深度学习的激活函数
在神经网络中引入激活函数,使得神经网络具有非线性的表达能力,通常使用的激活函数有 relu、sigmoid、softmax,也存在很多变种,把握他们区别即可,同时还要掌握饱和、不饱和激活函数的定义、作用
激活函数图示、计算、求导、范围快速查询?

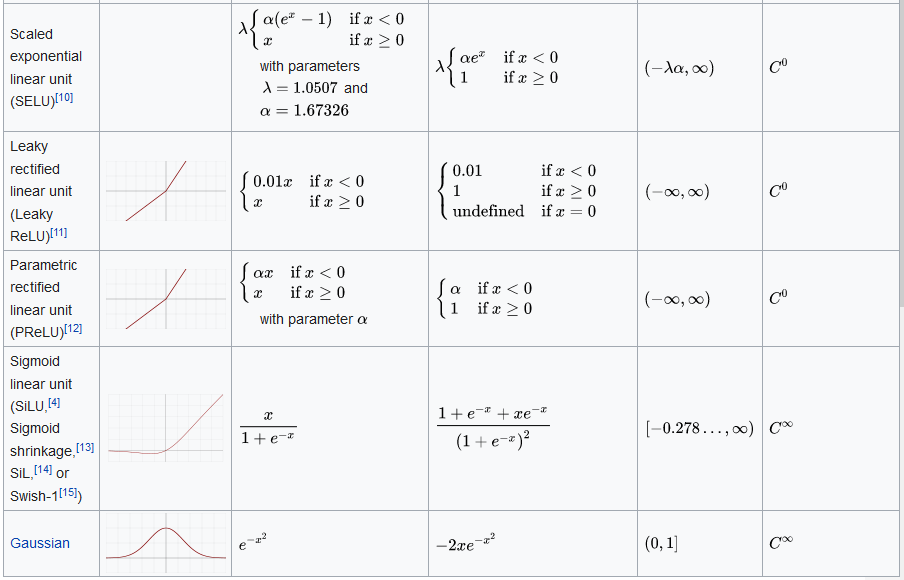

什么是 S 型函数 (sigmoid function)
- 一种函数,可将逻辑回归输出或多项回归输出(对数几率)映射到概率,以返回介于 0 到 1 之间的值
- 换句话说,S 型函数可将 转换为介于 0 到 1 之间的概率
什么是激活函数?
![]()
- 将一个实数域上的值映射到一个有限域的函数,因此也被称为塌缩函数。比如常见的 tanh 或者 logistic 函数
- 一种函数(例如 ReLU 或 S 型函数 (sigmoid function)),用于对上一层的所有输入求加权和,然后生成一个输出值(通常为非线性值),并将其传递给下一层
- 常用的功能包括 sigmoid 函数、tanh 函数、Relu 函数和这些功能的变体
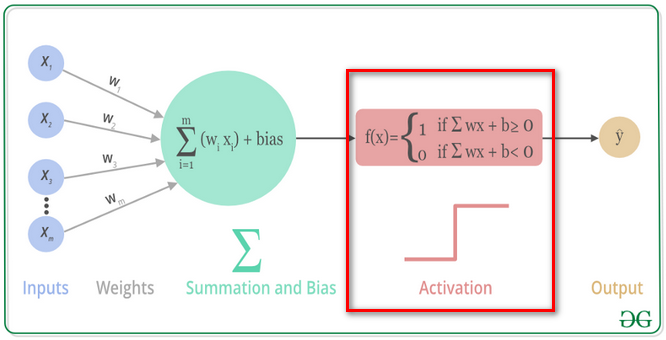
为什么使用激活函数?
- 可以把当前特征空间通过一定的线性映射转换到另一个空间,让数据能够更好的被分类
- 可以引入非线性因素,让神经网络能处理更加复杂的问题
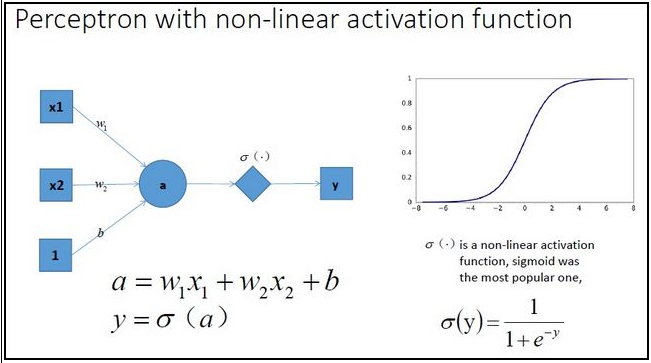
激活函数为什么需要非线性激活函数?
![]()
- 不使用激活函数:神经网络的每层都只是做线性变换,多层输入叠加后也还是线性变换
- 加入激活函数:神经网络就有可能学习到平滑的曲线来分割平面,而不是用复杂的线性组合逼近平滑曲线来分割平面,使神经网络的表示能力更强了,能够更好的拟合目标函数
神经网络中激活函数需要具有哪些必要的属性?
- 非线性:即导数不是常数,多层神经网络的基础,保证多层网络不退化成单层线性网络。这也是激活函数的意义所在
- 几乎处处可微:可微性保证了在优化中梯度的可计算性。传统的激活函数如 sigmoid 等满足处处可微。对于分段线性函数比如 ReLU,只满足几乎处处可微(即仅在有限个点处不可微)。对于 SGD 算法来说,由于几乎不可能收敛到梯度接近零的位置,有限的不可微点对于优化结果不会有很大影响
- 计算简单:正如题主所说,非线性函数有很多。极端的说,一个多层神经网络也可以作为一个非线性函数,但激活函数在神经网络前向的计算次数与神经元的个数成正比,因此简单的非线性函数自然更适合用作激活函数。这也是 ReLU 之流比其它使用 Exp 等操作的激活函数更受欢迎的其中一个原因
- 非饱和性:饱和指的是在某些区间梯度接近于零(即梯度消失),使得参数无法继续更新的问题。最经典的例子是 Sigmoid,它的导数在 x 为比较大的正值和比较小的负值时都会接近于 0。更极端的例子是阶跃函数,由于它在几乎所有位置的梯度都为 0,因此处处饱和,无法作为激活函数。ReLU 在 x>0 时导数恒为 1,因此对于再大的正值也不会饱和。但同时对于 x<0,其梯度恒为 0,这时候它也会出现饱和的现象(在这种情况下通常称为 dying ReLU)。Leaky ReLU 和 PReLU 的提出正是为了解决这一问题
- 单调性:即导数符号不变。这个性质大部分激活函数都有,除了诸如 sin、cos 等。个人理解,单调性使得在激活函数处的梯度方向不会经常改变,从而让训练更容易收敛
- 输出范围有限:有限的输出范围使得网络对于一些比较大的输入也会比较稳定,这也是为什么早期的激活函数都以此类函数为主,如 Sigmoid、TanH。但这导致了前面提到的梯度消失问题,而且强行让每一层的输出限制到固定范围会限制其表达能力。因此现在这类函数仅用于某些需要特定输出范围的场合,比如概率输出(此时 loss 函数中的 log 操作能够抵消其梯度消失的影响)、LSTM 里的 gate 函数
- 接近恒等变换:即约等于 x。这样的好处是使得输出的幅值不会随着深度的增加而发生显著的增加,从而使网络更为稳定,同时梯度也能够更容易地回传。这个与非线性是有点矛盾的,因此激活函数基本只是部分满足这个条件,比如 TanH 只在原点附近有线性区(在原点为 0 且在原点的导数为 1),而 ReLU 只在 x>0 时为线性。这个性质也让初始化参数范围的推导更为简单。额外提一句,这种恒等变换的性质也被其他一些网络结构设计所借鉴,比如 CNN 中的 ResNet 和 RNN 中的 LSTM
- 参数少:大部分激活函数都是没有参数的。像 PReLU 带单个参数会略微增加网络的大小。还有一个例外是 Maxout,尽管本身没有参数,但在同样输出通道数下 k 路 Maxout 需要的输入通道数是其它函数的 k 倍,这意味着神经元数目也需要变为 k 倍;但如果不考虑维持输出通道数的情况下,该激活函数又能将参数个数减少为原来的 k 倍
- 归一化:这个是最近才出来的概念,对应的激活函数是 SELU,主要思想是使样本分布自动归一化到零均值、单位方差的分布,从而稳定训练。在这之前,这种归一化的思想也被用于网络结构的设计,比如 Batch Normalization
模型最后一层应该如何选择激活函数?
- 对于只有 0,1 取值的双值因变量,sigmoid 函数是一个较好的选择
- 对于有多个取值的离散因变量,比如 0 到 9 数字的识别,softmax 激活函数是 sigmoid 激活函数的自然衍生
- 对于有有限值域的连续因变量,logistic 或者 tanh 激活函数都可以用,但是需要将因变量的值域伸缩到 logistic 或者 tanh 对应的值域中
- 如果因变量取值为正,但是没有上限,那么指数函数是一个较好的选择。如果因变量没有有限值域,或者虽然是有限值域但是边界未知,那么最好采用线性函数作为激活函数
神经网络中激活函数该如何选择?
- Relu 激活函数:最常用的激活函数,如果不确定用哪个激活函数,就使用 ReLU 或者 Leaky ReLU
- 如果使用 ReLU,那么一定要小心设置 学习速率 (learning rate), 并且要注意不要让网络中出现很多死亡神经元。如果死亡神经元过多的问题不好解决,可以试试 Leaky-ReLU、PReLU 或者 Maxout
- 当选用高级激活函数时,建议的尝试顺序为 Relu->elu->PReLU->MPELU,因为前两者没有超参数,而后两者需要自己调节参数使其更适应构建的网络结构
- Sigmoid 和 tanh 不建议使用
- 在较深层的神经网络中,选用 relu 激活函数能使梯度更好地传播回去,但当使用 softmax 作为最后一层的激活函数时,其前一层最好不要使用 relu 进行激活,而是使用 tanh 作为替代,否则最终的 loss 很可能变成 Nan
- 通常来说,不能把各种激活函数串起来在一个网络中使用
什么时候可以用线性激活函数?
- 输出层,大多使用线性激活函数
- 在隐含层可能会使用一些线性激活函数
- 一般用到的线性激活函数很少
什么是饱和、非饱和函数?
![]()
- 饱和 指的是在某些区间梯度接近于零(即梯度消失),使得参数无法继续更新的问题,比如 Sigmoid,它的导数在 x 为比较大的正值和比较小的负值时都会接近于 0,接近饱和,而 ReLU 在 x>0 时导数恒为 1,因此对于再大的正值也不会饱和

常见的饱和神经元、非饱和神经元?
- 饱和神经元:tanh 、sigmoid
- 非饱和神经元:Relu(左饱和,右不饱和)、Leaky-ReLU 、PReLU 、Maxout 、Softplus 、elu
饱和激活函数对神经网络的影响?
- 前向方向:落在激活函数的饱和范围内的层的值将会逐渐得到许多同样的输出值。这会导致整个模型出现同样的数据流。即出现内部协变量偏移 (Internal Covariate Shift,ICS) 现象
- 反向方向:饱和范围内的导数为零,由此导致网络几乎无法再学习到任何东西,出现网络退化现象。这就是我们在批归一化问题中提到的要将值的范围设定为零均值的原因
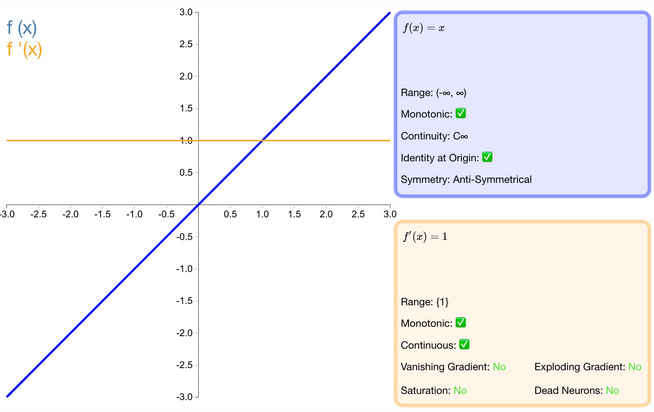
什么是 identity 激活函数?
直接将输入输出
![]()
优缺点
- 优点:适合于潜在行为是线性(与线性回归相似)的任务。
- 缺点:无法提供非线性映射,当多层网络使用 identity 激活函数时,整个网络就相当于一个单层模型
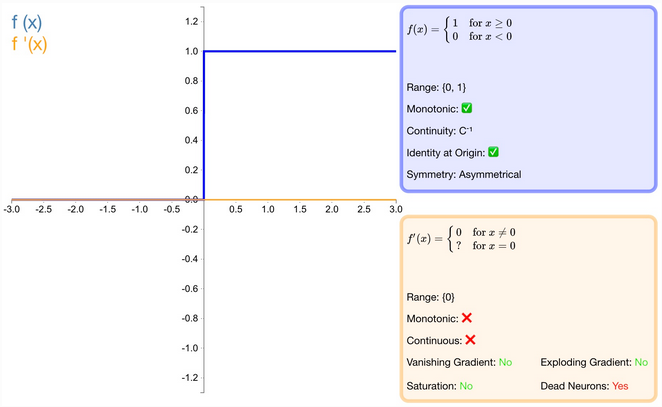
什么是 step 激活函数?
分段输出激活函数
![]()
优缺点
- 优点:激活函数 Step 更倾向于理论而不是实际,它模仿了生物神经元要么全有要么全无的属性。
- 缺点:它无法应用于神经网络因为其导数是 0(除了零点导数无定义以外),这意味着基于梯度的优化方法并不可行
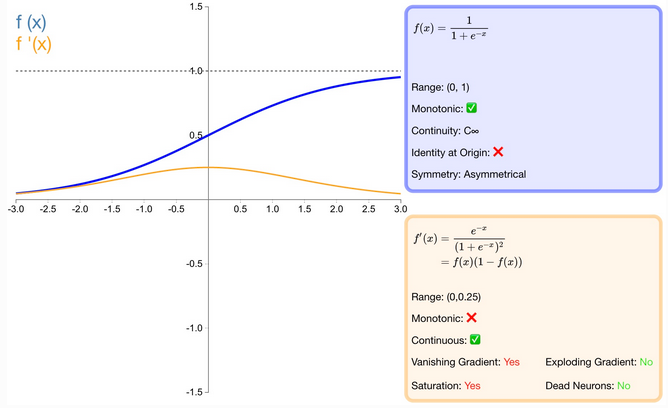
什么是 sigmoid 激活函数?
sigmoid 函数也叫 Logistic 函数,取值范围为 (0,1),它可以将一个实数映射到 (0,1) 的区间,可以用来做二分类。 在特征相差比较复杂或是相差不是特别大时效果比较好
![]()
优缺点
- 优点:(1) sigmoid 函数的输出映射在 (0,1) 之间,单调连续,输出范围有限,优化稳定,可以用作输出层;(2) 求导容易;
- 缺点:(1) 饱和性:激活前的值在 [-5,5] 之间导数非 0,并且最大是 0.25,意味着反向传播的时,梯度至少减少 75%,因此层数多容易出现梯度消失 (gradient vanishing) 现象,通过使用 Relu 或批规范化 (Batch Normalization,BN) 解决;(2) 非 “零为中心”(zero-centered) 输出: 在多层的 sigmoid 中,当梯度从上层传播下来,w 的梯度都是用 x 乘以 f 的梯度,因此如果神经元输出的梯度是正的,那么所有 w 的梯度就会是正的,反之亦然,使得优化的时候效率十分低下,模型拟合的过程就会十分缓慢;(3) 指数计算:比较消耗计算资源的
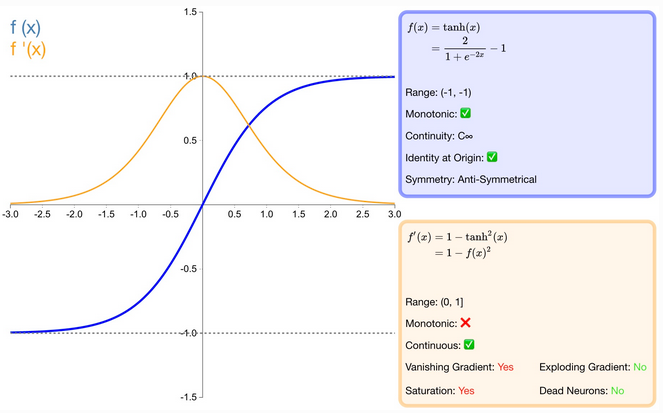
什么是 tanh 激活函数?
也称为双切正切函数,是 sigmoid 的变形,取值范围为 [-1,1] ,输出值以 0 为中心,与 sigmoid 激活函数相比具有更大的梯度值,再加上输出值以 0 为中心,模型收敛更快。不过它依然存在两端饱和,梯度消失问题还是存在,tanh 激活函数在 RNN 模型中应用较多
![]()
优缺点―
- 优点:(1) tanh 比 sigmoid 函数收敛速度更快;(2) 相比 sigmoid 函数,tanh 是以 0 为中心的;
- 缺点:(1) 与 sigmoid 函数相同,由于饱和性容易产生的梯度消失;(2) 与 sigmoid 函数相同,由于具有幂运算,计算复杂度较高,运算速度较慢
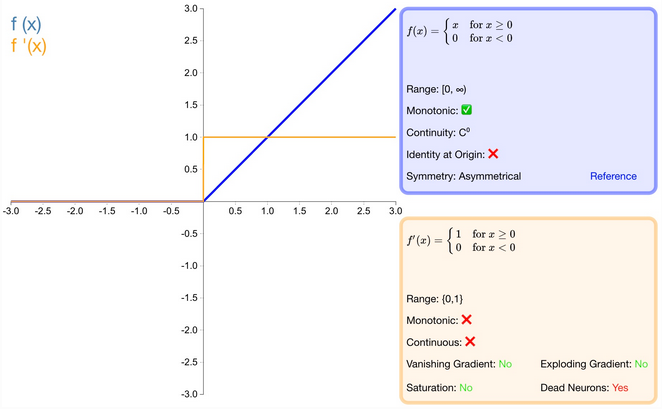
什么是 Relu 激活函数?
全称是 Rectified Linear Unit (修正线性单元),是目前深层神经网络中常用的激活函数
![]()
优点
- 1) 解决梯度消失 (gradient vanishing) 的问题 (在 x 的正区间梯度不饱和);
- 2) 快速收敛: 由于 ReLU 线性、非饱和的形式,在随机梯度下降 (stochastic gradient descent, SGD) 中能够快速收敛;
- 3) 计算速度要快很多: ReLU 函数只有线性关系,计算速度都比 sigmoid 和 tanh 快
缺点
- 1) ReLU 的输出不是 “零为中心”;
- 2) 死亡神经元: 一旦权重参数变为负值时,输入网络的正值会和权重相乘后也会变为负值(一直都是),负值通过 ReLu 后就会输出 0,那么这个含有 ReLU 的神经节点就会死亡,再也不会被激活 **;**
- 3) 不能避免梯度爆炸 (gradient exploding) 问题
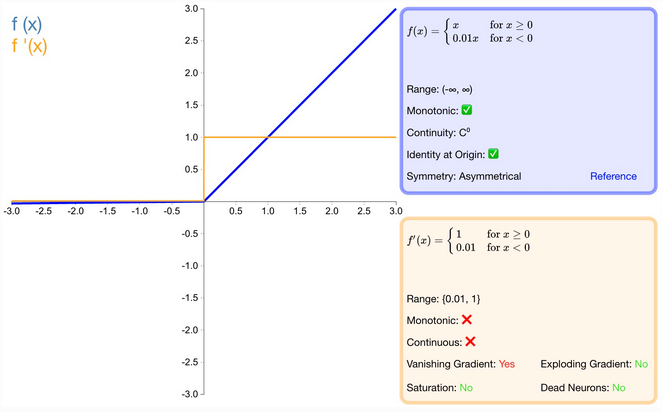
什么是 Leaky-ReLU 激活函数?
Relu 将所有的负值设置为 0,造成神经元节点死亡情况,Leaky-ReLU 则给所有负值赋予一个非零的斜率
![]()
优点―
- 继承 Relu 的所有优点,但是由于梯度始终大于 0,所以不会出现死亡神经元
缺点
- Leaky ReLU 函数中的 α,需要通过先验知识人工赋值
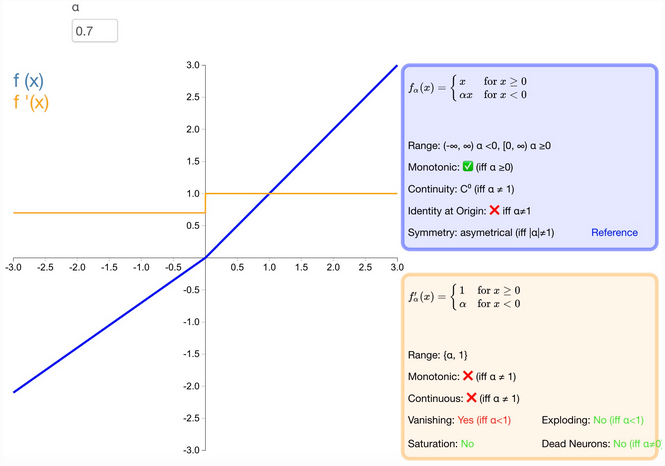
什么是 PReLU 激活函数?
参数化修正线性单元,是 Leaky-ReLU 的一个变体, 负值部分的斜率是根据数据来定的,而非预先定义的
训练时,a 服从均匀分布 $U (l, u), l 批规范化 (Batch Normalization,BN))
![]()
优点
- 继承 Leaky-ReLU 的所有优点,并且可以自适应地从数据中学习参数
缺点
- 流程复杂,增加计算量
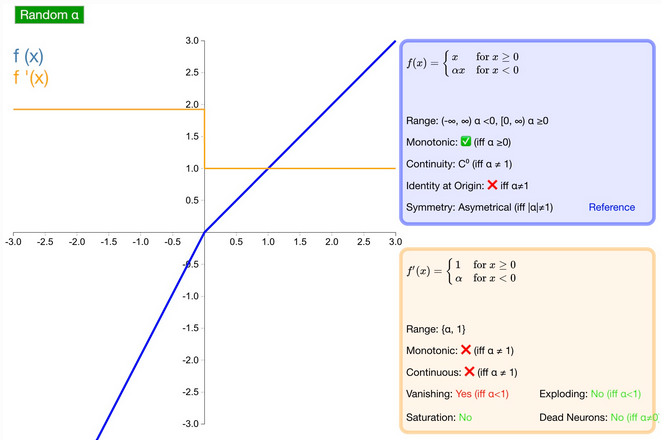
什么是 RReLU 激活函数?
R-ReLU:是 Leaky ReLU 的 random 版本,在训练过程中,α 是从一个高斯正态分布 (normal) 随机出来的,然后再测试过程中进行修正
随机修正线性单元。是 Leaky-ReLU 的随机版本,负值部分的斜率变成可变参数,在训练过程中,α 是从一个高斯正态分布 (normal) 中随机出来的,然后再测试过程中进行修正
![]()
优点
- 为负值输入添加了一个线性项,这个线性项的斜率在每一个节点上都是随机分配的
什么是 Swish 激活函数?
![]()
Swish 也被称为 self-gated(自门控)激活函数
一般来说,swish 激活函数的表现比 Relu 更好。从图中我们可以观察到 swish 激活函数在 x 轴的负区域内末端的图像形状与 relu 激活函数是不同的,这是因为 swich 激活函数即使输入的值在增加,它的输出也可以减少。大部分的激活函数都是单调的,即他们的输出值在输入增加的时候是不会减少的。但 Swish 在 0 点具有单边有界性,平滑且不单调
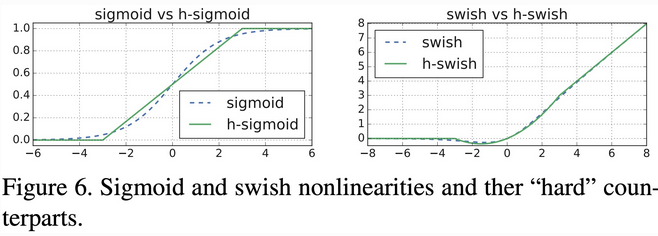
什么是 hswish 激活函数?
![]()
优点
- 与 swish 相比 hard swish 减少了计算量,具有和 swish 同样的性质。
缺点
- 与 relu6 相比 hard swish 的计算量仍然较大
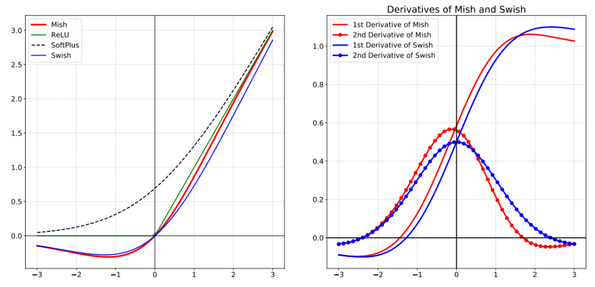
什么是 Mish 激活函数?
YOLOv4 的骨干网络中都使用了 Swish 激活函,平滑、非单调、无上界、有下界的激活函数
在负值的时候并不是完全截断,允许比较小的负梯度流入 ,与其他常用函数如 Relu 和 Swish 相比,提高了它的性能
![]()
什么是 Maxout 激活函数?
- Maxout 是对 Relu 和 Leaky-ReLU 的一般化归纳
- 它的激活函数、计算的变量、计算方式和普通的神经元完全不同,并有两组权重。先得到两个超平面,再进行最大值计算
- Maxout 神经元就拥有 ReLU 单元的所有优点(线性和不饱和),而没有它的缺点(死亡的 ReLU 单元)。然而和 ReLU 对比,它每个神经元的参数数量增加了一倍,这就导致整体参数的数量激增
- Maxout 具有 ReLU 的所有优点,线性、不饱和性, 同时没有 ReLU 的一些缺点。如:神经元的死亡
- 每个什么是神经元 (neuron) 将有两组 w,那么参数就增加了一倍。这就导致了整体参数的数量激增
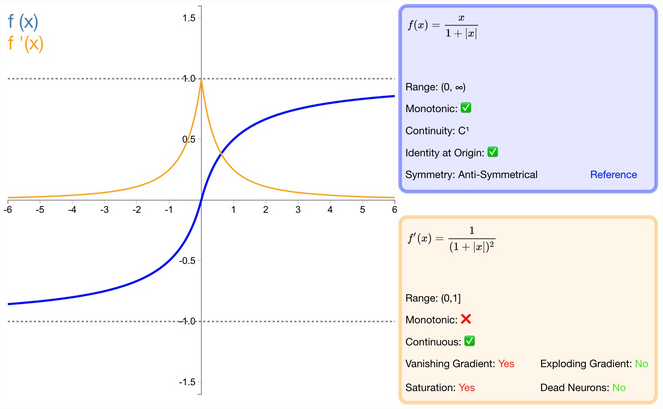
什么是 softsign 激活函数?
Softsign 是 tanh 激活函数的另一个替代选择,比 tanh 更好的解决梯度消失 (gradient vanishing) 的问题
![]()
优点
- softsign 是 tanh 激活函数的另一个替代选择;
- softsign 是反对称、去中心、可微分,并返回 −1 和 1 之间的值;
- softsign 更平坦的曲线与更慢的下降导数表明它可以更高效地学习;
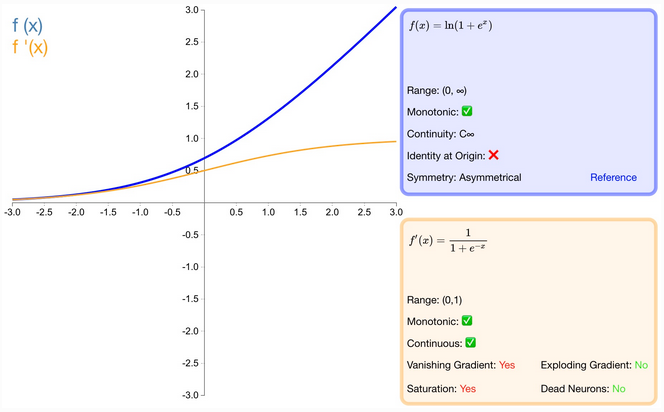
什么是 Softplus 激活函数?
softplus 可以看作是 Relu 的平滑,softplus 和 ReLu 与脑神经元激活频率函数有神似的地方
![]()
优点
- 作为 relu 的一个不错的替代选择,softplus 能够返回任何大于 0 的值。
- 与 relu 不同,softplus 的导数是连续的、非零的,无处不在,从而防止出现死神经元
缺点
- 导数常常小于 1,也可能出现梯度消失的问题。
- softplus 另一个不同于 relu 的地方在于其不对称性,不以零为中心,可能会妨碍学习
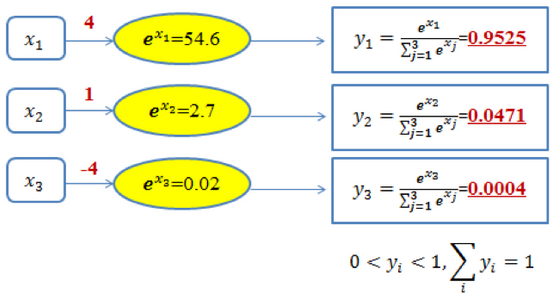
什么是 softmax 激活函数?
常用于神经网络的最后一层,并作为输出层进行多分类运算,计算方式是对输入的每个元素值 x 求以自然常数 e 为底的指数,然后再分别除以他们的和
图 13 给出了三类分类问题的 softmax 输出示意图。在图中,对于取值为 4、1 和 - 4 的 x1、x2 和 x3,通过 softmax 变换后,将其映射到 (0,1) 之间的概率值,且输出结果的值累加起来为 1,因此可将输出概率最大的作为分类目标
![]()
什么是 elu 激活函数?
指数线性单元,它试图将激活函数的输出平均值接近零,从而加快学习速度。同时,它还能通过正值的标识来避免梯度消失的问题。根据一些研究显示,ELU 分类精确度是高于 Relu 的
![]()
优点
- 导数收敛为零,从而提高学习效率;
- 能得到负值输出,这能帮助网络向正确的方向推动权重和偏置变化;
- 防止死神经元出现
缺点
- 计算量大,其表现并不一定比 ReLU 好;
- 无法避免梯度爆炸问题
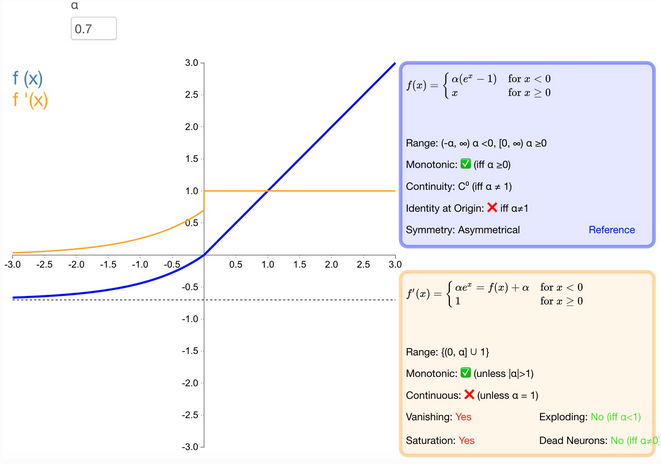
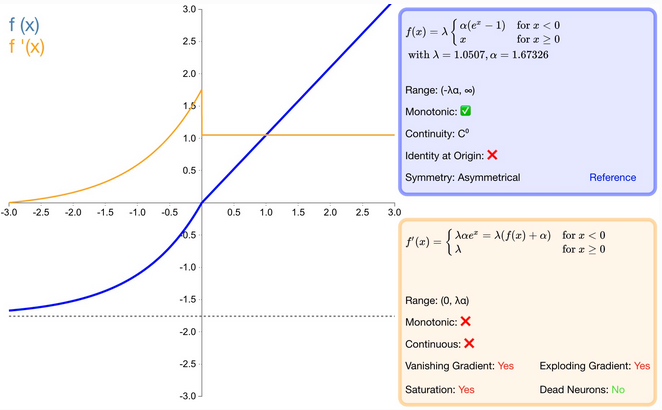
什么是 selu 激活函数?
可伸缩的指数线性单元,elu 乘了个 , 经过该激活函数后使得样本分布自动归一化到 0 均值和单位方差 (自归一化,保证训练过程中梯度不会爆炸或消失,效果比 Batch Normalization 要好)
![]()
优点
- SELU 是 ELU 的一个变种。其中 λ 和 α 是固定数值(分别为 1.0507 和 1.6726);
- 经过该激活函数后使得样本分布自动归一化到 0 均值和单位方差;
- 不会出现梯度消失或爆炸问题;
激活函数 sigmoid 和 softmax 的区别?
- sigmoid 把一个值映射为 [0,1];而 softmax 将 K 个值映射为 K 维的向量,并且和为 1
- 二分类问题时 sigmoid 和 softmax 是一样的,求的都是 交叉熵损失 (CrossEntropyLoss)
- Softmax 函数基于多项分布 (nultinomial distribution),而 Sigmoid 函数则基于伯努利分布 (bernoulli);
- Softmax 函数回归进行多分类时,类与类之间是互斥的,而 Sigmoid 函数输出的类别并不是互斥的
为什么 LSTM 模型中既存在 sigmoid 又存在 tanh 两种激活函数?
- sigmoid 用在了各种 gate 上,产生 0~1 之间的值,这个一般只有 sigmoid 最直接了
- tanh 用在了状态和输出上,是对数据的处理,这个用其他激活函数或许也可以
可以在输出层中使用 Relu 功能吗?
- 不可以,必须在隐藏层中使用 Relu 功能
- 因为 Relu 是左饱和激活函数,某些情况下输出会为 0,导致网络后续不会再更新
为什么 tanh 收敛速度比 sigmoid 快?
- 输出值比较: 多层隐藏激活的前提下,tanh 激活输出为 [-1, 1],而 sigmoid 为 (0, 1), tanh 的激活值以 0 为中心,sigmoid 在所有层的梯度和输出层同正负,所以 tanh 可以更快收敛
- 导数区间比较: 两个函数的求导如下,可知 tanh 比 sigmoid 具有更大的梯度值,可以更快进行收敛
神经网络中 ReLU 是线性还是非线性函数?为什么 relu 这种 “看似线性”(分段线性)的激活函数所形成的网络,居然能够增加非线性的表达能力?
- relu 是非线性激活函数
- 如果把线性网络看成一个大的矩阵 M。那么输入样本 A 和 B,则会经过同样的线性变换 MA,MB(这里 A 和 B 经历的线性变换矩阵 M 是一样的)
- 的确对于单一的样本 A,经过由 relu 激活函数所构成神经网络,其过程确实可以等价是经过了一个线性变换 M1,但是对于样本 B,在经过同样的网络时,由于每个神经元是否激活(0 或者 Wx+b)与样本 A 经过时情形不同了(不同样本),因此 B 所经历的线性变换 M2 并不等于 M1。因此,relu 构成的神经网络虽然对每个样本都是线性变换,但是不同样本之间经历的线性变换 M 并不一样,所以整个样本空间在经过 relu 构成的网络时其实是经历了非线性变换的
为什么 relu 不是全程可微 / 可导也能用于基于梯度的学习?
- 从数学的角度看 relu 在 0 点不可导,因为它的左导数和右导数不相等;但在实现时通常会返回左导数或右导数的其中一个,而不是报告一个导数不存在的错误,从而避免了这个问题