DB:Real-time Scene Text Detection with Differentiable Binarization
是一个基于分割的自然场景分本检测模型,通过设计一个 “可微的二值化模块 (DB)” 替换语义分割的后处理,使得每个像素可以使用可学习、自适应的阈值去二值化
什么是 DB ?
![]()
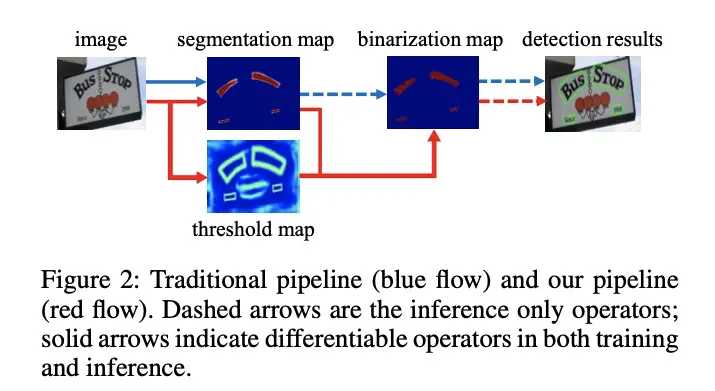
- 传统意义二值化:基于分割的文本检测算法其流程如图 2 中的蓝色箭头所示。在传统方法中得到分割结果之后采用一个固定阈值得到二值化的分割图
- DB 二值化:如图 2 中红色箭头所示的,通过网络去预测图片每个位置处的阈值,而不是采用一个固定的值,这样就可以很好将背景与前景分离出来,但是这样的操作会给训练带来梯度不可微的情况,对此对于二值化提出了一个叫做 Differentiable Binarization 模块 来解决
DB 的网络结构?
![]()
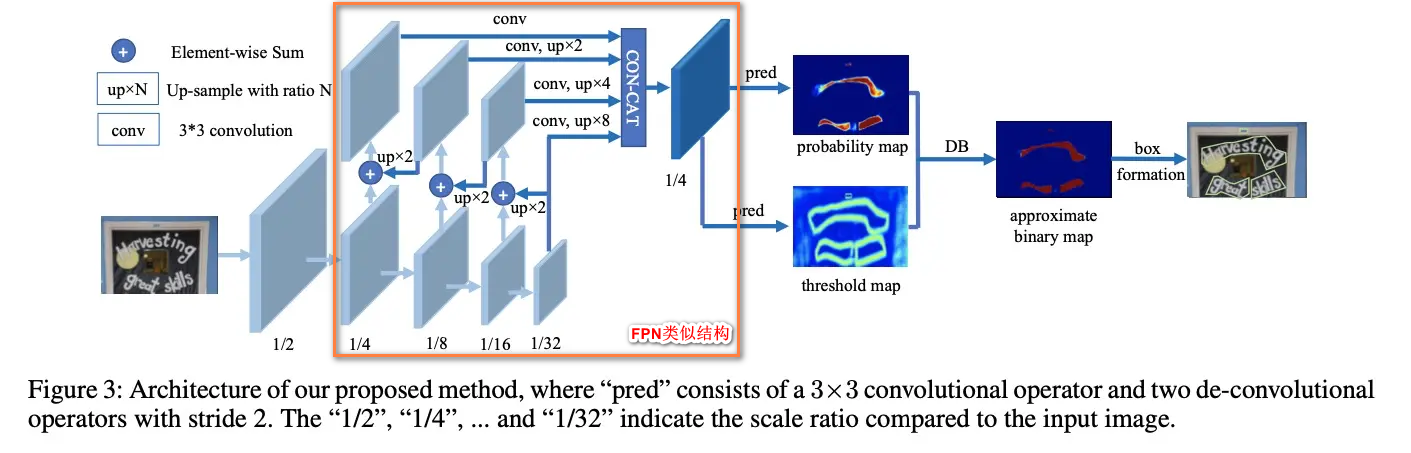
- BackBone:可以使用类似 resnet 下采样 5 次,得到 5 个层次的特征
- FPN 类似结构:对 C4、C3、C2 特征采样类似 FPN 的连接,输出时是 C5、 F4、F3、F2 一共 4 个层次的特征
- DB 模块:以 probability map 减去 threshold map (T) 差值,输入到 DB 模块进行可微的二值化学习
DB 的 “可微的二值化模块 (DB)”?
![]()
- 上图 a、b、c 分别是标准二值化与可微二值化输出、可微二值化对正样本的梯度,可微二值化对负样本的梯度,k 是放大倍数
- 标准二值化 (SB):通过预先设置的阈值 t 去对概率图 二值化
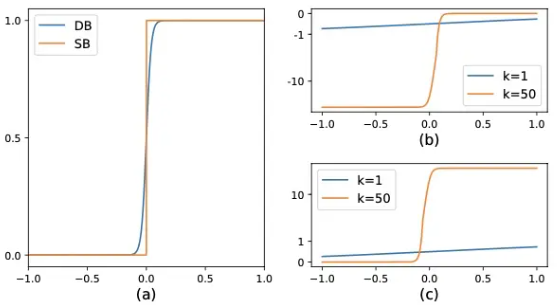
- 可微二值化 (DB):借鉴 sigmoid 输出输出,将 作为 sigmoid 输入,并 K 扩大输出,使得 趋向 0 或 1,即通过学习每个位置的阈值 对概率图 二值化
- 正负样本梯度比较:DB 改进性能的原因可以通过梯度的反向传播来解释,可知正负样本的梯度被 k 放大
DB 的自适应阈值?
![]()
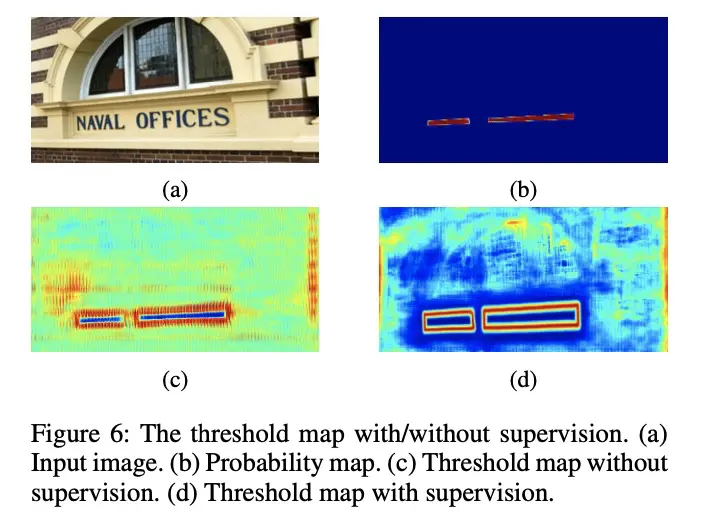
- a、b、c、d 分别是原图、probability map、无监督的 threshold map、有监督的 threshold map
- c 图表明即使没有对 threshold map 监督,其结果也会表现出突出显示文本边界区域。这表明如果加入类似边界的监督,以提供更好的指导,d 图的结果证明了这一点
DB 的标签生成过程?
![]()
- probability map:使用 Vatti clipping algorithm 将 G 缩减到 Gs(蓝线内部),A 是面积,r 是 shrink ratio,设置为 0.4,L 是周长
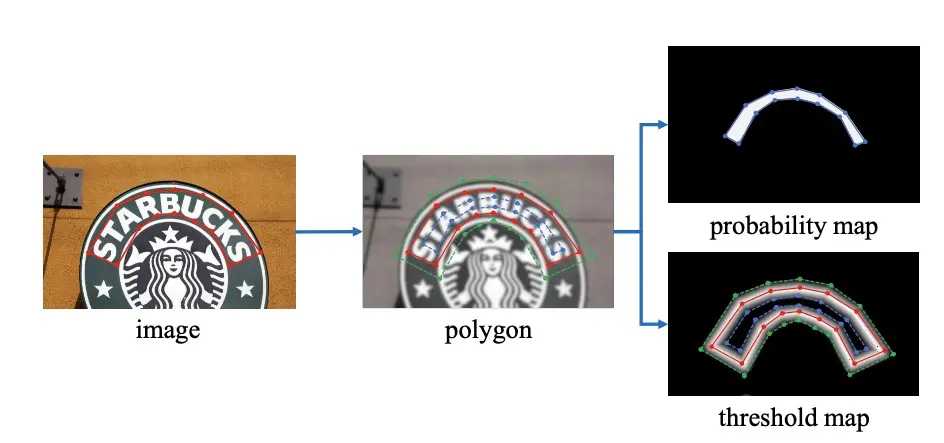
- threshold map:使用生成 probability map 一样的方法,向外进行扩张,得到绿线和蓝线中间的区域,根据到红线的距离制作标签
- binary map:蓝色标注线以内
蓝线以内 蓝蓝绿之间 其他 probability map 0.3 越靠近红线 0.7,越远离红线 0.3 0.3 threshold map 1 0 0 binary map 1 0 0
DB 的损失函数?
- 是 probability map 的 loss, 是 binary map 的 loss, 是 threshold map 的 loss, 和 设置为 1 和 10, 和 使用交差熵计算损失 $$L=L_s+\alpha\times L_b+\beta\times L_t$$
- 表示使用 OHEM 进行采样,正负样本的比例为 1:3, 使用 L 1 loss, 表示绿线内的区域,
DB 如何解析输出?
- 在推理阶段,可以使用 binary map 或者 probability map
- 使用 binary map:需要 probability map+threshold map 两个分支计算得到,其结果就是文本实例
- 使用 probability map:不需要 threshold map、binary map 分支,直接按照 Vatti clipping algorithm 公式还原回去即可,即 1) 使用 0.3 的阈值进行二值化;2) 将 pixel 连接成不同的文本实例;3) 将文本实例进行扩张,得到最终的文本框
- 使用第二种方法,网络计算更少,论文使用第二种方法
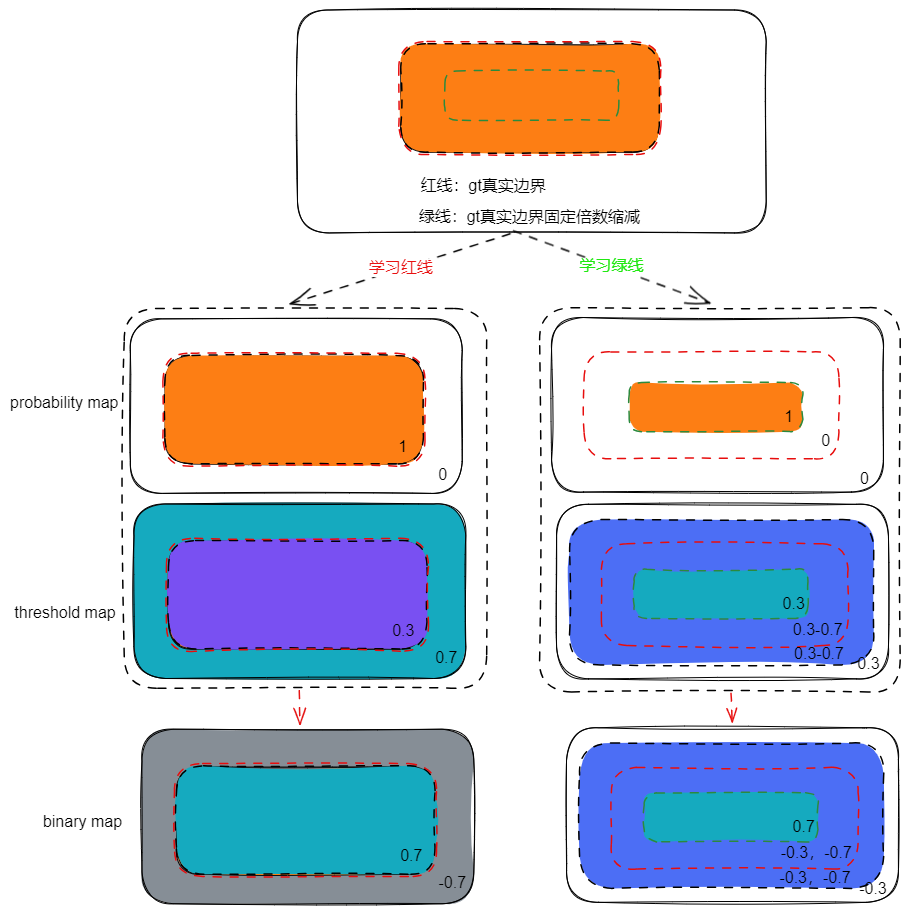
DB 为什么不直接学习文本外轮廓,而是学习轮廓缩小的轮廓?
![Drawing-2023-04-09-15.43.02.excalidraw]()
- 上图是两种学习路线下的 probability map、threshold map 及他们学习的 binary map,其中红线是直接学习文本边缘(下文称直觉模式),绿线学习文本边缘小一圈的轮廓(下文称 DB 模式)
- 观察 probability map,“直觉模式” 比 DB 模式范围更大,这对极度弯曲的小文本是不友好的,可以想象文本在 C2 特征已经辨别不出弯曲,更小的学习区域可以有更强的能力
- 观察 threshold map,因为文本行占据了图片大部分区域,所以 “直觉模式” 主要优化背景到 0.7, threshold map 计算 L1 损失,相比较 DB 模式大部分优化背景到 0.3,“直觉模式” 更难优化
- 观察 binary map:除了和优化 threshold map 同样的问题外,由于 “直觉模式” 对文本行内、外的梯度大小一样,说明两个区域优化权重一样。而 DB 模式内部梯度比外部梯度更大,相当于增大正样本的梯度权重
- 总结:“直觉模式” 比 DB 模式更难优化,而且 DB 模式对弯曲小文本性能更好
参考: