VQGAN
(图 A->z)->z’ (离散化)-> 图 A’,随机图片
什么是 VQGAN ?
![]()
- GAN 一般来说是从特定分布中采样随机数,然后生成样本,利用生成器 - 判别器的博弈训练模型,VQGAN 的 GAN 却借鉴 VAE 的过程,将生成器分为 Encoder-Decoder 两个阶段,并利用 codebook 机制学习离散的中间隐变量。模型训练好后,利用离散的中间隐变量 + 自回归的 transformer 预测高质量的图片
- VQGAN 可以用于图片转换,包括超高像素风景图片、图像补全、深度图引导、语义引导、人体姿态引导和类别引导生成
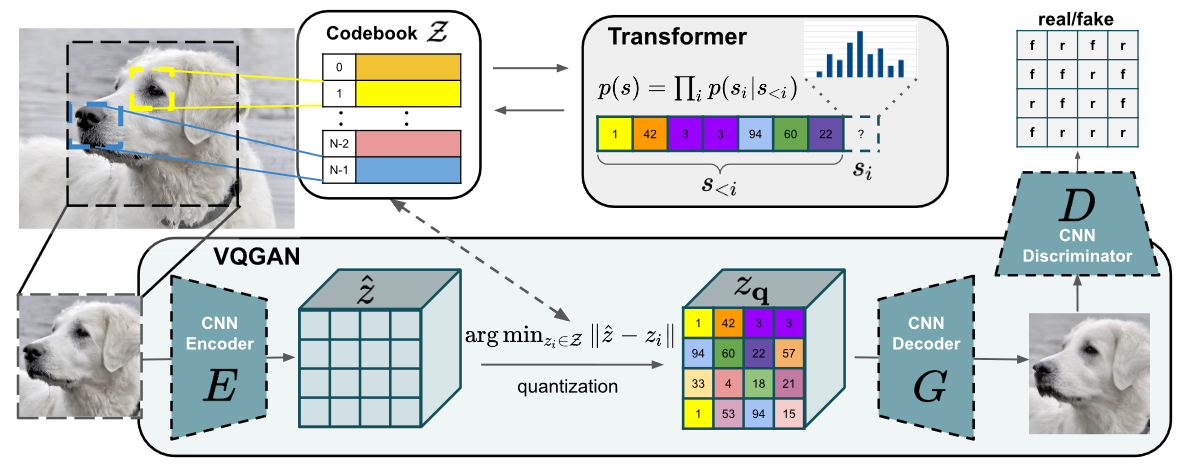
VQGAN 的训练过程?
![]()
- 训练生成器、判别器:通过自监督学习训练 CNN Encoder,CNN Decoder,和 Codebook,输入图片 ,CNN Encoder 输出 ,如果是普通的 AutoEncoder,则会将 直接送入解码器中进行图像重建。而在 VQVAE/VQGAN 中,会将 进一步离散化编码成 。这一步是自监督过程,损失包括生成器损失和判别器损
- 训练 Transformer:使用了自回归生成模型生成图像,图片 ->CNN Encoder ->codebook ->Transformers ( -> ),其中 transformer 之前的模块已经训练好,训练 Transformers 时,通过随机加入特征,驱动模型训练,也即是利用已知区域预测遮住的区域,其损失是交叉
VQGAN 的生成过程?
- 在 VQGAN 无条件生成图片的过程中,没有任何先验条件,CNN Encoder 直接被弃用。我们需要得到一组排列好的 code,送进 CNN Decoder 中来实现图像生成
- 那么这组 code 怎么来的?这就是 Transformer 发挥作用的地方了,这里使用了 GPT-2。其原本是被用来做自然语言处理的,可以理解为语言生成模型中,由前文推测出下一次词,再一步步推测后面的词或句子。那么迁移到 VQGAN 中,即可理解为先预测一个 code,再一步步地通过已经预测好的 code 去推断下一个 code。(这里地 code 都是从训练好的 codebook 中寻找)
GAN、VQVAE、VQGAN 的区别?
- GAN 一般来说是从特定分布中采样随机数,然后生成样本,利用生成器 - 判别器的博弈训练模型
- VQGAN 和 VQ-VAE 的流程完全一致 —— 先学习 codebook、再学习 prior. 学习 codebook 的部分与 VQ-VAE 大同小异,不同之处在于:加了一个 Patch Discriminator 做对抗训练,以及把重构损失的 L2 loss 换成了 perceptual loss
- VQ-VAE 使用 PixelCNN 学习 latent prior,能力比较弱,而 VQGAN 采用了 Transformer (GPT-2 架构),依旧用自回归的方式训练和推断
参考: