FCOS:Fully Convolutional One-Stage Object Detection
通过预测目标中心到四边的距离实现对目标的检测
什么是 FCOS?
![FCOS-20230408141520]()
- 一般目标检测的边界框使用 (x, y, x, y) 或 (x, y, w, h) 之类的坐标表示,但 FCOS 是从一个点开始,然后使用该点与 groundtruth 之间的垂直和水平距离 (l, t, r, b) 来表示边界框的

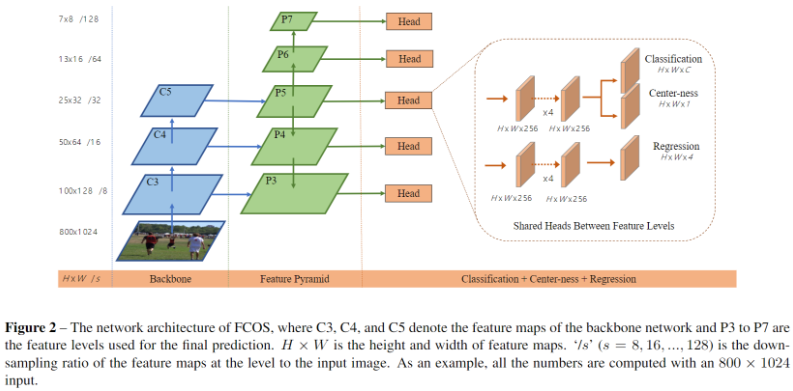
FCOS 的网络结构?
![FCOS-20230408141521]()
- 输入:(N,C,H,W)
- 输出:五个尺度的输出,分别是 P3、P4、P5、P6、P7,每个分支输出 3 类信息,分别是 featrue map 每个点的的分类、中心点损失、回归
- FCOS 使用 FPN 来进行多尺度特征学习,其得到的 head 用于预测不同尺度的目标
FCOS 的损失函数?
- 是分类损失, 是交并比损失
什么是 Center-ness loss?
![FCOS-20230408141523]()
- 为了解决 FCOS 在距离中心较远位置产生 “低质量” 的预测框,需要对其预测的 l、r、t、b 做一定的限制,即将上述公式添加到损失函数中,可以看根号下两项乘数均在 [0, 1] 之间,如果 l 越接近 r,t 越接近 b,其值越大,反之变小
- 测试时,将预测的中心度与相应的分类分数相乘,计算最终得分 (用于对检测到的边界框进行排序)。因此,中心度可以降低远离对象中心的边界框的权重。因此,这些低质量边界框很可能被最终的非最大抑制(NMS)过程滤除,从而显着提高了检测性能

FCOS 如何进行样本分配?
![FCOS-20230408141524]()
- 对于每个 level,如果某个 cell 落在 gt 上,则其负责预测该 gt,也就是说一个 gt 可以被多个检测 head 预测,但是这个过程需要考虑目标的尺寸,如果其尺寸大于特征图或者在特征图上是 1 个点,则该 level 不负责该目标的预测
- 如果某个 cell 被 2 个 gt 映射,选择小目标作为回归目标,可以极大减少模糊样本

FCOS 如何解码模型输出?
- 直接将所有预测信息解码到原图,在原图上进行 nms
- 首先根据分类分数 > 0.5 选择获选预测中心,然后根据其位置拿到 ness 值,分类分数 x ness 值就是这个预测中心置信度,根据中心位置,拿到对应的 l、r、t、b 预测,将中心 + l、r、t、b 还原到原图,最后根据预测框 + 置信度使用 nms 过滤