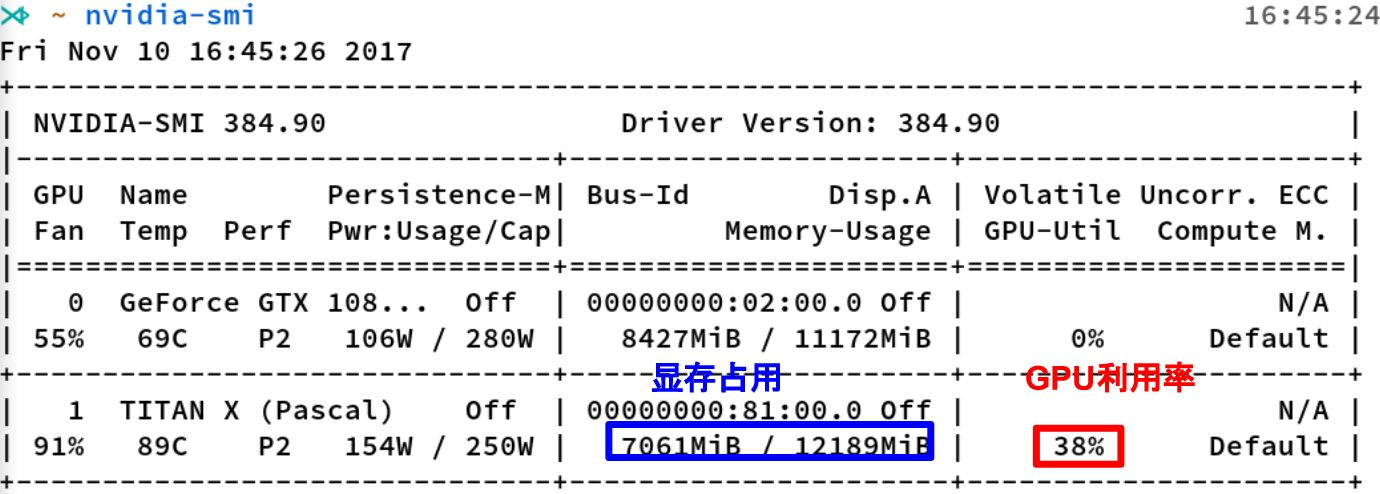
如何查看 Nvidia 显卡的资源使用情况?
![]()
- nvidia-smi 是 Nvidia 显卡命令行管理套件,基于 NVML 库,旨在管理和监控 Nvidia GPU 设备
- 显存占用和 GPU 利用率是两个不一样的东西,显卡是由 GPU 计算单元和显存等组成的,显存和 GPU 的关系有点类似于内存和 CPU 的关系
操作系统中,显存与内存的区别?
![]()
- 内存单位 K 、 M , G , T 是以 1024 为底,而显存单位 KB 、 MB , GB , TB 以 1000 为底。不过一般来说,在 估算显存大小的时候,我们不需要严格的区分这二者
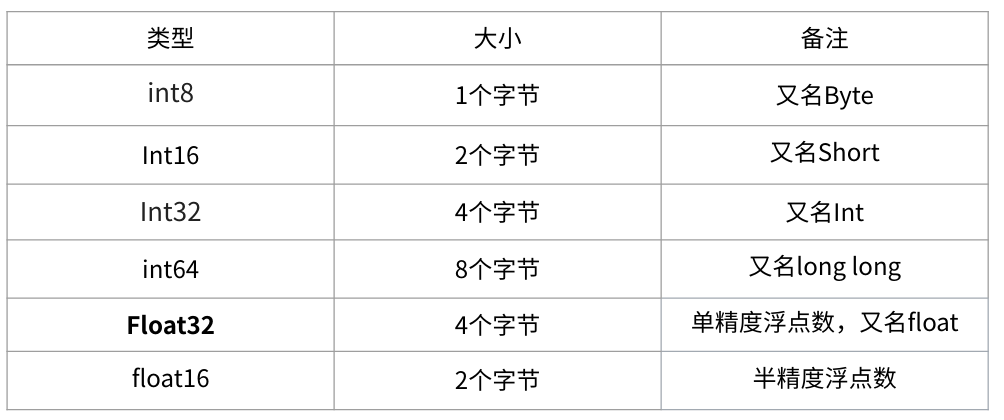
- 在深度学习中会用到各种各样的数值类型,数值类型命名规范一般为 TypeNum ,比如 Int64、 Float32、Double64
- 有一个 1000x1000 的 矩阵,float32,那么占用的显存差不多就是: 1000x1000x4 Byte = 4MB
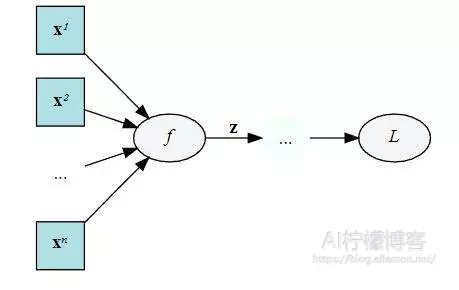
神经网络训练时,哪些部分会占用显存?
- 网络模型占用: 主要指网络中有参数的层,即神经网络中 “有参数的层” 如何占用显存?
- 模型输入及输出: 训练过程中的中间变量指训练过程需要保存每一层输入输出的中间变量,一般后续反向传导,更新梯度
- 优化器的参数: 除了保存权重之外,还要保存对应的梯度,用于梯度更新,尤其对哪些需要记录历史梯度、自适应学习率的优化器来说
- 框架自身的显存开销
神经网络推理时,哪些部分会占用显存?
- “不可控制空间” 指系统分配的空间,如每个进程 CUDA Context 所占用的显存空间,一般在 100-300MB 左右;
- “输入输出” 指用户自行分配的显存空间,如模型输入输出 Tensor 占用的空间,即神经网络中 “输入与输出” 如何占用显存?
- “模型参数” 指训练的深度学习模型的参数所占用的显存空间,我们需要将模型参数加载到显存中,才能进行计算,即神经网络中 “有参数的层” 如何占用显存?
- “运行时空间” 是指模型的算子在计算的时候,需要的显存空间
神经网络中 “输入与输出” 如何占用显存?
![]()
在训练阶段, 保存模型每一层输出的特征图。(因为反向传播中需要对中间层的特征图求导,所以中间层的输出特征图不会被释放)
但是在某些特殊的情况下, 我们可以不要保存输入。比如 ReLU,在 PyTorch 中,使用 nn.ReLU (inplace = True) 能 将激活函数 ReLU 的输出直接覆盖保存于模型的输入之中,节省不少显存
神经网络中 “有参数的层” 如何占用显存?
![]()
- 参数占用显存 = 参数数目 ×n,其中 n 为参数数据类型,如 float32 时,n=4
- 网络模型的占用的显存主要是来自于所有有参数的层,包括:卷积、全连接、BN 等;而不 占用显存的有:激活函数、池化层以及 Dropout 等
- 模型参数的显存占用与 batchsize 无关,但是在训练阶段与优化器有关

神经网络中 “梯度及动量” 如何占用显存?
![]()
在训练阶段, dz/dx 这个中间值当然要保留下来以用于计算反向传播更新参数值,所以每个参数都需要存储梯度。所以模型参数 的显存占用,与采用的优化器有关
1)如果使用 SGD,需要 2 倍模型参数的显存占用,模型参数 + 模型参数的梯度
2)如果使用 SGD+Momentum,需要 3 倍的模型参数显存占用,模型参数 + 梯度 + 动量
3)如果使用 Adam,需要 4 倍的显存占用,模型参数 + 梯度 + 动量 + 二阶动量
如何减少显存占用?
- 占用显存较多的部分是卷积层输出的特征图,模型参数的显存占用较少
- (1) 减少模型输入尺寸:输入的尺寸不仅仅影响第一层的显存占用,而是每一层的显存占用,参考:神经网络中 “输入与输出” 如何占用显存?
- (2) 减小 batchsize:除去模型的显存占用部分,显存占用和 batchsize 成正比
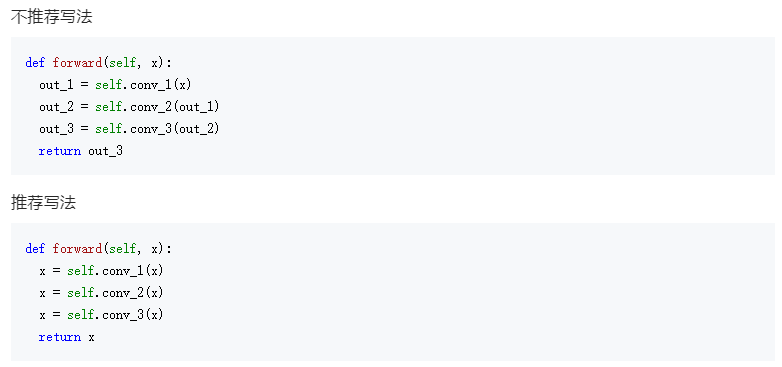
- (3) 尽量使用 Inplace:在 PyTorch 中,inplce 操作指的是改变一个 tensor 值的时候,不经过复制操作而是直接在原来的内 存上修改它的值,也就是原地操作。
- (4) 尽量少产生中间结果: 不需要的中间变量尽可能的都是用一个变量来代替,因为这些变量都是会占用显存的
![]()
- (5) 不要使用过大的全连接: 相比于卷积的参数,全连接的参数量可就大多了。因为卷积只是一个局部的连接,而全连接则是 一个全局的连接
- (6) 使用 checkpoint: PyTorch 在 0.4 版本后推出了一个新功能,可以将一个模型的计算过程分为两半。也就是说,如果 一个模型训练需要占用的显存太大,可以先计算网络的一半,保存后半部分所需要的中奖结果, 再计算后半部分。当然,这样的操作显然是一个牺牲时间换空间的方法
![]()
- (7) 梯度累加: 大多数情况下,其实我们降低显存就是为了获得更大的 Batchsize,因此使用 gradient accumulation(梯度累加)也可以达到类似的效果
![]()
- (8) 降低计算精度: 在 PyTorch1.6 之前,降低训练进度普遍使用的都是 NVIDIA 提供的 apex 库。而在 1.6 版本之后, PyTorch 推出了 AMP(Automatic mixed precision),自动混合精度训练。这套技术并不是简单的 将所有的参数降低精度,而是根据不同向量的不同操作对于误差的敏感程度来决定其使用的是 FP16 还是 FP32


如何减少卷积层的计算量?
- (1) 卷积核的分解(空间可分离卷积 (Spatial Separable Convolutions)): 用两个 33 的卷积堆叠代替一个 77 的卷积(达到相同的感受野)
- (2) 深度可分离卷积(深度可分离卷积 (depthwise separable convolution)): 先进行 Deepwise 卷积操作,再进行 Pointwise 卷积操作,以空间换取时间,因为显存占用变多 (每一步的输出都要保存)
为什么神经网络训练时 GPU 利用率忽高忽低?
- Volfine GPU-Util 所说的,当 CPU 线程数未设置时,此参数反复跳动,0%,20%,70%, 95%,0%。 这休息 1-2 秒,然后重复。 事实上, GPU 正在等待从 CPU 传输数据。GPU 从总线 传输到 GPU 后,GPU 逐渐开始计算,利用率会突然提高。但是,GPU 非常强大,基本上可以在 0.5 秒内处理数据。然后利用率将再次下降,等待下一批进入。 因此,GPU 利用率瓶颈在于内存 带宽和内存介质,以及 CPU 的性能
- 对于这个问题,解决方案是增加 DataLoader 的 num_wokers 数量,主要是增加子线程的数量,分 担主线程的数据处理压力,以及多线程协作处理和传输数据,而不是负责一个线程中的所有预处 理和传输任务