cGAN
将类别信息 + 随机数作为生成器输入,使得生成器生成内容有指向性
什么是 cGAN ?
![]()
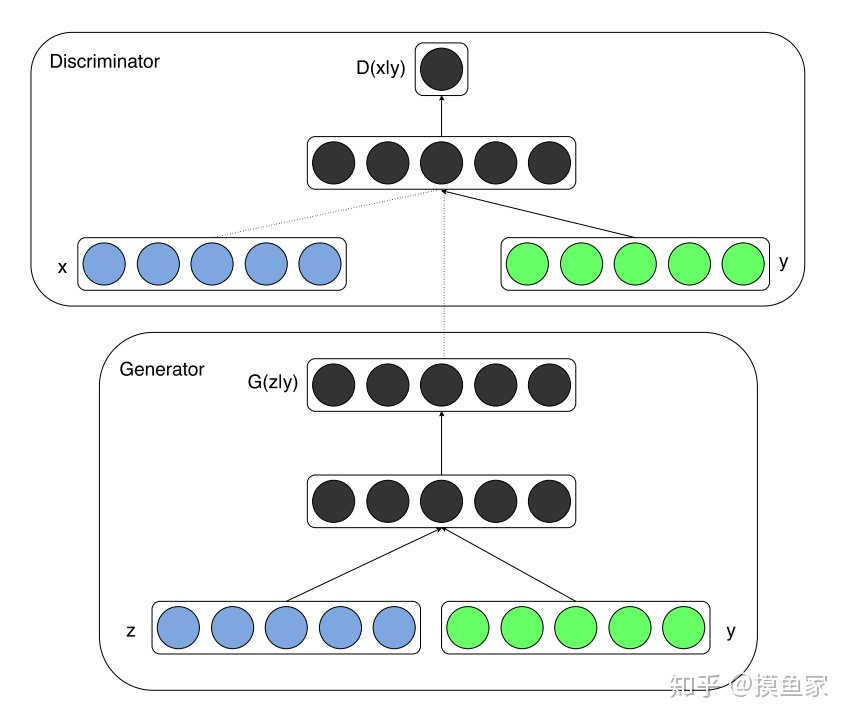
- 在 conditional GAN 中,生成器和判别器的输入都多了一个 y,这个 y 就是那个条件。以手写字符数据集 MNIST 为例,这时候 x 代表图片向量,y 代表图片类别对应的 label (one-hot 表示的 0~9)
- 对于判别器 D,训练的时候,输入的时候把训练样本 x(或 G 产生的样本)和 y 同时输入,在第一个 hidden layer 后合并,最后的输出是在 y 的条件下训练样本 x(或 G 产生的样本) 是真样本的概率,然后反向优化
- 原理:假设向判别其输入真实图片 10 和标签 10,判别器判定为真实,向判别器输入生成样本和标签 10,判别器判定为假,训练稳定后生成样本靠近图片 10 才能欺骗判别器。如此实现通过加入标签信息,指向生成固定样本
cGAN 的损失函数?
- 损失函数变为某个条件 y 下的随机
cGAN 应用到多模态上?
![]()
- 比如图示的图片标签生成可以用以下过程训练:1)cGAN 的生成接收 100 维的高斯噪声把它映射到 500 维的 ReLu 层,同时把 4096 维的图像特征向量映射到一个 2000 维的 ReLu 隐层,再上面的两种表示连接在一起映射到一个 200 维的线性层,最终由这个层输出 200 维的仿标签文本向量;2)由 500 维和 1200 维的 ReLu 隐层组成,用于处理文本和图像。最大输出层是有 1000 个单元和 3spieces 的连接层用于给最终的 sigmoid 层处理输入数据

参考: