我的语义分割学习路线
本文总结自己目前对语义分割的认识,和学习过程
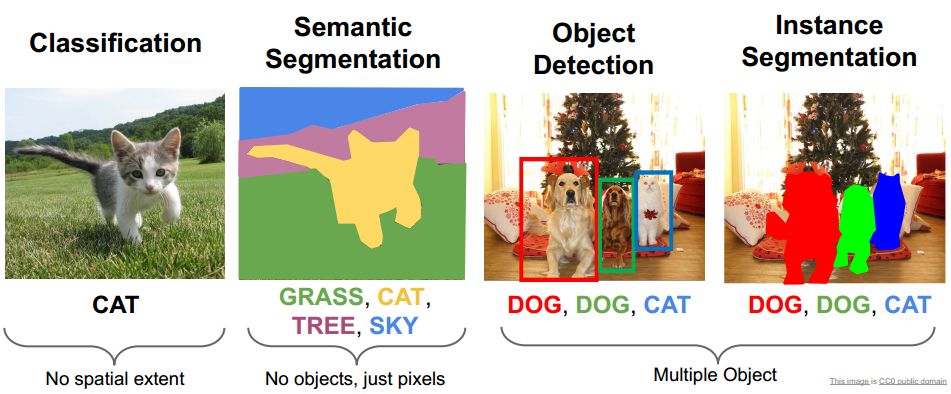
什么是语义分割?
![]()
- 语义分割是针对图片像素点的分类,1 个像素的类别可以是单标签,也可以是多标签
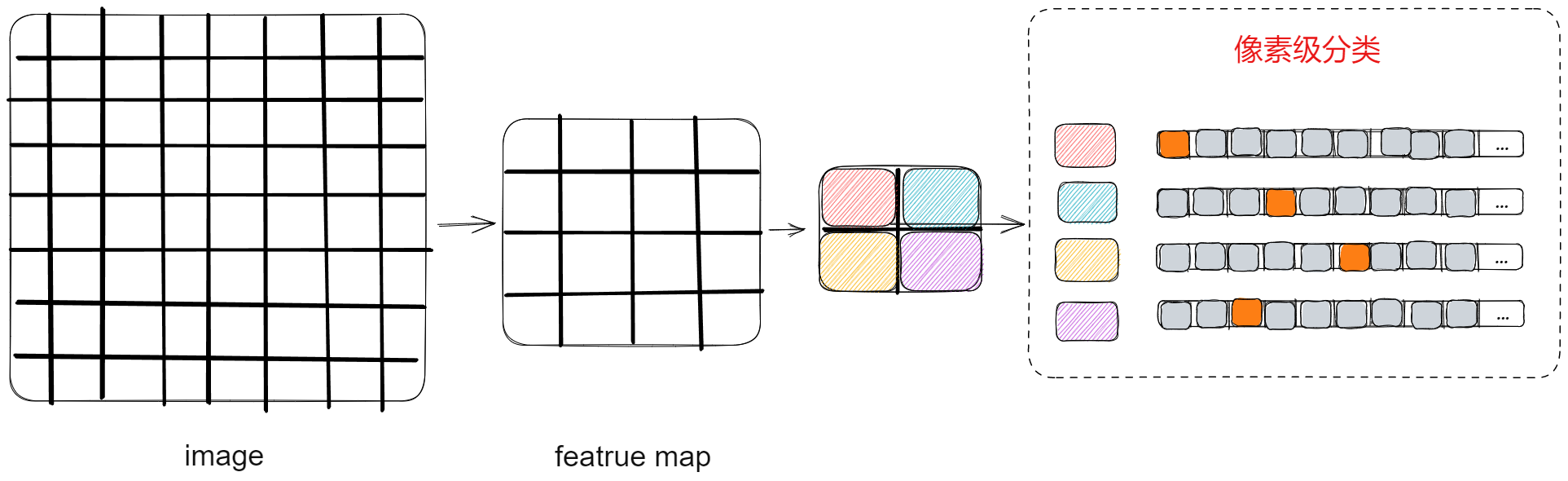
语义分割原理
![]()
- 图片经过 CNN 提取特征后,得到的是分辨率变小的 2D featrue map,通过上采样将 featrue map 的分辨率变大,然后预测每个 grid 的类别(可以是单标签预测,也可以是多标签)
语义分割难点
- 分辨率下降:CNN 提取的特征平移不变性,这对分类任务很有用,但是对分割来说,希望原图目标移动后,其特征的响应也在移动,因此分辨率下降导致最后 featrue map 包含位置信息少。通常使用 “跳跃连接” 解决,即将包含位置信息的高分辨率特征和包含语义信息的低分辨率融合解决
- 感受野小:CNN 下采样倍率一般比较小,所以随后 featrue map 上每个 grid 的感受野一般不大,这就意味着每个特征接收少部分其他像素的信息,这对大尺度的目标来说是非常不利的。通常使用 “空洞卷积” 解决,即在不加深网络的情况下提高感受野
- 目标多尺度:图片存在多尺度的目标,如果仅使用一种分辨率去做最后分类,对其他分辨率效果不佳。通常使用多尺度特征融合来解决,比如 PSP、ASPP 模块
- 依赖距离短:这和感受野的影响类似,但是即使感受野再大,也不能大过原图,所以像素之间的长程依赖还不够。通常使用 “自注意力机制” 去解决,比如构建特征的通道注意力、空间注意力去创建这种依赖
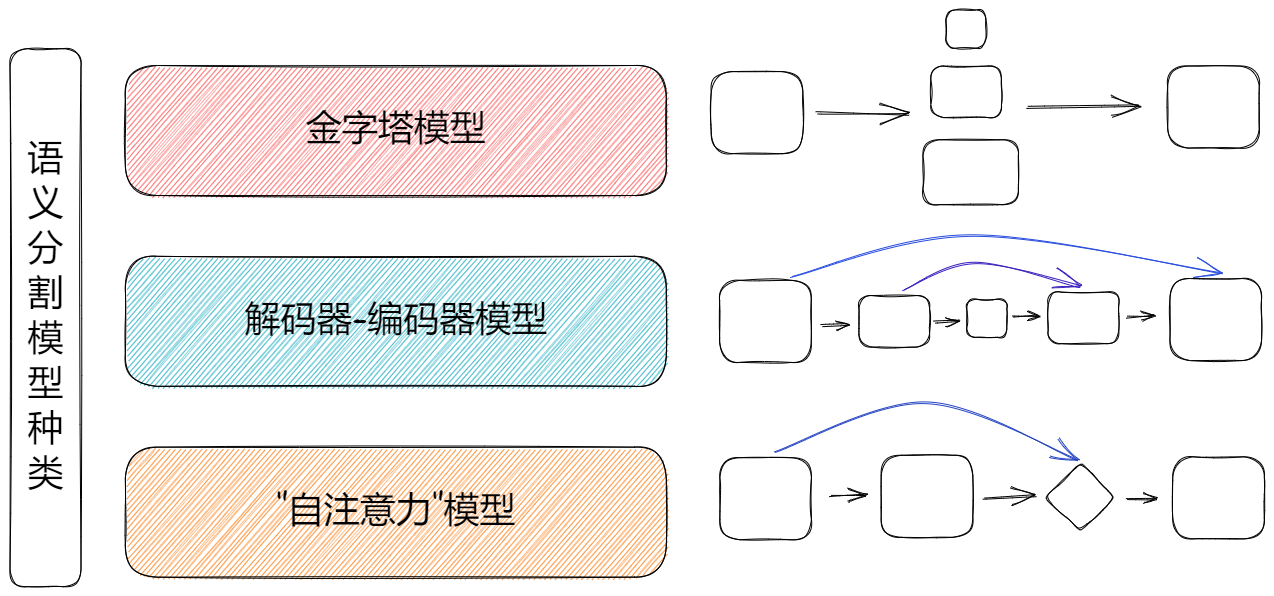
语义分割模型的种类
![]()
- 金字塔模型:通过构建并融合多尺度特征,实现对不同尺度目标的分割,代表模型有 DeepLab 系列,PSPNet,DANet,APCNet
- 编码器 - 解码器:使用 CNN 下采样提取特征,然后使用线性插值、反卷积、反池化操作实现上采样,并通过跳跃连接将高分辨率的位置信息联通到低分辨率的语义特征
- “自注意力” 系列:通过引入 “自注意力” 机制,构建像素之间的远程连接,解决感受野解决不了的尺度问题
语义分割的上采样类型
语义分割在还原分辨率时,通常使用上采样,不同的上采样在速度、精度有不同区别
| 方法 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 线性插值 | 通过相邻的元素决定待插值点的值,如最近邻插值、线性插值、双 3 次线性插值 | 快速、无需学习 | - |
| 反池化 | 记录池化时的激活位置,上采样时直接将值赋值给这个位置 | 无需学习 | 需要额外存储记录激活;上采样效果不好 |
| 反卷积 | 通过反卷积上采样 | 可以被学习优化 | 增加模型计算,有网格效应 |
评价指标

- 语义分割常使用 mIOU 作为统计指标,注意:统计某类 TP、FP、FN 指标时,是针对所有图片的所有像素预测结果、而不是具体一张图片
- 首先统计某个类别在所有图片上的累计 TP、FP、FN 像素数量、然后计算这个类别的 IOU ,再算所有类别的平均
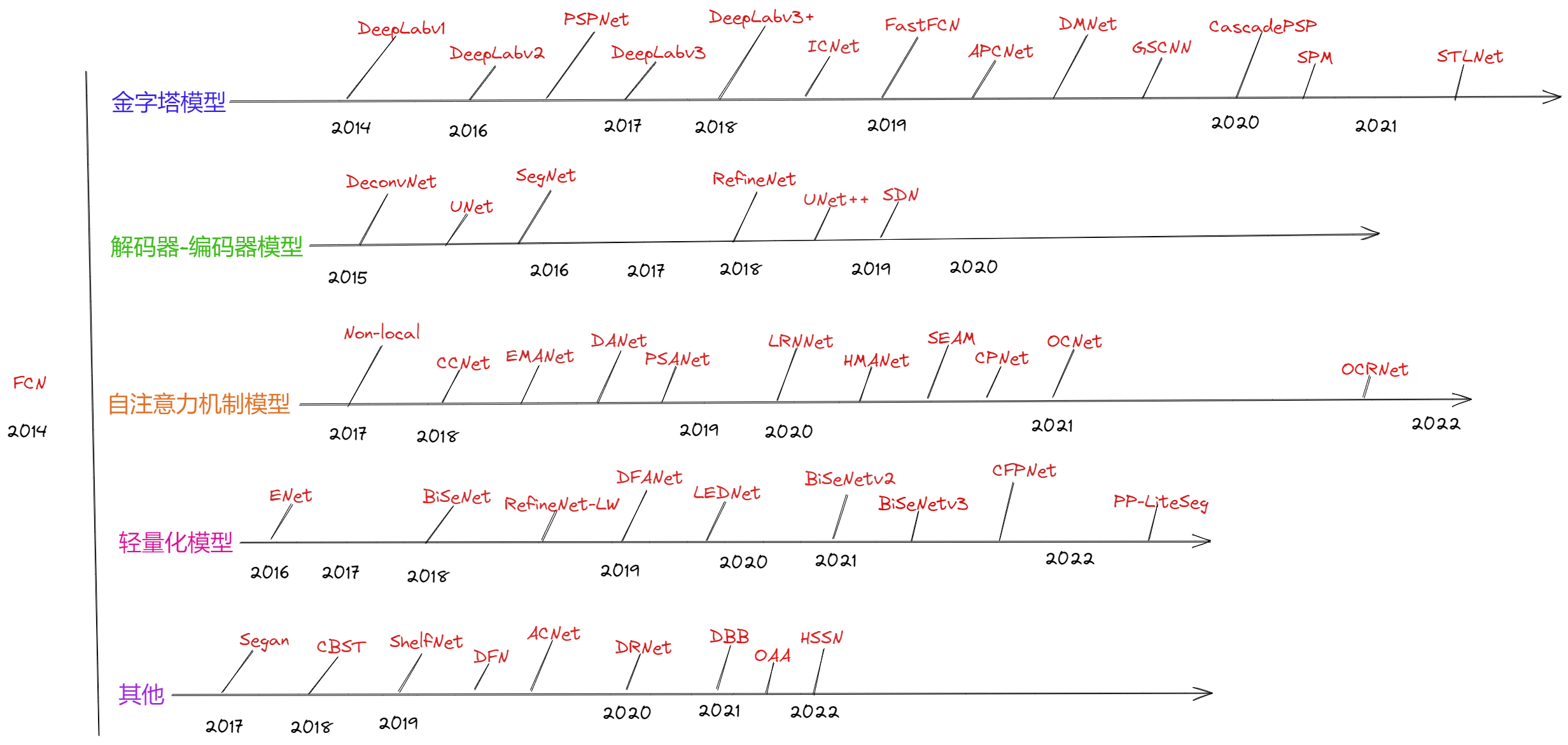
学习路线