极端随机树 - Extremely_Randomized_Trees
什么是极端随机树 (Extremely Randomized Trees)?
![]()
一种集成学习方法,它通过构建多个决策树并结合它们的预测结果来做出最终决策
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26>>> from sklearn.model_selection import cross_val_score
>>> from sklearn.datasets import make_blobs
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.ensemble import ExtraTreesClassifier
>>> from sklearn.tree import DecisionTreeClassifier
>>> X, y = make_blobs(n_samples=10000, n_features=10, centers=100,
... random_state=0)
>>> clf = DecisionTreeClassifier(max_depth=None, min_samples_split=2,
... random_state=0)
>>> scores = cross_val_score(clf, X, y, cv=5)
>>> scores.mean()
0.98...
>>> clf = RandomForestClassifier(n_estimators=10, max_depth=None,
... min_samples_split=2, random_state=0)
>>> scores = cross_val_score(clf, X, y, cv=5)
>>> scores.mean()
0.999...
>>> clf = ExtraTreesClassifier(n_estimators=10, max_depth=None,
... min_samples_split=2, random_state=0)
>>> scores = cross_val_score(clf, X, y, cv=5)
>>> scores.mean() > 0.999
True![]()

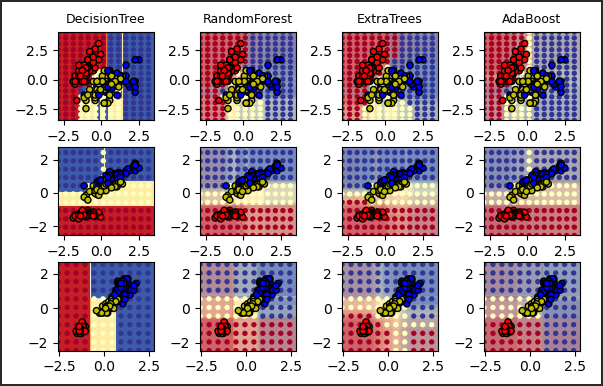
在 scikit-learn 中,随机极端树如何应用于分类任务?
- 该类实现了一个元估计器,它在数据集的各种子样本上拟合了一些随机决策树(又称树外树),并使用平均法来提高预测精度和控制过度拟合
1
2
3
4
5
6
7
8>>> from sklearn.ensemble import ExtraTreesClassifier
>>> from sklearn.datasets import make_classification
>>> X, y = make_classification(n_features=4, random_state=0)
>>> clf = ExtraTreesClassifier(n_estimators=100, random_state=0)
>>> clf.fit(X, y)
ExtraTreesClassifier(random_state=0)
>>> clf.predict([[0, 0, 0, 0]])
array([1])
在 scikit-learn 中,随机极端树如何应用于回归任务?
- 该类实现了一个元估计器,它在数据集的各种子样本上拟合了一些随机决策树(又称树外树),并使用平均法来提高预测精度和控制过度拟合
1
2
3
4
5
6
7
8
9
10>>> from sklearn.datasets import load_diabetes
>>> from sklearn.model_selection import train_test_split
>>> from sklearn.ensemble import ExtraTreesRegressor
>>> X, y = load_diabetes(return_X_y=True)
>>> X_train, X_test, y_train, y_test = train_test_split(
... X, y, random_state=0)
>>> reg = ExtraTreesRegressor(n_estimators=100, random_state=0).fit(
... X_train, y_train)
>>> reg.score(X_test, y_test)
0.2708...