利用 nlp 抽取 pdf 文件关键信息
本文使用 nlp 快速检索出 pdf 文件中的关键信息,比如现有一堆合同文件,当你想搜索合同的甲乙方、金额时,不需要一个个文件打开看,只需通过该方法
本方法是利用 paddle 的两个工具,一个是 ocr,用于从 pdf 抽取文本,另一个是 nlp 模型,用于从文本中抽取关键信息,开始介绍前先安装环境
1 | conda install paddlepaddle-gpu cudatoolkit |
提取图片上的文字
本方法处理的文件是 pdf,这里利用 PaddleOCR 抽取其中的文本数据,该工具输入是图片,所以需要其他工具将 pdf 转为图片
1 | from paddleocr import PaddleOCR, draw_ocr # type: ignore |
[2024/04/10 16:06:16] ppocr DEBUG: dt_boxes num : 24, elapsed : 1.3868777751922607
[2024/04/10 16:06:16] ppocr DEBUG: rec_res num : 24, elapsed : 0.5372314453125

甲方:佛山市禅城区住房城乡建设和水利局
乙方:交通银行股份有限公司佛山分行
丙方:佛山市禅城区盈恒置业有限公司
为加强商品房预售管理,规范商品房预售款使用行为,根据《广
东省商品房预售管理条例》(以下简称《条例》)和《佛山市商品房预
售款监督管理实施办法》(以下简称《办法》),经甲方、乙方和丙方三
方协商,就坐落于_佛山市禅城区佛罗路南侧、化纤路北侧,项目名
称为保利芳华苑 12 座,监控账号 446899991010003029262
的商品房屋预售款收存和划拨使用订立如下协议,共同遵守。
一、 权利
1、甲方负责贯彻实施《条例》和《办法》有关规定,行使商品房
预售款收存和使用的日常监督管理的权利。
2、乙方在为丙方办理预售款拨付时,应要求丙方出具经甲方审核
同意的《佛山市商品房预售款使用申请表》。
公有限
3、预售项目完成初始登记并达到购房人可单方办理转移登记条件
V
的,丙方可持有关证明文件向甲方申请办理专用账户解除监管手续。
经甲方核准同意的,在《佛山市商品房预售款监管专用账户取消监管
申请表》上加具同意的意见后,视同本协议取消。丙方凭《佛山市商
cost time:2.178391218185425s
关键信息抽取
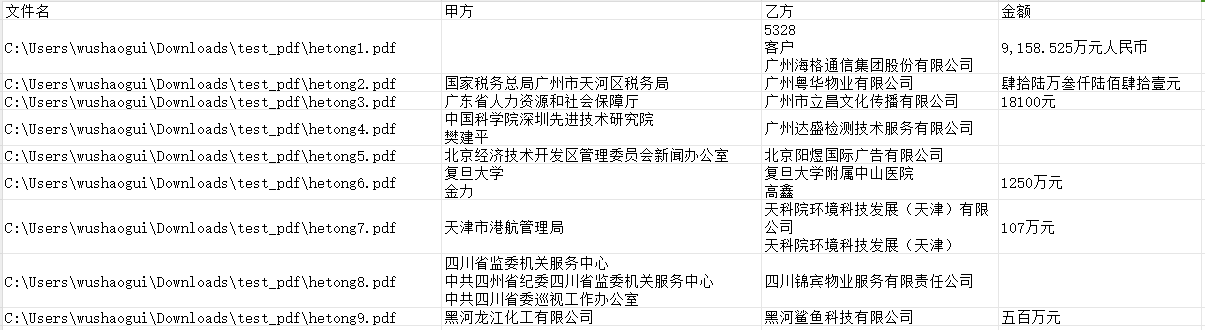
使用 paddlenlp 从提取的文本中抽取关键信息,比如下面抽取 [“甲方”,“乙方”,“总价”,“大写”,“小写”,“项目”] 等信息
1 | from paddlenlp import Taskflow # type: ignore |
[{'甲方': [{'text': '佛山市禅城区住房城乡建设和水利局', 'start': 3, 'end': 19, 'probability': 0.8409922679564374}], '乙方': [{'text': '交通银行股份有限公司佛山分行', 'start': 23, 'end': 37, 'probability': 0.8475471161905048}], '项目': [{'text': '保利芳华苑12座', 'start': 183, 'end': 191, 'probability': 0.5095629052180897}]}]
cost time:0.20002102851867676s
使用 nuitka 将以上过程打包为 exe,可以自定义处理的文档及关键信息
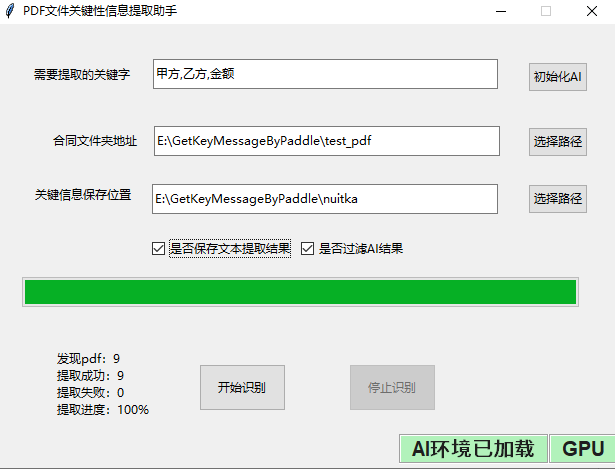
运行时,后台日志如下:
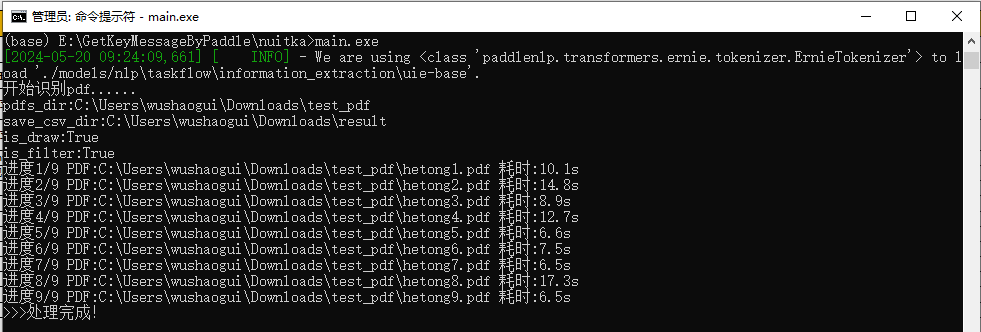
结果展示