我的目标检测学习路线
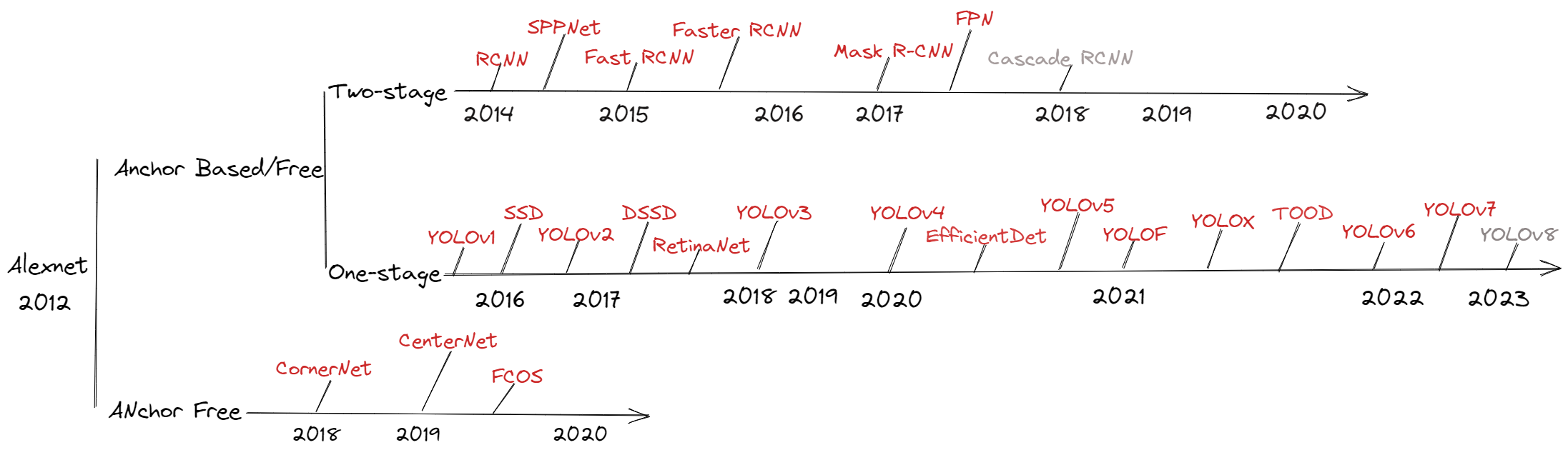
本文总结自己目前对 目标检测 的认识,和学习过程
什么是目标检测?
![]()
- 目标检测:精确的定位出图像中某一物体类别信息和所在位置
- 2014 年,基于候选区域 (two stage) 的目标检测算法代表算法 RCNN 发表,2015 年基于回归 (one stage) 的目标检测算法代表 YOLOv1 发表。前者往往准确度更高但速度上较慢,后者往往更快但准头略差一些,目前在向 one-satge、anchor-free 的方向发展
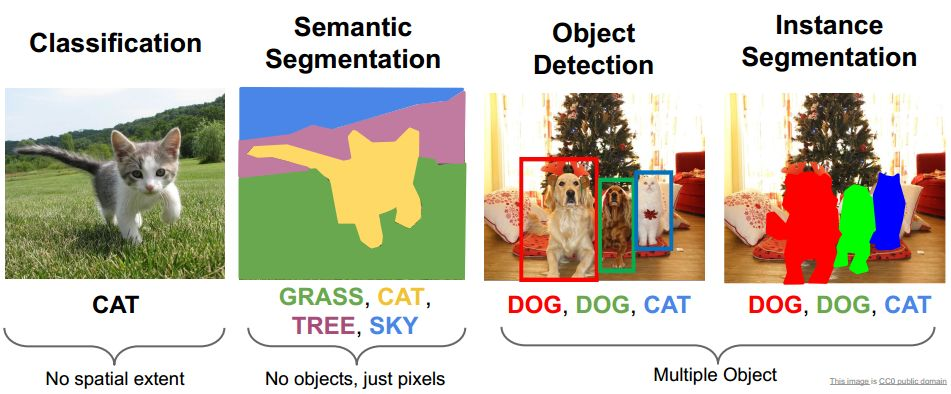
“目标检测” 的疑问
![Drawing 2023-03-14 20.55.52.excalidraw]()
- 以前不清楚目标检测的时候,老是对一个问题不明白:一张图片上目标数量不定,但神经网络的最后输出一定是定长的,那怎么预测一张图上的多个目标呢?
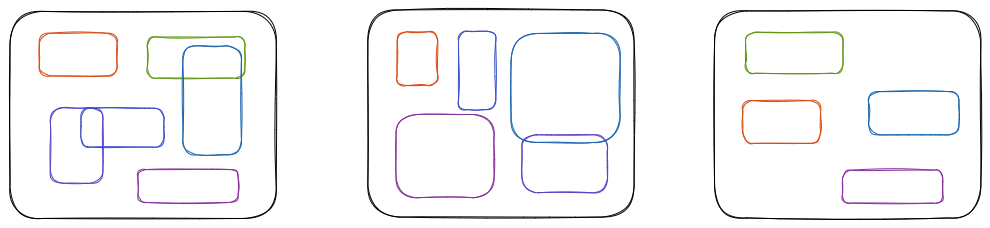
检测目标检测的 “朴素想法”
![Drawing 2023-03-16 21.34.10.excalidraw]()
- 就拿我们最熟悉的分类来说:已知分类模型的最后输出等于类别数量 (N),而且计算损失的时候也是输出 (N) 与 gt (N) 等长度的向量计算,也就是说每个输出都参与损失的计算 (假设是多标签分类)
- 但是目标检测情况有点不一样,即图片上的目标数量是未知的,有 2 种思路去解决模型输出的问题:RCNN 系列:先生成能覆盖住目标大量的获选框,然后将网络输出固定为框的分类及定位预;YOLO 系列:直接输入全图,然后模型设计大量的输出,然后选择某些输出去监督网络的学习,最后过滤所有输出,找到预测框
- 无论是先生成大量获选框、还是设计大量的输出,都是为了使用 “大数量” 的输出确保覆盖目标数量不定的图片
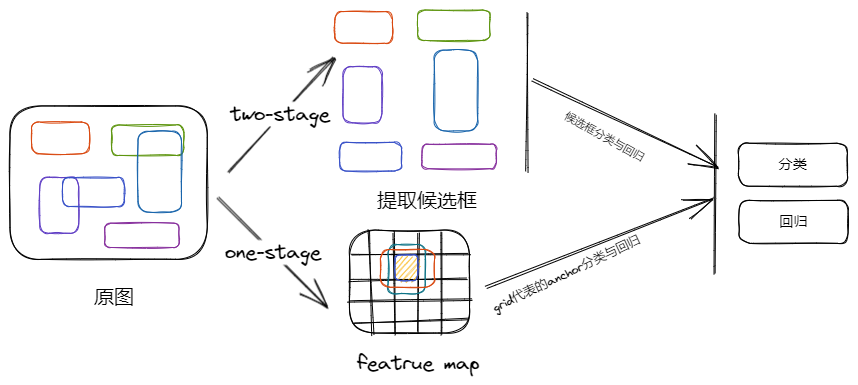
目标检测常用的方法?
![Drawing 2023-03-15 08.31.34.excalidraw]()
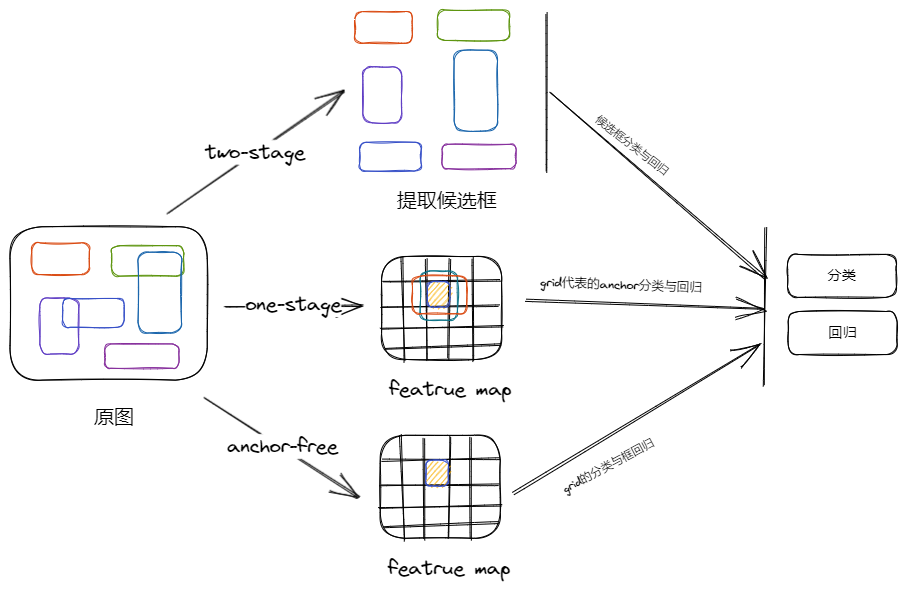
- two-stage:先找出目标的大量获选框,然后对获选框进行分类和回归,实现对目标的检测
- one-stage:从最后的 featrue map 开始,在 grid 设置多个 anchor,然后对这些 anchor 进行分类和位置检测,实现对目标的检测
- anchor-free:从最后的 featrue map 开始,直接用每个 grid 去学习目标的类别及 gt 框
目标检测的难点
- 图片数据少:训练样本在尺度、角度、光照、位置等维度不够丰富,所以常使用数据增强,包括 CutMix、MixUp、Mosic 等
- BackBone 提取特征能力弱:BackBone 提取特征能力,决定检测的上限,依次使用 VGGNet (YOLOv1)->DarkNet 19 (YOLOv2)->DarkNet 53 (YOLOv3)->CSPDarkNet 53 (YOLOv4/v5)->RepVGG(YOLOv6)->E-ELAN(YOLOv7)
- Neck 特征整合能力弱:Neck 的特征整合能力是后续 Head 的基础,依次经历 FPN->PAN
- Head 解藕目标能力弱:开始时使用单 head 检测,但是由于图片上混淆大目标、小目标,发现多 head 对其进行分而治之的方法更有效
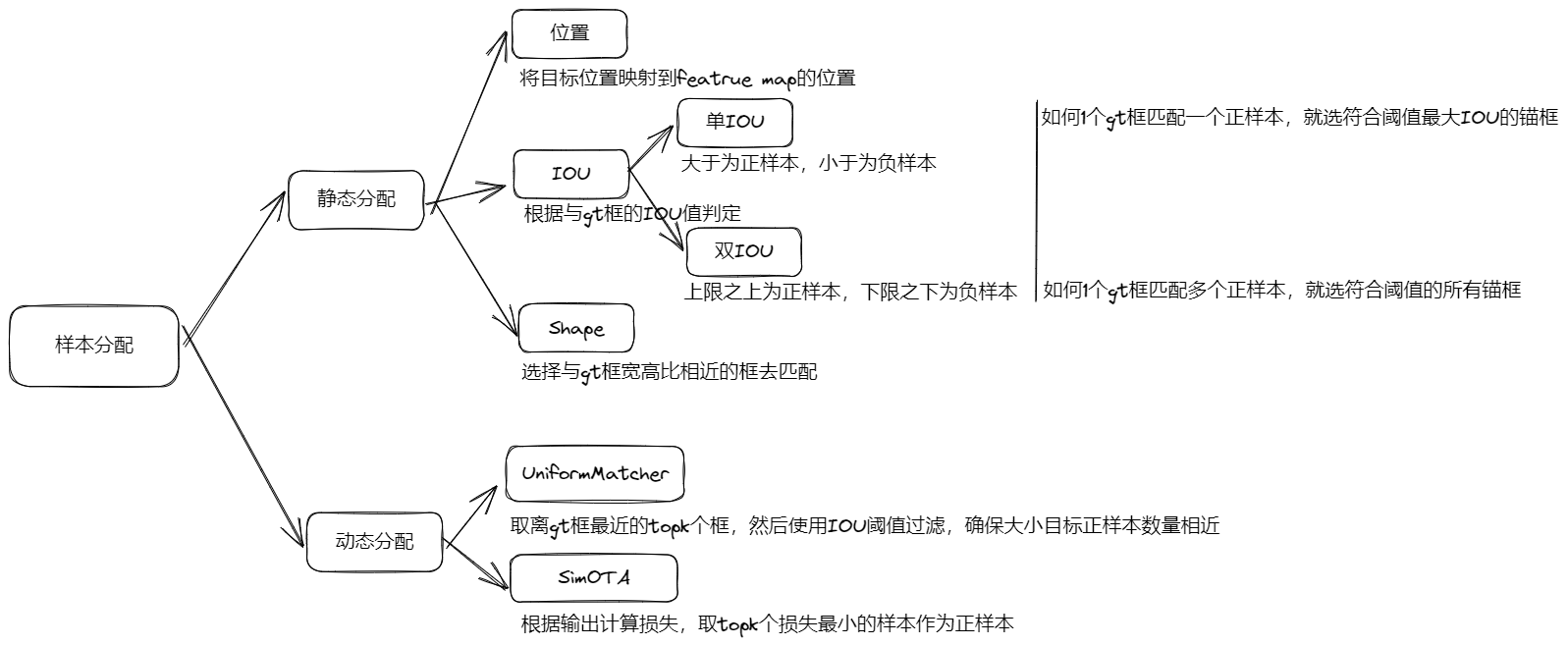
- 样本分配不准确:多 head + 多 anchor 的检测方式,导致模型有大量输出,如何将 gt 框准确分配到这些输出上,计算的损失能更有效监督网络学习,是比较难的问题。依次经历:静态分配 (位置、单 IOU 阈值、多 IOU 阈值、Shape)-> 动态分配(先计算损失再确定用那个检测器检测某个 gt),从正样本来说,依次经历单正样本、多正样本的过程
- 损失函数不够准确:损失函数主要有 3 个,置信度损失和类别损失通常使用 L1 loss、交叉熵损失、focal loss;预测框损失改进比较多,依次是:L 1 loss (YOLOv1、YOLOv2、YOLOv3)->IOU loss(YOLOX)->GIOU loss (YOLOv5)->DIOU loss (YOLOv4)->CIOU loss (YOLOv7)->SIOU loss (YOLOv6)
- 解析模型输出能力不强:目标检测模型大多都使用多 head 输出,如果还设置了 anchor,其输出的预测框远多于 gt 框,需要从这些预测框中解析出目标,依次经历 NMS->soft NMS->softer NMS
目标检测如何进行样本匹配?
![Drawing 2023-03-16 23.06.28.excalidraw]()
- 静态分配:按照位置、IOU、Shape 提前将 gt 框分配到某个检测器,所有的 anchor-base + 单头输出的 anchor-free,比如:YOLOv1-YOLOv5、SSD、RetinaNet、CornerNet、CenterNet、FOCS
- 动态分配:根据模型输出和 gt 框的损失,选择损失小的去监督网络,多 head 输出 anchor-free 均使用这种方式,比如 YOLOX、YOLOF、YOLOv6、YOLOv7
如何解析模型输出?
- Two-satge:由于提取了大量的候选框,不需要复杂的解码,模型输出就是预测结果,需要使用 NMS 进一步过滤结果
- One-stage:该系列模型往往预测了每个 grid 的置信度,从这个置信度开始解析结果。(1) 使用置信度阈值选定获选预测框;(2) 根据选择的置信度位置拿到对应的分类打分、位置预测;(3) 将置信度 x 分类打分作为分数,使用 IOU 阈值对所有选择出来的获选预测框进行 NMS
- anchor-free:该系列模型往往输出所有 grid 的 headmap,即对 grid 的分类打分,从这个打分开始解析模型输出。(1) 选择 heatmap 上 topK 高的打分;(2) 根据选择出来的位置确定目标的中心,然后拿出对应位置框其他属性 (宽高、中心到四边距离);(3) 以 heatmap 上的打分作为分数,,使用 IOU 阈值对所有选择出来的获选预测框进行 NMS
目标检测的评价指标?
![Drawing 2023-03-14 20.11.25.excalidraw]()
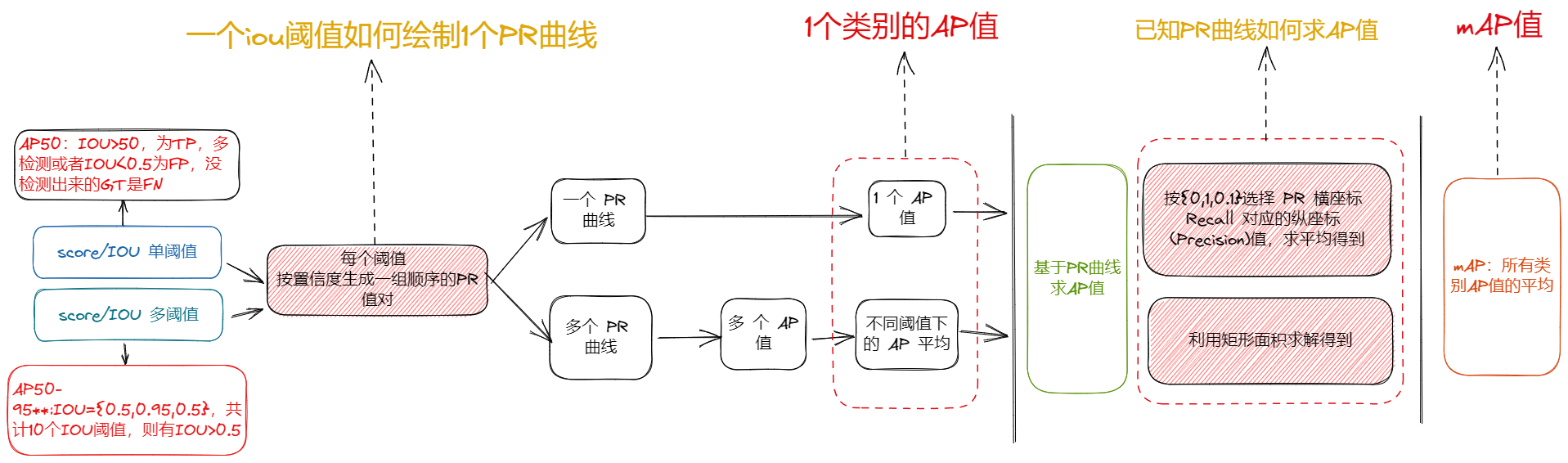
- 目标检测常使用 mAP 评价模型性能,注意:统计某类的 TP、FP、FN 时,是针对所有图片目标框预测结果进行,不针对具体图片
- mAP 是所有类别 AP 值的平均
- 每个 PR 区域是某个 IOU 阈值绘制的,并且这个 IOU 阈值已经由单阈值发展到多阈值
学习路线