You Only Look Once:Unified Real-Time Object Detection
目标检测全新检测方式,相比较过去的二阶段检测方法,YOLO 系列系列将模型输出看作网格,图片的目标落在网格上,输出 “网格数量的” 预测实现对目标的检测
什么是 YOLOv1?
![YOLOv1-20230408141723]()
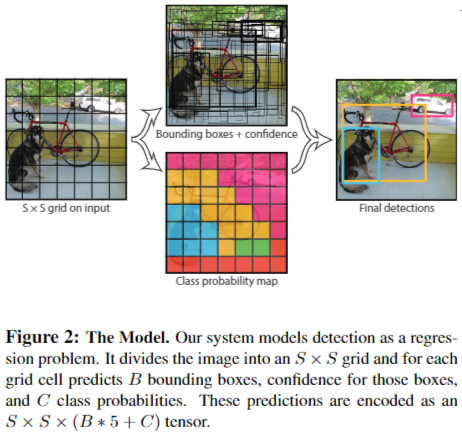
- 将输入图像分成 SxS 个格子,每个格子负责检测落入该格子的物体。图中物体马的中心点(红色原点)落入第 4 行、第 3 列的格子内,所以这个格子负责预测图像中的物体马
![]()

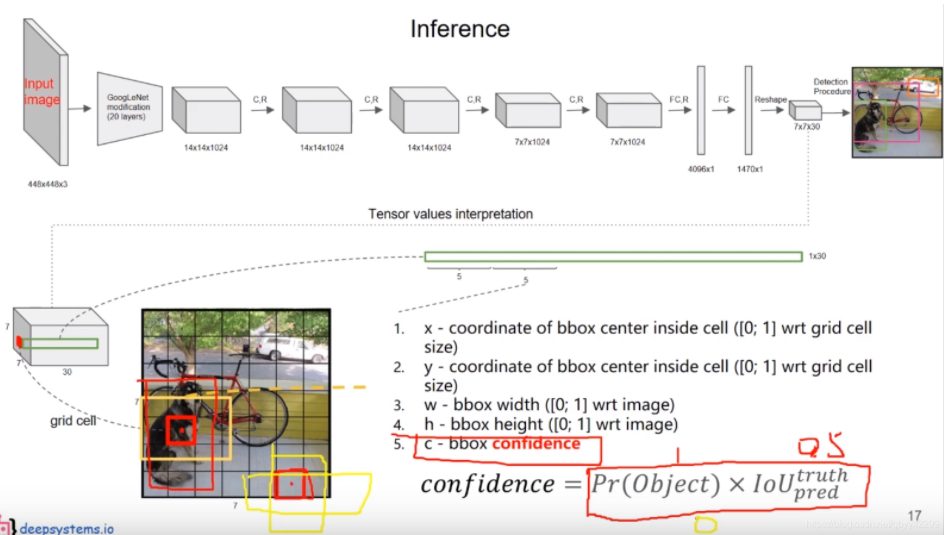
YOLOv1 的网络结构?
![]()
- YOLOv1 的 Backbone 借鉴了 GoogleNetv1 设计,共包含 24 个卷积层,2 个全连接层
- 输入: 448 x 448 x 3,由于存在全连接层,因此要求输入固定
- 输出: 最后一个 FC 层得到 1470 x 1 的输出,reshape 一下得到 7 x 7 x 30 的一个 tensor,即最终每个单元格都有一个 30 维的输出,表示每个单元格分为 20 类 + 2 个预测框,每个预测框包括 4 个位置信息及 1 个置信度。具体如何制作、学习这 30 维变量的学习样本,参考:YOLOv1 的正负样本判定、YOLOv1 正样本制作过程
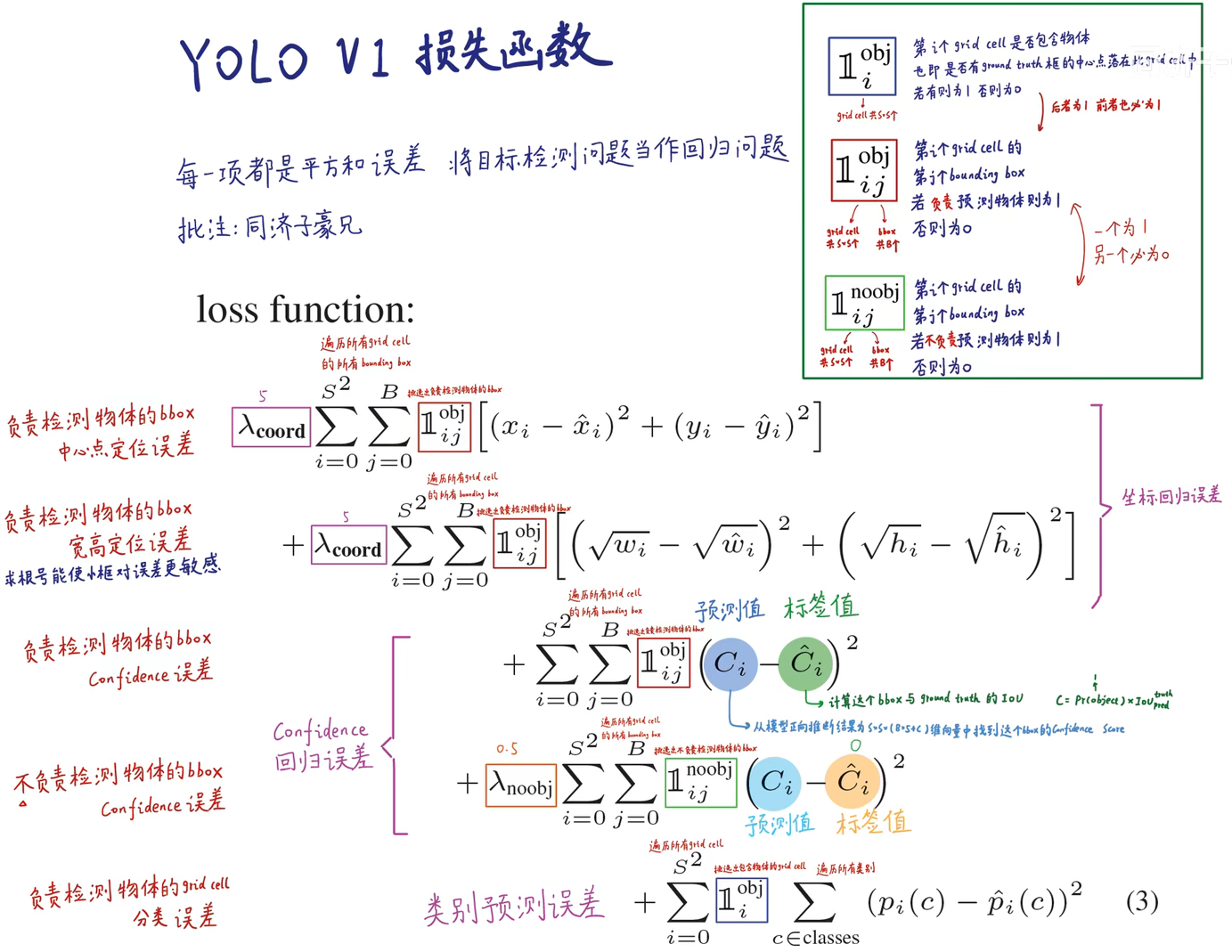
YOLOv1 如何计算损失?
![]()
- YOLOv1 的损失包含 3 部分,分别是座标回归误差、置信度回归误差、类别误差
- 注意:只有框真实置信度 = 1,才表示该框需要被学习位置信息和类别信息;框真实置信度 = 0(该框无预测目标),只计算框置信度损失
- 由此可知,有物体的地方,我们让网络去学习,逼近它,而没有物体的地方,理论上应该让 都是零
YOLOv1 的正负样本判定?
- YOLOv1 不存在锚框,因此通过预测框与真实框的 IOU 判定正负样本,动态变化
- 位置判定正负样本: 根据真实框对应 cell 位置,将预测框分为正负样本,每个真实框分配 1 个预测框
- 正样本: 取 cell 对应的预测框 IOU 最大的样本为正样本
- 负样本: cell 位置上除正样本外的预测框
YOLOv1 正样本制作过程?
YOLOv1 输出是 7x7x30,将图像的真实目标映射到所有网格的 30 维向量即完成样本制作
框置信度: 如果目标的中心落在网格内,则 c=1,否则 c=0
框的中心: 假设真实座标为
- (1) 计算中心
- (2) 计算映射到的网格
- (3) 计算量化误差,量化误差即是网络学习的目标,可知
- (1) 计算中心
框的宽高―
- (1) 计算框的宽、高
- (2) 归一化:图像的宽高通常是远大于 1 的实数,直接用这个做标签,loss 值和其他部分差距很大,因此将其进行归一化处理,最后
- 取对数:因为线性回归数是任意实数,而宽高始终大于 0,所以通过对数函数转换其范围
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25# 第一个目标使用13*13的那个框进行预测,并计算中心偏差、大小及权重
# 以下框的位置及大小的预测:位置使用(7,9)网格进行预测,预测参数为0.6049999999999995 0.4986666666666668 3.9269510260123828 4.9557894982104695
xmin, ymin, xmax, ymax = gt_label[:-1]
print(xmin, ymin, xmax, ymax) # 0.524 0.56 0.646 0.9013333333333333 经过缩放的框x,y,w,h
# 计算边界框的中心点
c_x = (xmax + xmin) / 2 * w
c_y = (ymax + ymin) / 2 * h
box_w = (xmax - xmin) * w
box_h = (ymax - ymin) * h
print(c_x,c_y,box_w,box_h) # 243.35999999999999 303.95733333333334 50.751999999999995 141.99466666666663 原始的框x,y,w,h
# 计算中心点所在的网格坐标
c_x_s = c_x / s
c_y_s = c_y / s
grid_x = int(c_x_s)
grid_y = int(c_y_s)
print(c_x_s,c_y_s,grid_x,grid_y) # 7.6049999999999995 9.498666666666667 7 9 确定模拟待拟合的中心,即原始的框映射到预测位置
# 计算中心点偏移量和宽高的标签
tx = c_x_s - grid_x
ty = c_y_s - grid_y
tw = np.log(box_w)
th = np.log(box_h)
print(tx,ty,tw,th) # 0.6049999999999995 0.4986666666666668 3.9269510260123828 4.9557894982104695 确定模型待拟合的参数,x,y的偏差,w,h的对数值
# 计算边界框位置参数的损失权重
weight = 2.0 - (box_w / w) * (box_h / h)
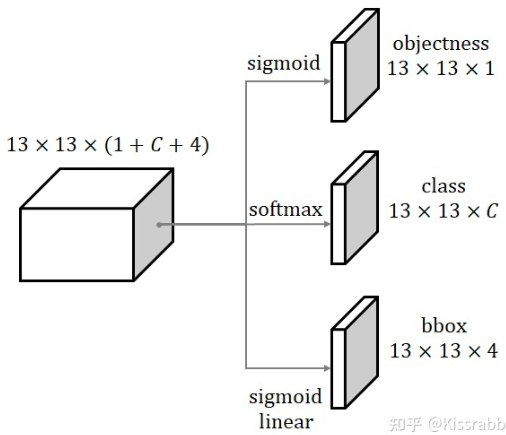
print(weight) # 1.9583573333333333YOLOv1 如何解析模型输出?
![]()
- 总体步骤:使用置信度阈值,过滤低置信度的预测,然后将剩下预测还原到原图上,并使用 nms 第二次过滤
- 框中心: 利用预测的框的位置 、下采样倍数 、量化误差 得到框的中心
- (1) 计算框的宽、高
定义回归中心参数为:
![]()
假设图中是同一目标在不同尺度下的预测效果,已知卷积神经网络具有尺度不变性 (size invariance) ,可以出现左图红框中心到绿框中心为 4,红框宽高为 (6,6),右图红框中心到绿框中心为 2,红框宽高为 (3,3),不使用除法时,左图平移变换距离为 4,右图为 2,神经网络输出需要优化 > 1 的数比较困难,因此将待优化值归一化处理 (待优化值 / 先验框中心位置),则左图和右图优化值均值 2/3
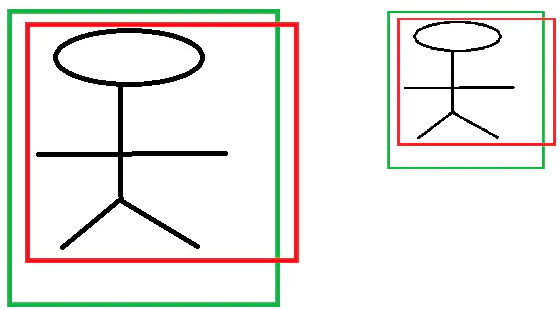
YOLOv1 边框回归中尺度变换 (回归尺寸),为什么是真实框与先验框比值取 log?
- 定义尺寸变换回归参数为:
![]()
- 神经网络输出的放缩的尺度 必须大于 0。怎么保证满足大于 0 呢?直观的想法就是 EXP 函数,也即
- 尺度变换的目地是为了 ,所以待学习参数计算公式为:
YOLOv1 预测有多个靠近的格点预测了同一物体,如何处理?
- yolov1 的格点设置已经确保一个格点只能预测 1 个类,但是由于中心点定位的偏差及相邻物体的原因,会出现多个格点预测了同一个物体的现象
- 可以借鉴 YOLOv2 将分类结果绑定到 bbox 上,现在是 1 个预测位置预测:2 个 bbox 及 1 个类别,改为预测 2 个 bbox 及 2 个类别
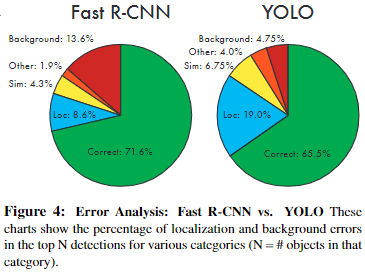
YOLOv1 与 Fast R-CNN 在预测结果上差异?
![YOLOv1-20230408141727-1]()
- YOLOv1 的 Localization 错误率更高,直接对位置进行回归,确实不如滑窗式的检测方式准确率高
- YOLOv1 对于背景的误检率更低,由于 Yolo 在推理时,可以 “看到” 整张图片,所以能够更好的区分背景与待测物体
YOLOv1 的预测框位置时,模型为什么不稳定?
- 模型不稳定,尤其是早期迭代时。大多不稳定来自预测框中心 。 是先验框的中心位置, 为先验框的宽高,计算如下
- 是要学习的参数,如果 时,,预测的位置右移一个锚箱宽度; 时,,预测的位置左移相同的宽度。该公式无约束, 因此预测边框的中心可能出现在任何位置,训练早期阶段不容易稳定。YOLOv2 调整了预测公式,将预测边框的中心约束在特定 gird 网格内,使得训练更稳定,参考:YOLOv2 论文中的直接位置预测 (Directlocationprediction)
YOLOv1 的缺点?
- 因为 YOLO 中每个 cell 只预测两个 bbox 和一个类别,这就限制了能预测重叠或邻近物体的数量 (论文至多 49 个目标),比如说两个物体的中心点都落在这个 cell 中,但是这个 cell 只能预测一个类别
- 不像 FasterRCNN 一样预测 offset,YOLO 是直接预测 bbox 的位置的,这就增加了训练的难度,参考:YOLOv1 的预测框位置时,模型为什么不稳定
- YOLO 是根据训练数据来预测 bbox 的,但是当测试数据中的物体出现了训练数据中的物体没有的长宽比时,YOLO 的泛化能力低
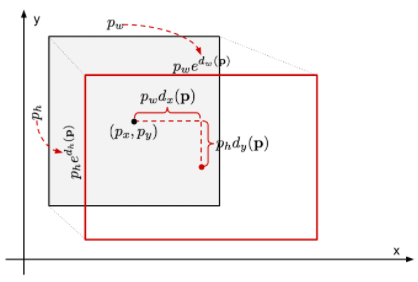
什么是边框回归 (Bounding Box Regression)?
![]()
- 使用 4 维向量 (x, y, w, h) 表示一个边框,图中的 P、G、T 分别表示 Proposal (获选框、先验框)、预测框、真实框,边框回归的目的: 寻找一种关系使得输入原始的窗口 P 经过映射得到一个 “跟真实框 T 更接近的” G,即给定 ,寻找映射关系 f,使得
- 主要包括 2 个过程,分别是平移及尺度变换。图中 P、G、T 这 3 个框表示为 ,边框回归的目的是基于先验框 及真实框 的信息,得到回归参数,使得先验框 经过回归参数计算后,得到的预测框 更接近真实框 T,回归参数共 4 个,分别是平移变换 2 个 ()+ 尺度变换 2 个 ()
- 平移变换:将先验框中心向真实框中心移动的过程,等式右边是框的更新过程,因为 是图像宽高,是个常量,所以不需要求导计算更新。实际模型推理时,输出 ,则其预测框中心 x 位置为
- 尺度变换:将先验框尺寸向真实框尺寸变换的过程
- 这里的 是回归过程需要学习的参数,这些参数可以根据先验框还原为预测框,并根据预测框与真实框的差距计算损失,得到损失使用随机梯度下降 (SGD) 等优化函数,更新
