ATSS:Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
ATSS 分析了代表 Anchor-base 的 RetinaNet 和代表 Anchor-free 的 FCOS 的正负样本选择过程,提出在在不同特征层上统计预测框 IOU,并使用其均值 + 方差作为正样本的阈值线,将这个正样本选择方法应用于 RetinaNet 和 FCOS,均带来性能的提升
什么是 ATSS ?
![]()
- ATSS 分析了代表 Anchor-base 的 RetinaNet 和代表 Anchor-free 的 FCOS 的正负样本选择过程,提出两种模型性能的区别在于正负样本的选择,换句话说,只要正负样本选择正确,两类模型性能接近
- 进一步 ATSS 提出在在不同特征层上统计预测框 IOU,并使用其均值 + 方差作为正样本的阈值线,将这个正样本选择方法应用于 RetinaNet 和 FCOS,均带来性能的提升
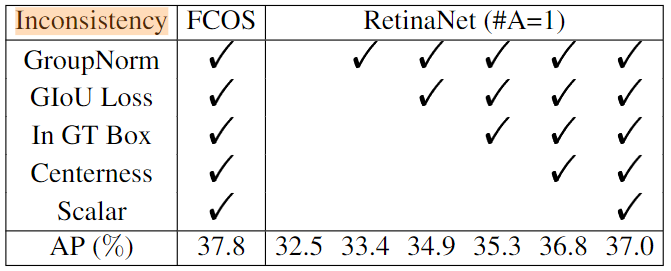
Anchor-base 与 Anchor-free 的本质区别是正负样本的选择?
![]()
- 论文比较了 FCOS 和 anchor=1 时的 RetinaNet,训练时使用相同的正样本选择思路,并使用 GroupNorm 等操作消除不确定性后,发现最终两者效果相近
- 由此说明 Anchor-base 的检测器和 Anchor-free 检测器之间的本质区别实际上是如何定义正训练样本和负训练样本
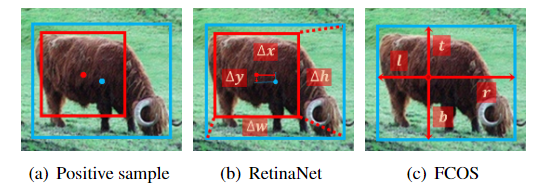
ATSS 如何选择正样本?
![]()
- (1) Ai 是不同金字塔层的 anchor ,所有层加起来等于 A,样本划分的目的是确定 A 是 P 还是 N,确认是 P 时,与真实框 G 中哪些框匹配
- (2) 首先统计真实框 G 与在所有金字塔层上比较接近(通过 L 2 距离) anchor 的 IOU 值,这些值组合一个集合 Dg
- (3) 计算 Dg 的均值 m 和方差 v,求得正样本距离是 t=m+v
- (4) 所有与 gt 框 IOU 值大于 t 的 anchor 均是正样本,其余的是负样本

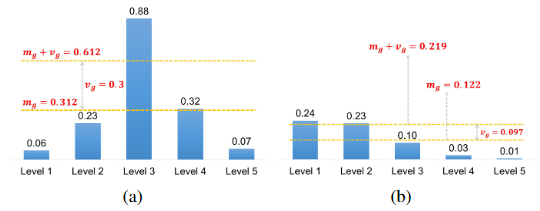
为什么 ATSS 的正样本选择比 IOU 阈值选择更有效?
![]()
- 使用均值和标准差之和作为 IoU 阈值。对象的 IoU 均值 mg 是预设锚点对该对象的适用性的度量。如图 (a) 所示的高 mg 表明它具有高质量的候选者,IoU 阈值应该很高。如图 (b) 所示的低 mg 表明它的大多数候选者都是低质量的,IoU 阈值应该很低。此外,对象的 IoU 标准偏差 vg 是哪些层适合检测该对象的度量
- 使用均值 mg 和标准差 vg 之和作为 IoU 阈值 Tg 可以根据对象的统计特征自适应地为每个对象选择合适的正样本
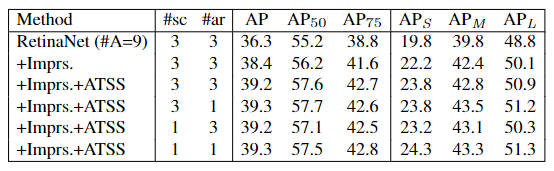
为什么增加 Anchor-base 的 anchor 数量,带来的提升有限?
![]()
- RetinaNet 在消除与 FCOS 的差异后, # A=1 与# A=9 的 AP 值分别是:37%、38.4%,这表明增加 Anchor 的数量有助于提升模型效果
- 但是在使用 ATSS 后,增加 Anchor 的数量,带来的效果提升,几乎可以不计
- 总结:只要正确选择正样本,增加 anchor 的数量不能带来性能提升