B09 - 图像处理 - 轮廓
找到图片上目标的轮廓,并对图片进行分割
图像分割之区域生长?
![]()
- 区域生长的基本方法是,对于一组 “种子” 点,通过把与种子具有相同预定义性质(如灰度或颜色范围)的邻域像素合并到种子像素所在的区域中,再将新像素作为新的种子不断重复这一过程,直到没有满足条件的像素为止
- 种子点的选取经常采用人工交互方法实现,也可以寻找目标物体并提取物体内部点,或利用其它算法找到的特征点作为种子点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40def getGrayDiff(image, currentPoint, tmpPoint): # 求两个像素的距离
return abs(int(image[currentPoint[0], currentPoint[1]]) - int(image[tmpPoint[0], tmpPoint[1]]))
# 区域生长算法
def regional_growth(img, seeds, thresh=5):
height, weight = img.shape
seedMark = np.zeros(img.shape)
seedList = []
for seed in seeds:
if (0<seed[0]<height and 0<seed[1]<weight): seedList.append(seed)
label = 1 # 种子位置标记
connects = [(-1,-1), (0,-1), (1,-1), (1,0), (1,1), (0,1), (-1,1), (-1,0)] # 8 邻接连通
while (len(seedList) > 0): # 如果列表里还存在点
currentPoint = seedList.pop(0) # 将最前面的那个抛出
seedMark[currentPoint[0], currentPoint[1]] = label # 将对应位置的点标记为 1
for i in range(8): # 对这个点周围的8个点一次进行相似性判断
tmpX = currentPoint[0] + connects[i][0]
tmpY = currentPoint[1] + connects[i][1]
if tmpX<0 or tmpY<0 or tmpX>=height or tmpY>=weight: # 是否超出限定阈值
continue
grayDiff = getGrayDiff(img, currentPoint, (tmpX, tmpY)) # 计算灰度差
if grayDiff<thresh and seedMark[tmpX,tmpY]==0:
seedMark[tmpX, tmpY] = label
seedList.append((tmpX, tmpY))
return seedMark
# 区域生长 主程序
img = cv2.imread("../images/Fig1051a.tif", flags=0)
# # 灰度直方图
# histCV = cv2.calcHist([img], [0], None, [256], [0, 256]) # 灰度直方图
# OTSU 全局阈值处理
ret, imgOtsu = cv2.threshold(img, 127, 255, cv2.THRESH_OTSU) # 阈值分割, thresh=T
# 自适应局部阈值处理
binaryMean = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 5, 3)
# 区域生长图像分割
# seeds = [(10, 10), (82, 150), (20, 300)] # 直接给定 种子点
imgBlur = cv2.blur(img, (3,3)) # cv2.blur 方法
_, imgTop = cv2.threshold(imgBlur, 250, 255, cv2.THRESH_BINARY) # 高百分位阈值产生种子区域
nseeds, labels, stats, centroids = cv2.connectedComponentsWithStats(imgTop) # 过滤连通域,获得质心点 (x,y)
seeds = centroids.astype(int) # 获得质心像素作为种子点
imgGrowth = regional_growth(img, seeds, 8)
show_images([img,imgOtsu,binaryMean,imgGrowth])
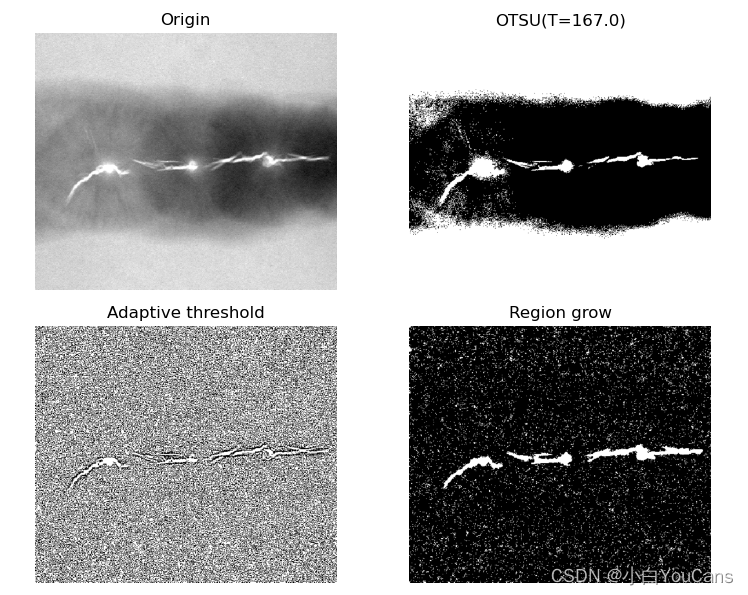
图像分割之区域分割?
![]()
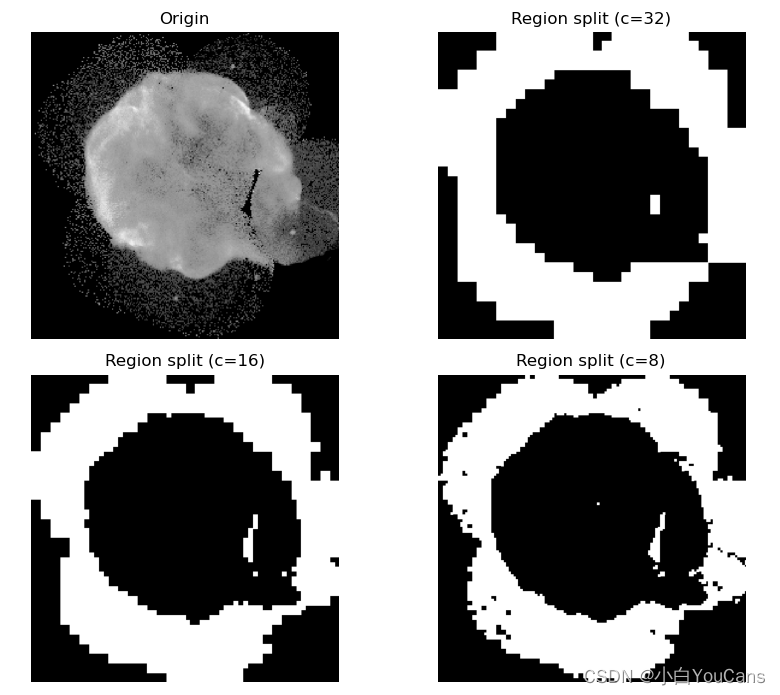
- 生成是分割的逆过程,都可以完成对图像的分割
- 分离过程先判断当前区域是否满足目标的特征测度,如果不满足则将当前区域分离为多个子区域进行判断;不断重复判断、分离,直到拆分到最小区域为止。典型的区域分裂方法,是将区域按照 4 个象限分裂为 4 个子区域,可以简化处理和运算过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32def SplitMerge(src, dst, h, w, h0, w0, maxMean, minVar, cell=4):
win = src[h0: h0+h, w0: w0+w]
mean = np.mean(win) # 窗口区域的均值
var = np.std(win, ddof=1) # 窗口区域的标准差,无偏样本标准差
if (mean<maxMean) and (var>minVar) and (h<2*cell) and (w<2*cell):
# 该区域满足谓词逻辑条件,判为目标区域,设为白色
dst[h0:h0+h, w0:w0+w] = 255 # 白色
# print("h0={}, w0={}, h={}, w={}, mean={:.2f}, var={:.2f}".
# format(h0, w0, h, w, mean, var))
else: # 该区域不满足谓词逻辑条件
if (h>cell) and (w>cell): # 区域能否继续分拆?继续拆
SplitMerge(src, dst, (h+1)//2, (w+1)//2, h0, w0, maxMean, minVar, cell)
SplitMerge(src, dst, (h+1)//2, (w+1)//2, h0, w0+(w+1)//2, maxMean, minVar, cell)
SplitMerge(src, dst, (h+1)//2, (w+1)//2, h0+(h+1)//2, w0, maxMean, minVar, cell)
SplitMerge(src, dst, (h+1)//2, (w+1)//2, h0+(h+1)//2, w0+(w+1)//2, maxMean, minVar, cell)
# else: # 不能再分拆,判为非目标区域,设为黑色
# src[h0:h0+h, w0:w0+w] = 0 # 黑色
img = cv2.imread("../images/Fig0938a.tif", flags=0)
hImg, wImg = img.shape
mean = np.mean(img) # 窗口区域的均值
var = np.std(img, ddof=1) # 窗口区域的标准差,无偏样本标准差
print("h={}, w={}, mean={:.2f}, var={:.2f}".format(hImg, wImg, mean, var))
maxMean = 80 # 均值上界
minVar = 10 # 标准差下界
src = img.copy()
dst1 = np.zeros_like(img)
dst2 = np.zeros_like(img)
dst3 = np.zeros_like(img)
SplitMerge(src, dst1, hImg, wImg, 0, 0, maxMean, minVar, cell=32)
SplitMerge(src, dst2, hImg, wImg, 0, 0, maxMean, minVar, cell=16)
SplitMerge(src, dst3, hImg, wImg, 0, 0, maxMean, minVar, cell=8)
show_images([img,dst1,dst2,dst3])
图像分割之 K 均值聚类?
![]()
- 聚类方法的思想是将样本集合按照其特征的相似性划分为若干类别,使同一类别样本的特征具有较高的相似性,不同类别样本的特征具有较大的差异性
- 基于聚类的区域分割,就是基于图像的灰度、颜色、纹理、形状等特征,用聚类算法把图像分成若干类别或区域,使每个点到聚类中心的均值最小
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20img = cv2.imread("../images/imgB6.jpg", flags=1) # 读取彩色图像(BGR)
dataPixel = np.float32(img.reshape((-1, 3)))
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 200, 0.1) # 终止条件
flags = cv2.KMEANS_RANDOM_CENTERS # 起始的中心选择
K = 3 # 设置聚类数
_, labels, center = cv2.kmeans(dataPixel, K, None, criteria, 10, flags)
centerUint = np.uint8(center)
classify = centerUint[labels.flatten()] # 将像素标记为聚类中心颜色
imgKmean3 = classify.reshape((img.shape)) # 恢复为二维图像
K = 4 # 设置聚类数
_, labels, center = cv2.kmeans(dataPixel, K, None, criteria, 10, flags)
centerUint = np.uint8(center)
classify = centerUint[labels.flatten()] # 将像素标记为聚类中心颜色
imgKmean4 = classify.reshape((img.shape)) # 恢复为二维图像
K = 5 # 设置聚类数
_, labels, center = cv2.kmeans(dataPixel, K, None, criteria, 10, flags)
centerUint = np.uint8(center)
classify = centerUint[labels.flatten()] # 将像素标记为聚类中心颜色
imgKmean5 = classify.reshape((img.shape)) # 恢复为二维图像
show_images([img,imgKmean3,imgKmean4,imgKmean5])

图像分割之 “线性迭代聚类(SLIC)” 超像素分割?
![]()
- 超像素:由一系列位置相邻,颜色、亮度、纹理等特征相似的像素点组成的小区域,我们将其视为具有代表性的大 “像素”,称为超像素。超像素技术通过像素的组合得到少量(相对于像素数量)具有感知意义的超像素区域,代替大量原始像素表达图像特征,可以极大地降低图像处理的复杂度、减小计算量
- 超像素分割:基于依赖于图像的颜色信息及空间关系信息,将图像分割为远超于目标个数、远小于像素数量的超像素块,达到尽可能保留图像中所有目标的边缘信息的目的,从而更好的辅助后续视觉任务
- 常用的超像素分割方法有:简单线性迭代聚类(Simple Linear Iterative Clustering,SLIC)、能量驱动采样(Super-pixels Extracted via Energy-Driven Sampling,SEEDS)和线性谱聚类(Linear Spectral Clustering,LSC)
1
2
3
4
5
6
7
8
9
10
11
12
13img = cv2.imread("../images/imgLena.tif", flags=1) # 读取彩色图像(BGR)
imgHSV = cv2.cvtColor(img, cv2.COLOR_BGR2HSV_FULL) # BGR-HSV 转换
# SLIC 算法
slic = cv2.ximgproc.createSuperpixelSLIC(img, region_size=10, ruler=10.0) # 初始化 SLIC
slic.iterate(10) # 迭代次数,越大效果越好
label_slic = slic.getLabels() # 获取超像素标签
number_slic = slic.getNumberOfSuperpixels() # 获取超像素数目
mask_slic = slic.getLabelContourMask() # 获取 Mask,超像素边缘 Mask==1
mask_color = np.array([mask_slic for i in range(3)]).transpose(1, 2, 0) # 转为 3 通道
# mask_color= cv2.COLOR_GRAY2RGB(mask_slic) # 灰度 Mask 转为 RGB
img_slic = cv2.bitwise_and(img, img, mask=cv2.bitwise_not(mask_slic)) # 在原图上绘制超像素边界
imgSlic = cv2.add(img_slic, mask_color)
show_images([img,mask_slic,img_slic,imgSlic])

图像分割之 “SEEDS” 超像素分割?
![]()
- 超像素个体应在视觉上一致,特别是颜色应尽可能均匀。SLIC 使用欧几里德距离来度量像素点的相似度,不能反映颜色的方差
- SEEDS 每次迭代只对处于超像素边界的像素点进行更新,通过能量函数的值来决定这个像素点是否转移到相邻的超像素块内
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15img = cv2.imread("../images/imgLena.tif", flags=1) # 读取彩色图像(BGR)
imgHSV = cv2.cvtColor(img, cv2.COLOR_BGR2HSV_FULL) # BGR-HSV 转换
# SLIC 算法
slic = cv2.ximgproc.createSuperpixelSLIC(img, region_size=20, ruler=10.0) # 初始化 SLIC
slic.iterate(10) # 迭代次数,越大效果越好
mask_slic = slic.getLabelContourMask() # 获取 Mask,超像素边缘 Mask==1
img_slic = cv2.bitwise_and(img, img, mask=cv2.bitwise_not(mask_slic)) # 在原图上绘制超像素边界
# SEEDS 算法,注意图片长宽的顺序为 w, h, c
seeds = cv2.ximgproc.createSuperpixelSEEDS(img.shape[1], img.shape[0], img.shape[2], 2000, 15, 3, 5, True)
seeds.iterate(imgHSV, 10) # 输入图像大小必须与初始化形状相同,迭代次数为10
mask_seeds = seeds.getLabelContourMask() # 获取 Mask,超像素边缘 Mask==1
label_seeds = seeds.getLabels() # 获取超像素标签
number_seeds = seeds.getNumberOfSuperpixels() # 获取超像素数目
img_seeds = cv2.bitwise_and(img, img, mask=cv2.bitwise_not(mask_seeds))
show_images([img,mask_seeds,img_slic,img_seeds])

图像分割之 “线性谱聚类 (LSC)” 超像素分割?
![]()
- 线性谱聚类(Linear Spectral Clustering,LSC)是 SLIC 的改进方案,可以生成紧凑且均匀的超像素,将图像分割成大小均匀,边界光滑的小块
- 谱聚类是从图论中演化出来的算法,其基本思想是把所有数据看做空间中的点,点之间可以用边连接。距离较远的点之间的边权重值较低,而距离较近的点之间的边权重值较高。通过对所有数据点组成的图进行切图,让切图后不同的子图间边权重和尽可能的低,而子图内的边权重和尽可能的高,从而达到聚类的目的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16img = cv2.imread("../images/imgLena.tif", flags=1) # 读取彩色图像(BGR)
imgHSV = cv2.cvtColor(img, cv2.COLOR_BGR2HSV_FULL) # BGR-HSV 转换
# SLIC 算法
slic = cv2.ximgproc.createSuperpixelSLIC(img, region_size=20, ruler=10.0) # 初始化 SLIC
slic.iterate(10) # 迭代次数,越大效果越好
mask_slic = slic.getLabelContourMask() # 获取 Mask,超像素边缘 Mask==1
img_slic = cv2.bitwise_and(img, img, mask=cv2.bitwise_not(mask_slic)) # 在原图上绘制超像素边界
# LSC 算法 (Linear Spectral Clustering)
lsc = cv2.ximgproc.createSuperpixelLSC(img)
lsc.iterate(10)
mask_lsc = lsc.getLabelContourMask()
label_lsc = lsc.getLabels()
number_lsc = lsc.getNumberOfSuperpixels()
mask_inv_lsc = cv2.bitwise_not(mask_lsc)
img_lsc = cv2.bitwise_and(img, img, mask=mask_inv_lsc
show_images([img,mask_lsc,img_slic,img_lsc])

图像分割之超像素分割区别?
![]()
- 简单线性迭代聚类、能量驱动采样、线性谱聚类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23img = cv2.imread("../images/imgBuilding2.png", flags=1) # 读取彩色图像(BGR)
imgHSV = cv2.cvtColor(img, cv2.COLOR_BGR2HSV_FULL) # BGR-HSV 转换
# SLIC 算法 (Simple Linear Iterative Clustering)
slic = cv2.ximgproc.createSuperpixelSLIC(img, region_size=20, ruler=10.0) # 初始化 SLIC
slic.iterate(10) # 迭代次数,越大效果越好
mask_slic = slic.getLabelContourMask() # 获取 Mask,超像素边缘 Mask==1
img_slic = cv2.bitwise_and(img, img, mask=cv2.bitwise_not(mask_slic)) # 在原图上绘制超像素边界
# SEEDS 算法 (Super-pixels Extracted via Energy-Driven Sampling)
seeds = cv2.ximgproc.createSuperpixelSEEDS(img.shape[1], img.shape[0], img.shape[2], 2000, 15, 3, 5, True)
seeds.iterate(img, 10) # 输入图像大小必须与初始化形状相同,迭代次数为10
mask_seeds = seeds.getLabelContourMask() # 获取 Mask,超像素边缘 Mask==1
label_seeds = seeds.getLabels() # 获取超像素标签
number_seeds = seeds.getNumberOfSuperpixels() # 获取超像素数目
img_seeds = cv2.bitwise_and(img, img, mask=cv2.bitwise_not(mask_seeds))
# LSC 算法 (Linear Spectral Clustering)
lsc = cv2.ximgproc.createSuperpixelLSC(img)
lsc.iterate(10)
mask_lsc = lsc.getLabelContourMask()
label_lsc = lsc.getLabels()
number_lsc = lsc.getNumberOfSuperpixels()
mask_inv_lsc = cv2.bitwise_not(mask_lsc)
img_lsc = cv2.bitwise_and(img, img, mask=mask_inv_lsc)
show_images([img,img_slic,img_seeds,img_lsc])

图像分割之均值漂移 (mean shift) 算法?
![]()
- 通过反复迭代搜索特征空间中样本最密集的区域,搜索点沿着样本点密度增加的方向 “漂移” 到局部密度极大值点。采用基于核密度估计的爬山算法,自适应调整步长进行迭代搜索,可以收敛到局部极值
- 基于 Mean Shift 的目标跟踪技术采用核概率密度描述目标特征,对于图像分割通常采用直方图对目标建模,然后通过相似性度量搜索目标位置,实现目标的匹配与跟踪
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35def meanShiftTracker(src, trackWindow):
# meanShift 算法: 在 dst 寻找目标窗口,找到后返回目标窗口位置
hsv = cv2.cvtColor(src, cv2.COLOR_BGR2HSV) # BGR-HSV 转换
dst = cv2.calcBackProject([hsv], [0], roiHist, [0, 180], 1) # 计算反向投影
term_crit = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 1)
_, trackWin = cv2.meanShift(dst, trackWindow, term_crit)
x, y, w, h = trackWin
imgTrack = src.copy()
imgTrack = cv2.rectangle(imgTrack, (x, y), (x + w, y + h), 255, 2)
print(x, y, w, h)
return imgTrack
img = cv2.imread("../images/FigCross1.png", flags=1) # 基准参考图像
imgHSV = cv2.cvtColor(img, cv2.COLOR_BGR2HSV_FULL) # BGR-HSV 转换
# 设置初始化的窗口位置
# print("Select a ROI and then press SPACE or ENTER button!\n")
# roi = cv2.selectROI(img, showCrosshair=True, fromCenter=False)
# x0, y0, w, h = roi # 矩形裁剪区域 (ymin:ymin+h, xmin:xmin+w) 的位置参数
# rect = (x0, y0, w, h) # 边界框矩形的坐标和尺寸 # rect = (990 311 94 72)
(x0, y0, w, h) = (990, 310, 95, 72) # 直接设置矩形窗口的位置参数,也可以鼠标框选 ROI
trackWindow = (x0, y0, w, h) # 矩形 ROI
print(x0, y0, w, h)
imgROI = np.zeros_like(img) # 创建与 image 相同形状的黑色图像
imgROI[y0:y0+h, x0:x0+w] = img[y0:y0+h, x0:x0+w].copy()
frameROI = imgROI[y0:y0+h, x0:x0+w] # 设置追踪的区域
roiHSV = cv2.cvtColor(frameROI, cv2.COLOR_BGR2HSV) # BGR-HSV 转换
# 取 HSV 在 (0,60,32)~(180,255,255) 之间的部分
mask = cv2.inRange(roiHSV, np.array((0., 60., 32.)), np.array((180., 255., 255.)))
roiHist = cv2.calcHist([roiHSV], [0], mask, [180], [0, 180]) # 计算直方图
cv2.normalize(roiHist, roiHist, 0, 255, cv2.NORM_MINMAX) # 归一化
# # meanShift 算法: 在 dst 寻找目标窗口,找到后返回目标窗口位置
img1 = cv2.imread("../images/FigCross2.png", flags=1) # 读取彩色图像(BGR)
imgTrack1 = meanShiftTracker(img1, trackWindow)
img2 = cv2.imread("../images/FigCross4.png", flags=1) # 读取彩色图像(BGR)
imgTrack2 = meanShiftTracker(img2, trackWindow)
show_images([img,imgROI,img1,imgTrack1,img2,imgTrack2])

图像分割之图割法 (graph cuts)?
![]()
- 将图像映射为带权的无向图,把像素视为节点,两个节点之间的边的权重对应于两个像素之间相似性的度量,割的容量就对应于能量函数;使用最大流最小割算法对图进行切割,得到的最小割就对应于最优图像分割
- GraphCut 算法需要用户在前景和背景处各画几笔作为输入,由此建立各个像素点与前景背景相似度的赋权图,并通过求解最小割进行图像的前景和背景分割
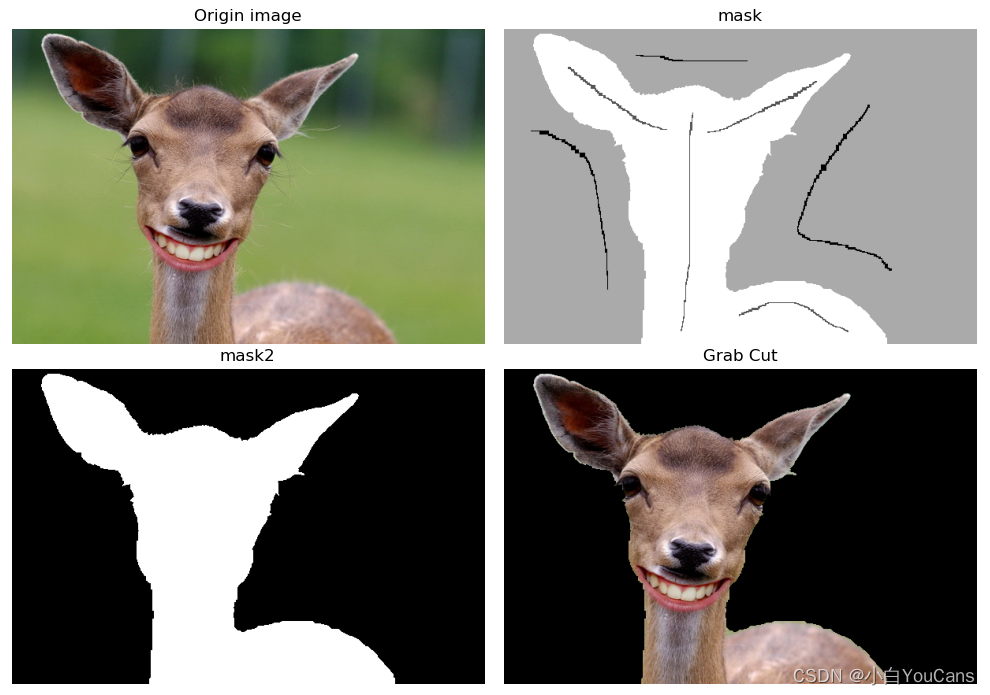
图像分割之图割法 (grab cut)?
![]()
- GrabCut 算法是对 GraphCut 的改进,使用高斯混合模型(GMM)对背景和目标建立模型,采用迭代方法实现分割能量的最小化,同时支持不完整的标记
- GrabCut 算法有效利用了图像中的纹理(颜色)信息和边界(反差)信息,只需要要少量的人工交互操作就可以对目标实现较好的分割效果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21image = cv2.imread("../images/imgGaia.tif", flags=1) # 读取彩色图像(BGR)
mask = np.zeros(image.shape[:2], dtype="uint8")
# 定义矩形框,框选目标前景
# rect = (118, 125, 220, 245) # 直接设置矩形的位置参数,也可以鼠标框选 ROI
print("Select a ROI and then press SPACE or ENTER button!\n")
roi = cv2.selectROI(image, showCrosshair=True, fromCenter=False)
xmin, ymin, w, h = roi # 矩形裁剪区域 (ymin:ymin+h, xmin:xmin+w) 的位置参数
rect = (xmin, ymin, w, h) # 边界框矩形的坐标和尺寸
imgROI = np.zeros_like(image) # 创建与 image 相同形状的黑色图像
imgROI[ymin:ymin + h, xmin:xmin + w] = image[ymin:ymin + h, xmin:xmin + w].copy()
print(xmin, ymin, w, h)
fgModel = np.zeros((1, 65), dtype="float") # 前景模型, 13*5
bgModel = np.zeros((1, 65), dtype="float") # 背景模型, 13*5
iter = 5
(mask, bgModel, fgModel) = cv2.grabCut(image, mask, rect, bgModel, fgModel, iter,
mode=cv2.GC_INIT_WITH_RECT) # 框选前景分割模式
# 将所有确定背景和可能背景像素设置为 0,而确定前景和可能前景像素设置为 1
maskOutput = np.where((mask == cv2.GC_BGD) | (mask == cv2.GC_PR_BGD), 0, 1)
maskGrabCut = (maskOutput * 255).astype("uint8")
imgGrabCut = cv2.bitwise_and(image, image, mask=maskGrabCut)
show_images([image,imgROI,maskBGD,maskPBGD,maskGrabCut,imgGrabCut])

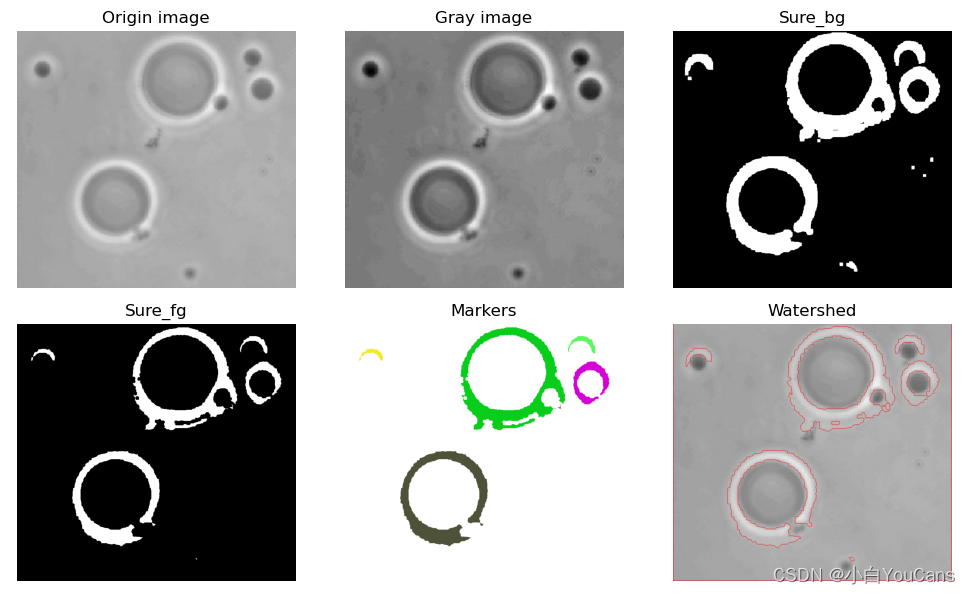
图像分割之分水岭算法?
![]()
- 分水岭算法是一种图像区域分割法,以临近像素间的相似性作为重要特征,从而将空间位置相近且灰度值相近的像素点互相连接起来,构成一个封闭的轮廓
- 分水岭方法是一种基于拓扑理论的数学形态学的分割方法,基本思想是把图像看作测地学上的拓扑地貌,将像素点的灰度值视为海拔高度,整个图像就像一张高低起伏的地形图。每个局部极小值及其影响区域称为集水盆,集水盆的边界则形成分水岭
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26img = cv2.imread("../images/Fig1039a.tif", flags=1) # 读取彩色图像(BGR)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转为灰度图像
# 阈值分割,将灰度图像分为黑白二值图像
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU)
# 形态学操作,生成 "确定背景" 区域
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3)) # 生成 3*3 结构元
opening = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel, iterations=2) # 开运算,消除噪点
sure_bg = cv2.dilate(opening, kernel, iterations=3) # 膨胀操作,生成 "确定背景" 区域
# 距离变换,生成 "确定前景" 区域
distance = cv2.distanceTransform(opening, cv2.DIST_L2, 5) # DIST_L2: 3/5
_, sure_fg = cv2.threshold(distance, 0.1*distance.max(), 255, cv2.THRESH_BINARY) # 阈值选择 0.1*max 效果较好
sure_fg = np.uint8(sure_fg)
# 连通域处理
ret, component = cv2.connectedComponents(sure_fg, connectivity=8) # 对连通区域进行标号,序号为 0-N-1
markers = component + 1 # OpenCV 分水岭算法设置标注从 1 开始,而连通域编从 0 开始
# 去除连通域中的背景区域部分
unknown = cv2.subtract(sure_bg, sure_fg) # 待定区域,前景与背景的重合区域
markers[unknown==255] = 0 # 去掉属于背景的区域 (置零)
# 分水岭算法标注目标的轮廓
markers = cv2.watershed(img, markers) # 分水岭算法,将所有轮廓的像素点标注为 -1
kinds = markers.max() # 标注连通域的数量
# 把轮廓添加到原始图像上
imgWatershed = img.copy()
imgWatershed[markers == -1] = [0, 0, 255] # 将分水岭算法标注的轮廓点设为红色
print(img.shape, markers.shape, markers.max(), markers.min(),ret)
show_images([img,gray,sure_bg,sure_fg,markers,imgWatershed])
图像分割之基于 Sobel 梯度的分水岭算法?
![]()
- 在分水岭算法之前通常要对图像进行滤波以消除噪点,但也使弱边缘被平滑,分水岭的峰值弱化。梯度处理可以强化边缘,把梯度图像作为输入图像,可以避免弱边缘在分水岭填充过程中被淹没。可以使用 Sobel、Canny 梯度算子,也可以用形态学梯度操作获得梯度图像
- 基于梯度的分水岭算法通过梯度函数使得集水盆只响应想要探测的目标,对微弱边缘也有良好的响应,但图像中的噪声容易导致过分割。对此,在对梯度图像进行阈值分割转换为二值图像后,运用开运算消除噪点非常重要,可以有效地抑制梯度图像的过分割
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39img = cv2.imread("../images/Fig1039a.tif", flags=1) # 读取彩色图像(BGR)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转为灰度图像
# 高斯模糊
Gauss = cv2.GaussianBlur(gray, (5,5), sigmaX=10.0)
# 计算 Sobel 梯度算子
SobelX = cv2.Sobel(Gauss, cv2.CV_32F, 1, 0) # 计算 x 轴方向
SobelY = cv2.Sobel(Gauss, cv2.CV_32F, 0, 1) # 计算 y 轴方向
grad = np.uint8(cv2.normalize(np.sqrt(SobelX**2+SobelY**2), None, 0, 255, cv2.NORM_MINMAX))
# 阈值分割,将灰度图像分为黑白二值图像
_, thresh = cv2.threshold(np.uint8(grad), 0.2*grad.max(), 255, cv2.THRESH_BINARY)
# 形态学操作,生成 "确定背景" 区域
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3)) # 生成 3*3 结构元
opening = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel, iterations=2) # 开运算,消除噪点
sure_bg = cv2.dilate(opening, kernel, iterations=3) # 膨胀操作,生成 "确定背景" 区域
# 距离变换,生成 "确定前景" 区域
distance = cv2.distanceTransform(opening, cv2.DIST_L2, 5) # DIST_L2: 3/5
_, sure_fg = cv2.threshold(distance, 0.1 * distance.max(), 255, 0) # 阈值选择 0.1*max 效果较好
sure_fg = np.uint8(sure_fg)
# 连通域处理
ret, component = cv2.connectedComponents(sure_fg, connectivity=8) # 对连通区域进行标号,序号为 0-N-1
markers = component + 1 # OpenCV 分水岭算法设置标注从 1 开始,而连通域编从 0 开始
kinds = markers.max() # 标注连通域的数量
maxKind = np.argmax(np.bincount(markers.flatten())) # 出现最多的序号,所占面积最大,选为底色
markersBGR = np.ones_like(img) * 255
for i in range(kinds):
if (i!=maxKind):
colorKind = [np.random.randint(0, 255), np.random.randint(0, 255), np.random.randint(0, 255)]
markersBGR[markers==i] = colorKind
# 去除连通域中的背景区域部分
unknown = cv2.subtract(sure_bg, sure_fg) # 待定区域,前景与背景的重合区域
markers[unknown == 255] = 0 # 去掉属于背景的区域 (置零)
# 分水岭算法标注目标的轮廓
markers = cv2.watershed(img, markers) # 分水岭算法,将所有轮廓的像素点标注为 -1
kinds = markers.max() # 标注连通域的数量
# 把轮廓添加到原始图像上
imgWatershed = img.copy()
imgWatershed[markers == -1] = [0, 0, 255] # 将分水岭算法标注的轮廓点设为红色
print(img.shape, markers.shape, markers.max(), markers.min(), ret)
show_images([img,grad,sure_bg,sure_fg,markersBGR,imgWatershed])

图像分割之基于形态学的分水岭算法?
![]()
- 梯度处理可以使用 Sobel、Canny 梯度算子,也可以用形态学梯度操作获得梯度图像
- 基于梯度的分水岭算法对微弱的边缘有着良好的响应,但图像中的噪声容易导致图像的过分割。对此,在对梯度图像进行阈值分割转换为二值图像后,运用开运算消除噪点非常重要,可以有效地抑制梯度图像的过分割
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36img = cv2.imread("../images/Fig1039a.tif", flags=1) # 读取彩色图像(BGR)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转为灰度图像
# 图像的形态学梯度
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5)) # 生成 5*5 结构元
grad = cv2.morphologyEx(gray, cv2.MORPH_GRADIENT, kernel) # 形态学梯度
# 阈值分割,将灰度图像分为黑白二值图像
_, thresh = cv2.threshold(np.uint8(grad), 0.2*grad.max(), 255, cv2.THRESH_BINARY)
# 形态学操作,生成 "确定背景" 区域
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3)) # 生成 3*3 结构元
opening = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel, iterations=2) # 开运算,消除噪点
sure_bg = cv2.dilate(opening, kernel, iterations=3) # 膨胀操作,生成 "确定背景" 区域
# 距离变换,生成 "确定前景" 区域
distance = cv2.distanceTransform(opening, cv2.DIST_L2, 5) # DIST_L2: 3/5
_, sure_fg = cv2.threshold(distance, 0.1 * distance.max(), 255, 0) # 阈值选择 0.1*max 效果较好
sure_fg = np.uint8(sure_fg)
# 连通域处理
ret, component = cv2.connectedComponents(sure_fg, connectivity=8) # 对连通区域进行标号,序号为 0-N-1
markers = component + 1 # OpenCV 分水岭算法设置标注从 1 开始,而连通域编从 0 开始
kinds = markers.max() # 标注连通域的数量
maxKind = np.argmax(np.bincount(markers.flatten())) # 出现最多的序号,所占面积最大,选为底色
markersBGR = np.ones_like(img) * 255
for i in range(kinds):
if (i!=maxKind):
colorKind = [np.random.randint(0, 255), np.random.randint(0, 255), np.random.randint(0, 255)]
markersBGR[markers==i] = colorKind
# 去除连通域中的背景区域部分
unknown = cv2.subtract(sure_bg, sure_fg) # 待定区域,前景与背景的重合区域
markers[unknown == 255] = 0 # 去掉属于背景的区域 (置零)
# 分水岭算法标注目标的轮廓
markers = cv2.watershed(img, markers) # 分水岭算法,将所有轮廓的像素点标注为 -1
kinds = markers.max() # 标注连通域的数量
# 把轮廓添加到原始图像上
imgWatershed = img.copy()
imgWatershed[markers == -1] = [0, 0, 255] # 将分水岭算法标注的轮廓点设为红色
print(img.shape, markers.shape, markers.max(), markers.min(), ret)
show_images([img,grad,sure_bg,sure_fg,markersBGR,imgWatershed])
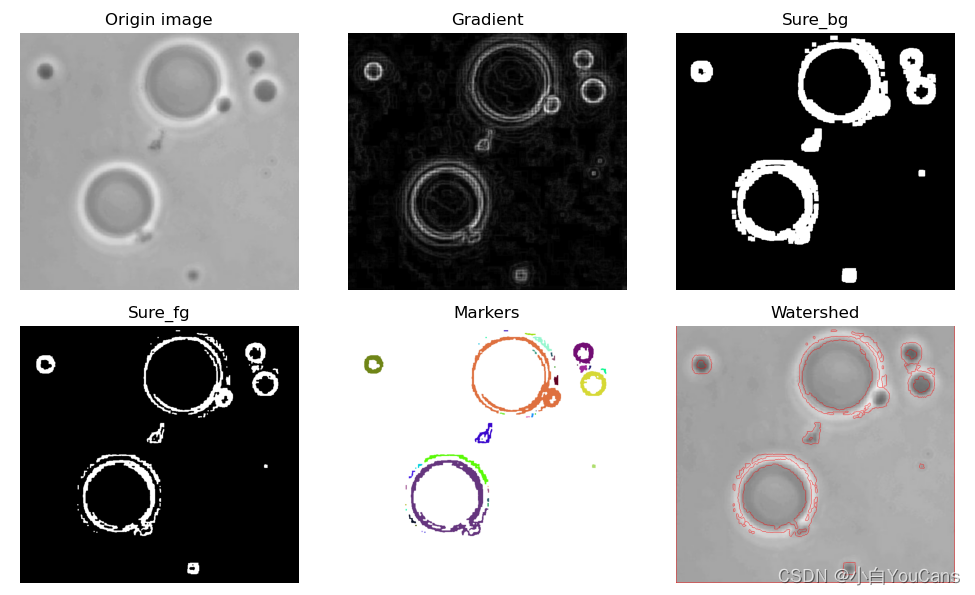
图像分割之基于轮廓标记的分水岭算法?
![]()
- 基于标记的分水岭算法的思想是利用先验知识来帮助分割。本例程先用梯度算子进行边缘检测,然后通过查找图像轮廓,生成标记图像来引导分割
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23img = cv2.imread("../images/imgLena.tif", flags=1) # 读取彩色图像(BGR)
# img = cv2.imread("../images/imgTina.png", flags=1) # 读取彩色图像(BGR)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转为灰度图像
# 查找和绘制图像轮廓
Gauss = cv2.GaussianBlur(gray, (5,5), sigmaX=4.0)
grad = cv2.Canny(Gauss, 50, 150) # Canny 梯度算子
# grad = cv2.Canny(gray, 80, 150) # Canny 梯度算子
grad, contours, hierarchy = cv2.findContours(grad, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 查找图像轮廓
markers = np.zeros(img.shape[:2], np.int32) # 生成标识图像,所有轮廓区域标识为索引号 (index)
for index in range(len(contours)): # 用轮廓的索引号 index 标识轮廓区域
markers = cv2.drawContours(markers, contours, index, (index, index, index), 1, 8, hierarchy)
ContoursMarkers = np.zeros(img.shape[:2], np.uint8)
ContoursMarkers[markers>0] = 255 # 轮廓图像,将所有轮廓区域标识为白色 (255)
# 分水岭算法
markers = cv2.watershed(img, markers) # 分水岭算法,所有轮廓的像素点被标注为 -1
WatershedMarkers = cv2.convertScaleAbs(markers)
# 用随机颜色填充分割图像
bgrMarkers = np.zeros_like(img)
for i in range(len(contours)): # 用随机颜色进行填充
colorKind = [np.random.randint(0, 255), np.random.randint(0, 255), np.random.randint(0, 255)]
bgrMarkers[markers==i] = colorKind
bgrFilled = cv2.addWeighted(img, 0.67, bgrMarkers, 0.33, 0) # 填充后与原始图像融合
show_images([img,grad,ContoursMarkers,WatershedMarkers,bgrMarkers,bgrFilled])

OpenCV 寻找图像轮廓?
![]()
- 轮廓是一系列相连的像素点组成的曲线,代表了物体的基本外形。轮廓常用于形状分析和物体的检测和识别
- 边缘检测根据灰度的突变检测边界,但检测到的边缘通常还是零散的片段,并未构成整体。从背景中分离目标,就要将边缘像素连接构成轮廓。也就是说,轮廓是连续的,边缘不一定都连续。边缘主要是作为图像的特征使用,而轮廓主要用来分析物体的形态
- OpenCV 提供函数 cv. findContours () 从二值图像中寻找轮廓,函数 cv2. drawContours () 绘制轮廓
1
2
3
4
5
6
7
8
9
10img = cv2.imread("../images/pattern1.png", flags=1)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 灰度图像
_, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_OTSU+cv2.THRESH_BINARY_INV)
# 寻找二值化图中的轮廓
binary, contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) # OpenCV3
# contours, hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # OpenCV4~
# # 绘制轮廓
contourPic = img.copy() # OpenCV3.2 之前的早期版本,查找轮廓函数会修改原始图像
contourPic = cv2.drawContours(contourPic, contours, -1, (0, 0, 255), 2) # OpenCV3
show_images([img,gray,contourPic])
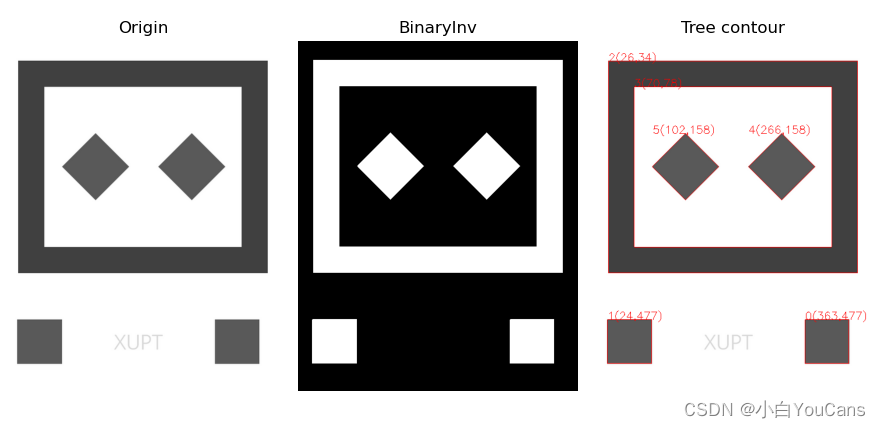
OpenCV 使用 findContours 找边缘轮廓时,如何解析轮廓的层级?
![]()
- cv: : findContours 返回轮廓层次关系是 [1, N, 4],其中 N 是轮廓数量,4 是表示层次关系的四元组:[下一个,上一个,First_Child,父],元组内存储的是轮廓 Contours 的序号
- RETR_EXTERNAL: 只寻找最高层级的轮廓
- RETR_LIST: 最简单的一种寻找方式,它不建立轮廓间的子属关系,也就是所有轮廓都属于同一层级, hierarchy 中的后两个值 [First Child, Parent] 都为 - 1
- RETR_CCOMP: 它把所有的轮廓只分为 2 个层级,不是外层的就是里层的
- RETR_TREE: 完整建立轮廓的层级从属关系
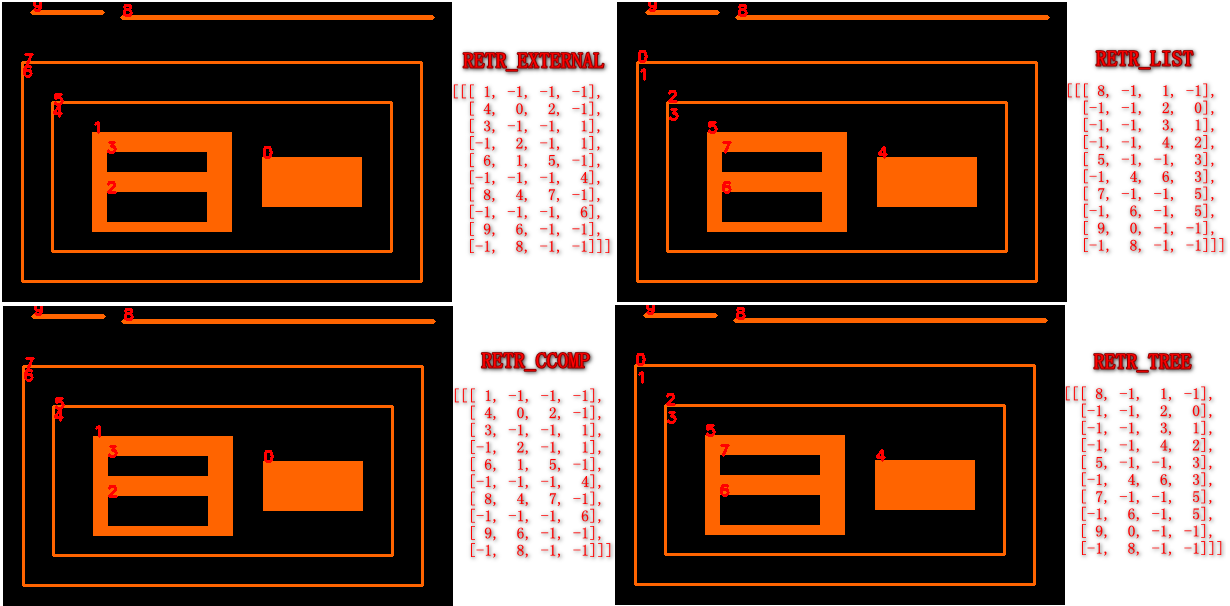
OpenCV 使用 findContours 找边缘轮廓时,返回的点方向具有一致性吗?
![]()
- cv: : findContours 返回的点具有一致的方向,但是外轮廓应逆时针方向,内轮廓顺时针方向
1
2
3
4
5
6
7
8
9
10
11
12
13
14# 模拟数据
points=[326,96,255,297,127,297,225,382,141,618,325,470,491,613,421,393,536,300,391,299]
# points=[325,469,420,393,390,299,255,298,225,380]
img=np.zeros((710,710,3),np.uint8)
# 依次汇出点
LABEL_COLORMAP = imgviz.label_colormap(value=200)
imgs=[]
points_colors=[]
for i in range(0,len(points),2):
x,y=points[i],points[i+1]
getcolor=tuple(LABEL_COLORMAP[(i+1)%len(LABEL_COLORMAP)].tolist())
cv2.circle(img,(x,y),10,getcolor,-1)
points_colors.append(getcolor)
imgs.append(copy.deepcopy(img))
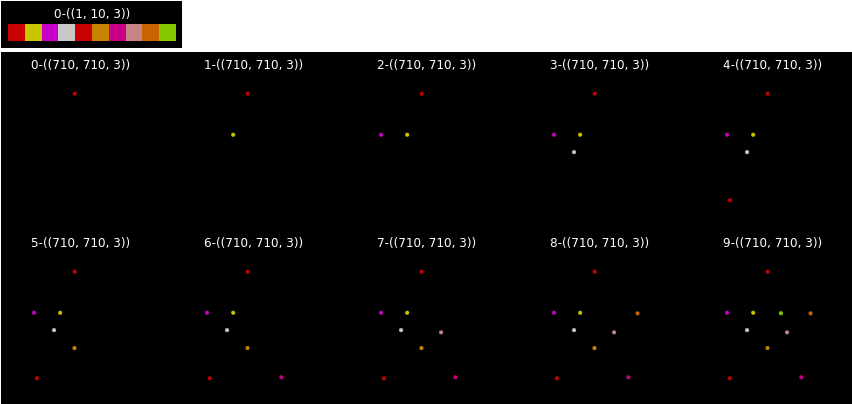
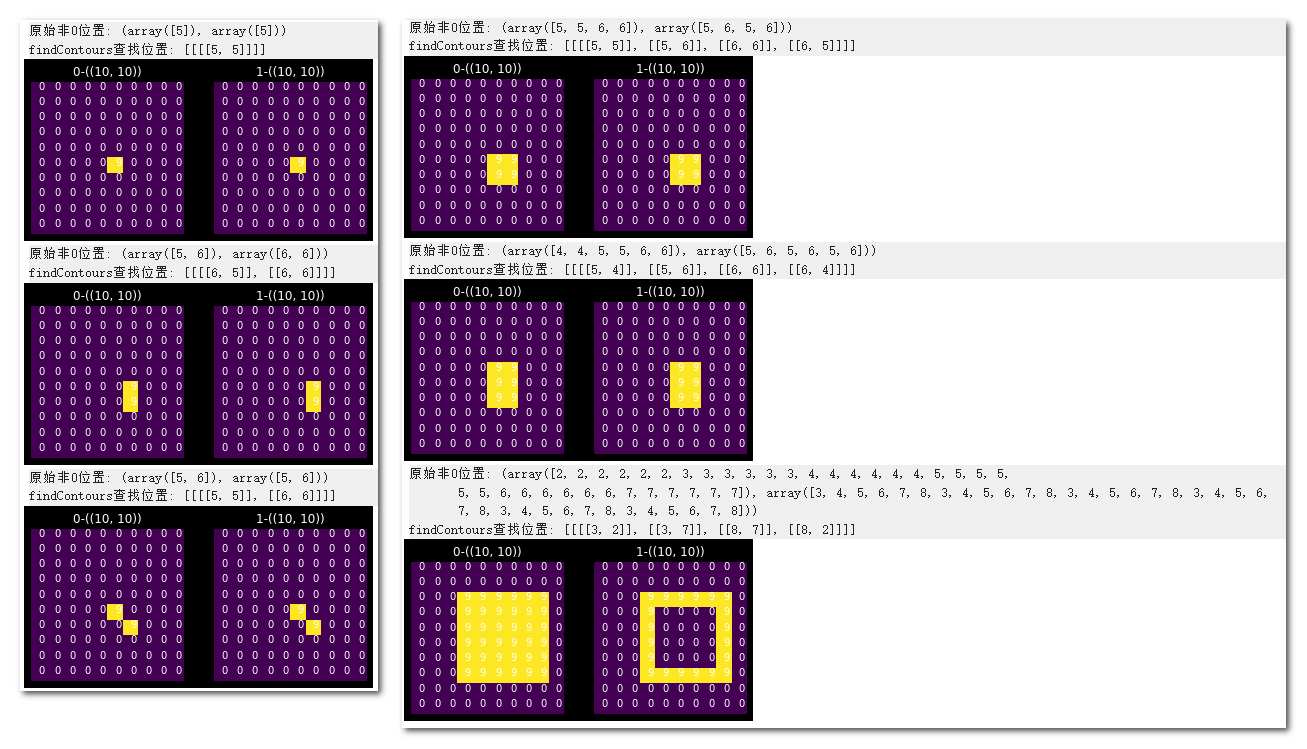
OpenCV 使用 findContours 对少数像素的查找边缘时,其返回值是多少?
![]()
- 对于像素本身就是边缘的来说,findContours 返回像素自身位置;否则返回边缘。图示是原图、经过边缘查找后画出的边缘
OpenCV 如何绘制轮廓?
![]()
- 函数 cv2. drawContours () 绘制轮廓。绘制轮廓并不是绘图显示,而是修改图像添加轮廓线
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18img = cv2.imread("../images/pattern1.png", flags=1)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 灰度图像
_, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_OTSU+cv2.THRESH_BINARY_INV)
# 寻找二值化图中的轮廓
binary, contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) # OpenCV3
# 绘制最内层轮廓, hierarchy[0][i][2]=-1 表示没有子轮廓,即为最内层轮廓
contourEx = img.copy() # OpenCV3.2 之前的早期版本,查找轮廓函数会修改原始图像
for i in range(len(contours)): # 绘制第 i 个轮廓
if hierarchy[0][i][2]==-1: # 最内层轮廓
x, y, w, h = cv2.boundingRect(contours[i]) # 外接矩形
text = "{}({},{})".format(i, x, y)
contourEx = cv2.drawContours(contourEx, contours, i, (205, 0, 0), thickness=-1) # 第 i 个轮廓,内部填充
contourEx = cv2.putText(contourEx, text, (x,y), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255))
print("i=", i, ",contours[i]:", contours[i].shape, ",hierarchy[0][i] =", hierarchy[0][i], "text=", text)
# 绘制全部轮廓,contourIdx=-1 绘制全部轮廓
contourTree = img.copy()
contourTree = cv2.drawContours(contourTree, contours, -1, (0, 0, 255), 2)
show_images([img,contourTree,contourTree])
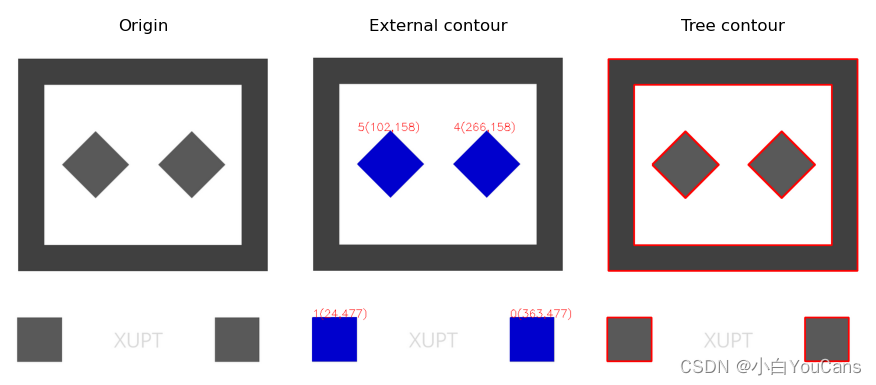
OpenCV 如何绘制轮廓的凸包?
1
2hull=cv2.convexHull(cnt)
k=cv2.isContourConvex(cnt)
OpenCV 如何绘制轮廓的边界矩形?
1
2
3#(x,y)为矩形左上角的坐标,(w,h)是矩形的宽和高
x,y,w,h=cv2.boundingRect(cnt)
img=cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
OpenCV 如何绘制轮廓的最小外接圆?
1
2
3
4(x,y),radius = cv2.minEnclosingCircle(cnt)
center = (int(x),int(y))
radius = int(radius)
img = cv2.circle(img,center,radius,(0,255,0),2)
OpenCV 如何绘制轮廓的拟合椭圆?
1
2ellipse = cv2.fitEllipse(cnt)
img = cv2.ellipse(img,ellipse,(0,255,0),2)
OpenCV 如何绘制轮廓的拟合直线?
1
2
3
4
5rows,cols = img.shape[:2]
[vx,vy,x,y]=cv2.fitLine(cnt,cv2.DIST_L2,0,0.01,0.01)
lefty=int((x*vy/vx)+y)
righty=int(((cols-x)*vy/vx)+y)
img = cv2.line(img,(cols-1,righty),(0,lefty),(0,255,0),2)
图片轮廓有哪些特征?
- 轮廓是一系列的座标点,其围绕的内部可以认定是一个区域,可计算其矩特征、重心、面积、周长
1
2
3
4
5
6
7
8
9
10#矩
M=cv2.moments(cnt)
#通过矩特征求重心
M=cv2.moments(cnt)
cx=int(M['m10']/M['m00'])
cy=int(M['m01']/M['m00'])
#面积
area=cv2.contourArea(cnt)
#周长
perimeter = cv2.arcLength(cnt,True)
什么是图像矩?
- 矩是统计学和概率论的一个概念,是均值、方差概念的扩展,图像的矩是用来描述图像形状特征的,以及形状的概率分布,被广泛用于图像检索和识别、图像匹配、图像重建、图像压缩以及运动图像序列分析等领域
- opencv 提供两种计算图像矩的方法,cv: : moment 计算包括几何矩 (10)、中心距 (7)、归一化几何矩 (7) 三类共计 24 个矩特征;cv: : HuMoments 计算的 7 个矩特征,这些特征具有旋转、平移和缩放不变性,可用于 cv: : matchShapes 进行形状匹配
1
2
3
4img = cv2.imread("../images/pattern1.png", flags=1)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 灰度图像
moments = cv2.moments(gray) # 几何矩 mpq, 中心矩 mupq 和归一化矩 nupq
huM = cv2.HuMoments(moments) # 计算 Hu 不变矩
如何定义图像的 “几何矩”?
![]()
- 图像几何矩的计算方式如下,其中 I (x, y) 是位置 (x, y) 处的像素

- x=0, y=0 称为零阶矩,如果是二进制图像,该矩特征表示面积,如果是灰度图,该矩特征表示灰度和
如何定义图像的 “中心距”?
![]()
- 中心矩与之前看到的几何矩非常相似,只是从和中减去了质心。图像中心距计算方式如

- 注意:中心矩是平移不变的。换句话说,无论斑点在图像中的哪个位置,如果形状相同,则力矩也将相同
如何定义图像的 “归一化中心矩”?
![]()
- 对中心矩进行归一化得到,已知中心矩是平移不变的,那么归一化中心矩既是平移不变的又是尺度不变

如何定义图像的 “Hu 矩”?
![]()
- 图像的 “Hu 矩” 和图像中心距的计算方式一
- 但是其矩特征进一步组合了图像中心距特征
![]()
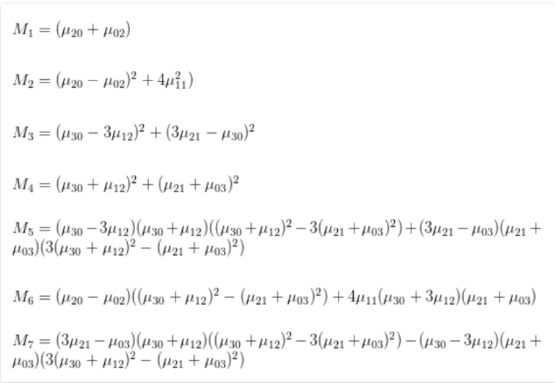
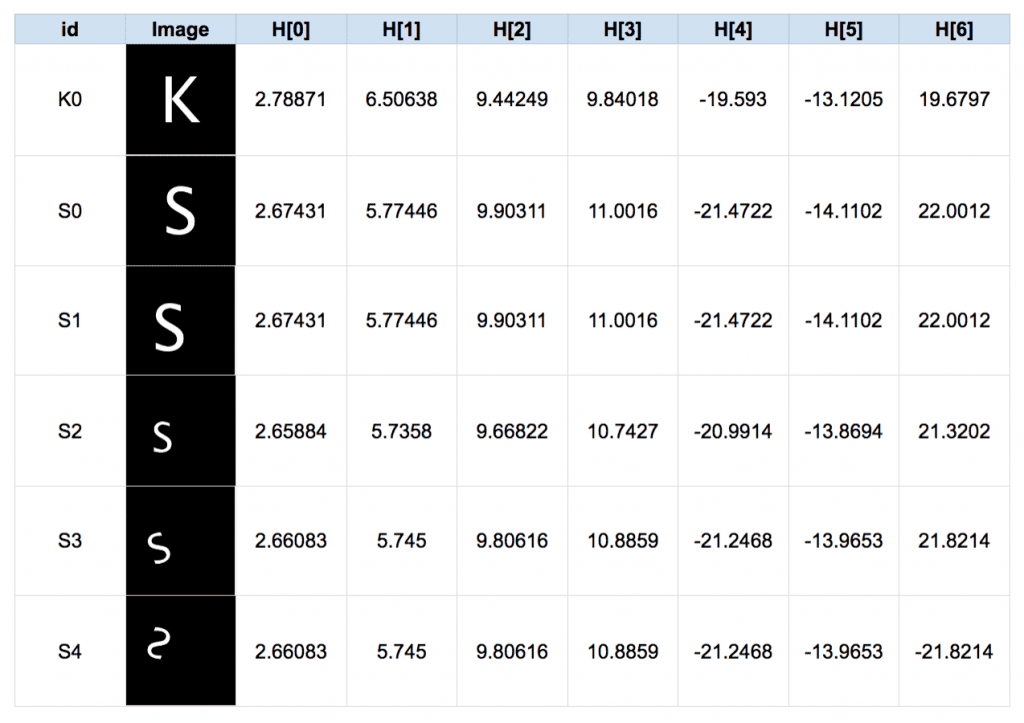
OpenCV 如何使用 Hu 矩进行轮廓匹配?
![]()
- 首先得到待原图和目标的二值化结果,然后提取目标图的所有轮廓,并计算所有轮廓的 Hu 矩,与原图 Hu 矩比较,得到匹配分数,在匹配分数阈值以上的轮廓认定是匹配结果
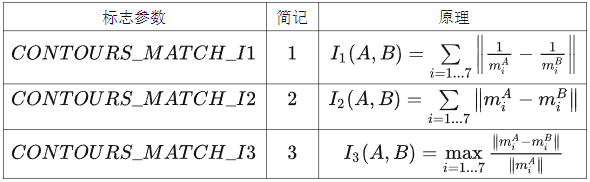
- Hu 矩是计算图像特征的方法,长度为 7,matchShapes 提供以下 3 种方式计算匹配分数
![]()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19image = cv2.imread ('src. jpg', 0)
template = cv2. imread ('template. jpg', 0)
_, thresh = cv2.threshold(image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
ret, thresh1 = cv2.threshold(template, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
contours, _ = cv2.findContours(thresh, 2, 1)
contours1, _ = cv2.findContours(thresh1, 2, 1)
cnt2 = contours1[0]
# 函数 cv2.matchShape() 可以帮我们比 两个形状或 廓的相似度。如果返回值越小, 匹配越好。它是根据 Hu 矩来计算的
min_pos = -1
min_value = 2
for i in range(len(contours)):
value = cv2.matchShapes(cnt2,contours[i],1,0.0)
if value < min_value:
min_value = value
min_pos = i
print(min_pos,min_value)
# 参数3为0表示绘制本条轮廓contours[min_pos]
image_match=image.copy()
cv2.drawContours(image_match,[contours[min_pos]],0,[255,0,0],3)

参考:
【youcans 的 OpenCV 例程 200 篇】168. 图像分割之区域生长_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】169. 图像分割之区域分离_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】170. 图像分割之 K 均值聚类_图像 k 均值聚类_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】171.SLIC 超像素区域分割_opencv slic_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】172.SLIC 超像素区域分割算法比较_opencv 网格化_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】173.SEEDS 超像素区域分割_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】174.LSC 超像素区域分割_cv2.ximgproc.supre pixel_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】175. 超像素区域分割方法比较_opencv 超像素分割_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】176. 图像分割之均值漂移算法 Mean Shift_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】177. 图像分割之 GraphCuts 图割法_opencv graphcut_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】178. 图像分割之 GrabCut 图割法(框选前景)_cv.grabcut_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】179. 图像分割之 GrabCut 图割法(掩模图像)_如果使用边界图像作为掩膜,可以实现分割_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】180. 基于距离变换的分水岭算法_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】181. 基于 Sobel 梯度的分水岭算法_基于梯度的分水岭分割_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】182. 基于形态学梯度的分水岭算法_基于形态学重建的分水岭算法公式_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】183. 基于轮廓标记的分水岭算法_基于标记的分水岭算法_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】184. 鼠标交互标记的分水岭算法_opencv 鼠标点击 分水岭分割_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】192.Gabor 滤波器组的形状_gabor lambda 取得越小_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】193. 基于 Gabor 滤波器的特征提取_cv2.getgaborkernel 纹理提取_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】195. 绘制图像轮廓(cv.drawContours)_opencv drawcontours_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】196. 图像的矩和不变矩(cv.moments)_cv2.moments_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】197. 轮廓的基本特征_轮廓特征_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】198. 基于不变矩的形状相似性检测_形状相似度_youcans_的博客 - CSDN 博客
【youcans 的 OpenCV 例程 200 篇】199. 轮廓的外接边界框_minenclosingtriangle_youcans_的博客 - CSDN 博客
【OpenCV 例程 300 篇】200. 轮廓的基本属性_opencv 求轮廓宽度的均值_youcans_的博客 - CSDN 博客