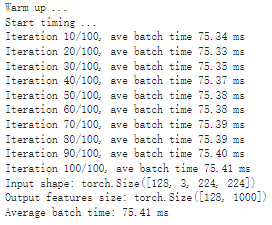
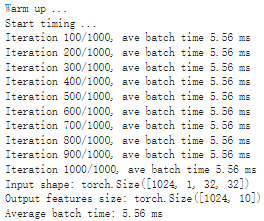
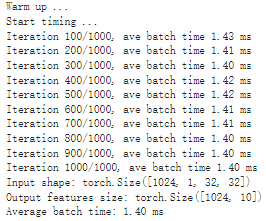
# Model benchmark without Torch-TensorRT model = resnet50_model.eval().to("cuda") benchmark(model, input_shape=(128, 3, 224, 224), nruns=100)
2. 编译模型 - fp32
1 2 3 4 5 6 7 8 9 10 11
import torch_tensorrt
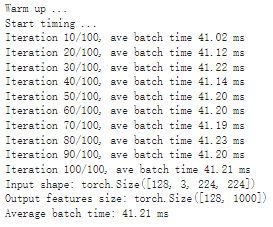
# The compiled module will have precision as specified by "op_precision". # Here, it will have FP32 precision. trt_model_fp32 = torch_tensorrt.compile(model, inputs = [torch_tensorrt.Input((128, 3, 224, 224), dtype=torch.float32)], enabled_precisions = torch.float32, # Run with FP32 workspace_size = 1 << 22 )
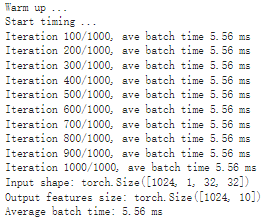
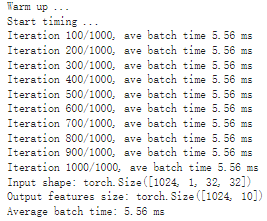
# Obtain the average time taken by a batch of input benchmark(trt_model_fp32, input_shape=(128, 3, 224, 224), nruns=100)
3. 编译模型 - fp16
1 2 3 4 5 6 7 8 9 10 11
import torch_tensorrt
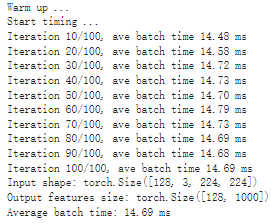
# The compiled module will have precision as specified by "op_precision". # Here, it will have FP32 precision. trt_model_fp32 = torch_tensorrt.compile(model, inputs = [torch_tensorrt.Input((128, 3, 224, 224), dtype=torch.float32)], enabled_precisions = , dtype=torch.half, # Run with FP32 workspace_size = 1 << 22 )
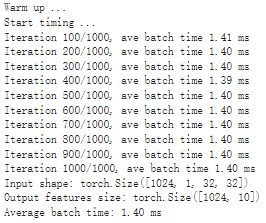
# Obtain the average time taken by a batch of input benchmark(trt_model_fp32, input_shape=(128, 3, 224, 224), dtype='fp16', nruns=100)
使用 Torch-TensorRT 编译 TorchScript 模型
1. 加载并测试模型
1 2 3
model = LeNet() model.to("cuda").eval() benchmark(model)
# Exporting to TorchScript with torch.no_grad(): data = iter(val_dataloader) images, _ = data.next() jit_model = torch.jit.trace(model, images.to("cuda")) torch.jit.save(jit_model, "mobilenetv2_base.jit.pt")
#Loading the Torchscript model and compiling it into a TensorRT model baseline_model = torch.jit.load("mobilenetv2_base.jit.pt").eval() compile_spec = {"inputs": [torch_tensorrt.Input([64, 3, 224, 224])] , "enabled_precisions": torch.float } trt_base = torch_tensorrt.compile(baseline_model, **compile_spec)
# Evaluate and benchmark the performance of the baseline TRT model (TRT FP32 Model) test_loss, test_acc = evaluate(trt_base, val_dataloader, criterion, 0) print("Mobilenetv2 TRT Baseline accuracy: {:.2f}%".format(100 * test_acc))
# 定义并加载模型权重 # All the regular conv, FC layers will be converted to their quantized counterparts due to quant_modules.initialize() feature_extract = False q_model = models.mobilenet_v2(pretrained=True) set_parameter_requires_grad(q_model, feature_extract) q_model.classifier[1] = nn.Linear(1280, 10) q_model = q_model.cuda()
# mobilenetv2_base_ckpt is the checkpoint generated from Step 2 : Training a baseline Mobilenetv2 model. ckpt = torch.load("./mobilenetv2_base_ckpt") modified_state_dict={} for key, val in ckpt["model_state_dict"].items(): # Remove 'module.' from the key names if key.startswith('module'): modified_state_dict[key[7:]] = val else: modified_state_dict[key] = val
# Load the pre-trained checkpoint q_model.load_state_dict(modified_state_dict) optimizer.load_state_dict(ckpt["opt_state_dict"])
# 定义校准规则并校准,这里使用max校准 defcompute_amax(model, **kwargs): # Load calib result for name, module in model.named_modules(): ifisinstance(module, quant_nn.TensorQuantizer): if module._calibrator isnotNone: ifisinstance(module._calibrator, calib.MaxCalibrator): module.load_calib_amax() else: module.load_calib_amax(**kwargs) model.cuda()
defcollect_stats(model, data_loader, num_batches): """Feed data to the network and collect statistics""" # Enable calibrators for name, module in model.named_modules(): ifisinstance(module, quant_nn.TensorQuantizer): if module._calibrator isnotNone: module.disable_quant() module.enable_calib() else: module.disable()
# Feed data to the network for collecting stats for i, (image, _) in tqdm(enumerate(data_loader), total=num_batches): model(image.cuda()) if i >= num_batches: break
# Disable calibrators for name, module in model.named_modules(): ifisinstance(module, quant_nn.TensorQuantizer): if module._calibrator isnotNone: module.enable_quant() module.disable_calib() else: module.enable()
#Calibrate the model using percentile calibration technique. with torch.no_grad(): collect_stats(q_model, train_dataloader, num_batches=32) compute_amax(q_model, method="max")