FPN:Feature Pyramid Networks for Object Detection
一种特征融合网络,能有效融合底层的特征和高层的语义信息,常用于目标检测。解决目标检测小尺寸物体检测问题
什么是特征金字塔网络 (Feature Pyramid Network,FPN)?
![FPN-20230408141534]()
- 一种特征融合网络,能有效融合底层的特征和高层的语义信息,常用于目标检测。解决目标检测小尺寸物体检测问题
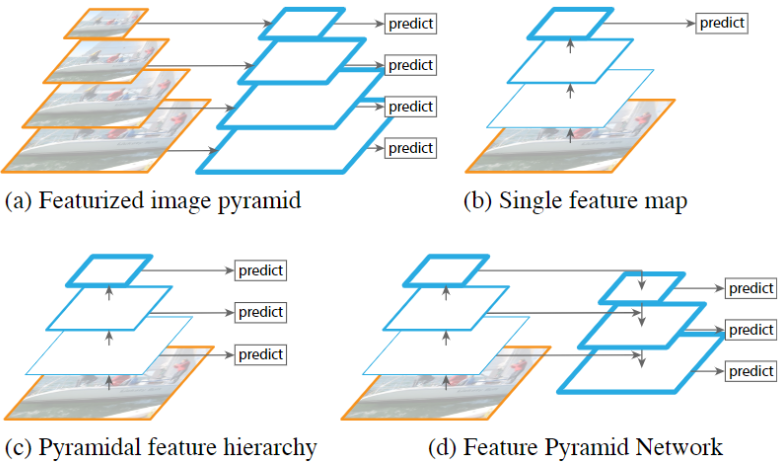
- (a)多尺度训练多尺度预测:先把图片弄成不同尺寸的,然后再对每种尺寸的图片提取不同尺度的特征,再对每个尺度的特征都进行单独的预测,优点是不同尺度的特征都可以包含很丰富的语义信息,但是缺点就是时间成本太高
- (b)最后一层预测:SPPnet,Fast R-CNN,Faster R-CNN 中使用的,就是在网络的最后一层的特征图上进行预测。优点是计算速度会比较快,但是缺点就是最后一层的特征图分辨率低,不能准确的包含物体的位置信息
- (c)多尺度预测:在不同尺寸的特征图上都进行预测,如 SSD 高层语义信息接触不了底层位置信息,特征融合不够彻底
- (d)多尺度融合最高层预测:FPN 的做法,引入了高层特征向低层融合的路径,并在多个尺度进行预测
特征金字塔网络 FPN 的组成?
![FPN-20230408141534-1]()
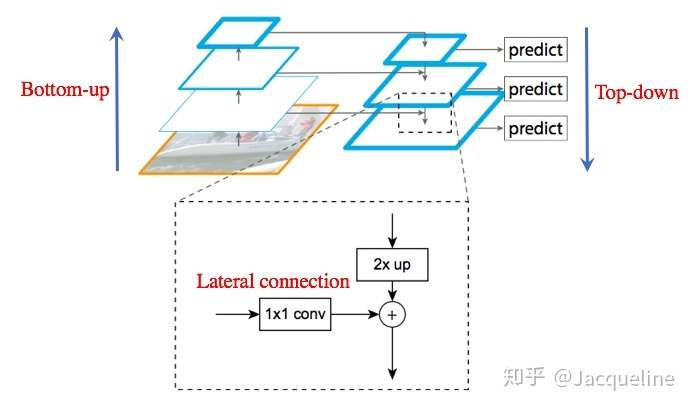
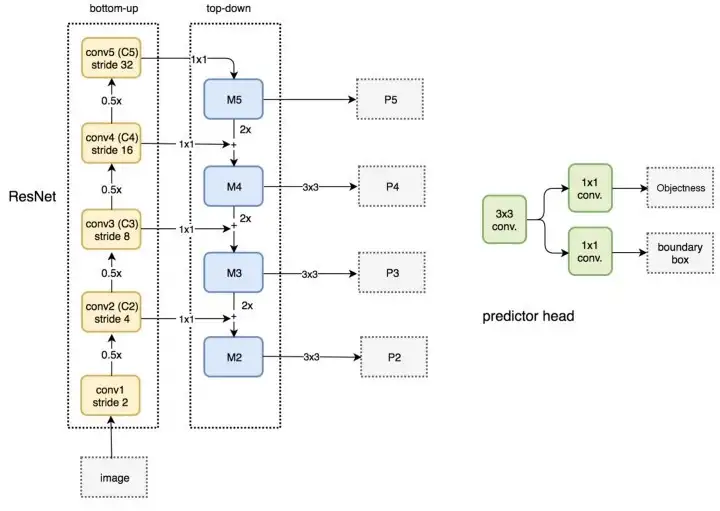
- Bottom-up:将图片输入到 backbone ConvNet 中提取特征的过程中。Backbone 输出的 feature map 的尺寸有的是不变的,有的是成 2 倍的减小的。以 ResNet 为例,将卷积块 conv2, conv3, conv4, conv5 的输出定义为 {C2 , C3, C4, C5} ,这些都是每个 stage 中最后一个残差块的输出,这些输出分别是原图的 { 1/4, 1/8, 1/16, 1/32 } 倍
- Top-Down:将高层得到的 feature map 进行上采样然后往下传递,这样做是因为高层的特征包含丰富的语义信息,经过 top-down 的传播就能使得这些语义信息传播到低层特征上,使得低层特征也包含丰富的语义信息。本文采样方法是最近邻上采样
- Lateral connection:Bottom-up 的某个 stage 使用 1x1 卷积降低通道数,然后和 Top-Down 的某个 stage 的 2xup 特征融合,融合的目的为了消除上采样产生的混叠效应,混叠效应应该就是指上边提到的‘插值生成的图像灰度不连续,在灰度变化的地方可能出现明显的锯齿状
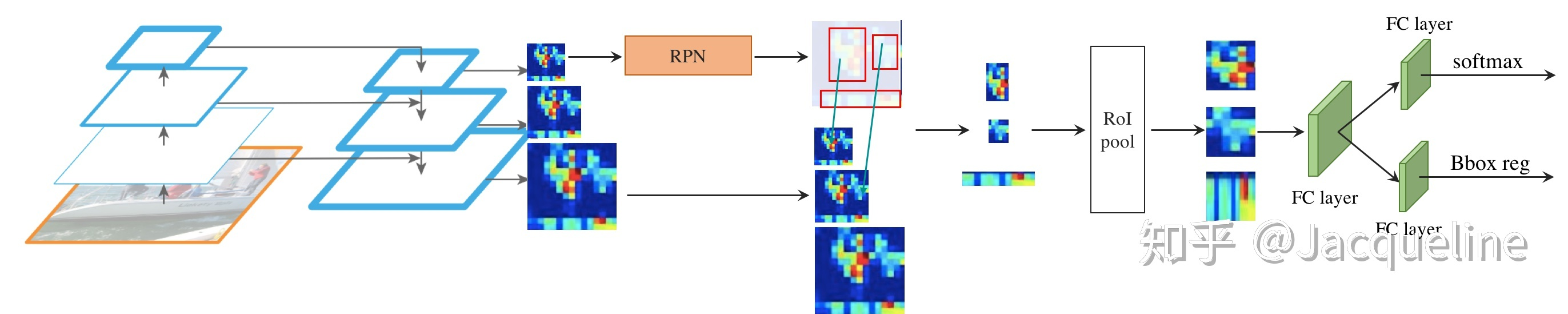
特征金字塔网络 FPN 应用于 RPN?
- 将 FPN 和 RPN 结合起来,那 RPN 的输入就会变成多尺度的 feature map,那我们就需要在金字塔的每一层后边都接一个 RPN head (一个 3x3 卷积,两个 1x1 卷积)
![FPN-20230408141536]()
- 在生成 anchor 的时候,因为输入是多尺度特征,就不需要再对每层都使用 3 种不同尺度的 anchor 了,所以只为每层设定一种尺寸的 anchor,图中绿色的数字就代表每层 anchor 的 size,但是每种尺寸还是会对应 3 种宽高比。所以总共会有 15 种 anchors。此外,anchor 的 ground truth label 和 Faster R-CNN 中的定义相同,即如果某个 anchor 和 ground-truth box 有最大的 IoU,或者 IoU 大于 0.7,那这个 anchor 就是正样本,如果 IoU 小于 0.3,那就是负样本
特征金字塔网络 FPN 应用于 Fast RCNN?
- 在 Fast R-CNN 中有一个 ROI Pooling 层,它是使用 region proposal 的结果和特征图作为输入,得到的每个 proposal 对应的特征然后 pooling,之后再分别用于分类结果和边框回归。之前 Fast R-CNN 使用的是单尺度的特征图,但是现在使用不同尺度的特征图,那么 RoI 需要在哪一个尺度的特征图上提取对应的特征呢?
- 假设 FPN 产生了特征金字 [P2, P3, P4, P5, P6],通过下列公式决定宽 w 和高 h 的 ROI 到底要从哪个 Pk 来切
- 其中 224 表示预训练 ImageNet 图片大小,k0 表示面积为 wxh=224x224 的 ROI 所在层级,论文将 k0 设置为 p4,如果 ROI 小于 224,比如说 122x122,则使用 k0-1=4-1=3 层特征池化
- 这种做法很合理,大尺度的 ROI 要从低分辨率的 feature map 上切,有利于检测大目标,小尺度的 ROI 要从高分辨率的 feature map 上切,有利于检测小目标
特征金字塔网络 FPN 应用于 Faster RCNN?
![FPN-20230408141537]()
- 和普通的 Faster R-CNN 相同,为每个 RoI 提取特征之后,需要经过 RoI pooling 层将 RoI 的特征 resize 成相同大小的,这里是 resize 成 7x7 的,之后再连接两个 1024-d 的 FC layer,然后再并行的输入到两个 FC layer 中分别进行分类和回归,便得到最终的结果
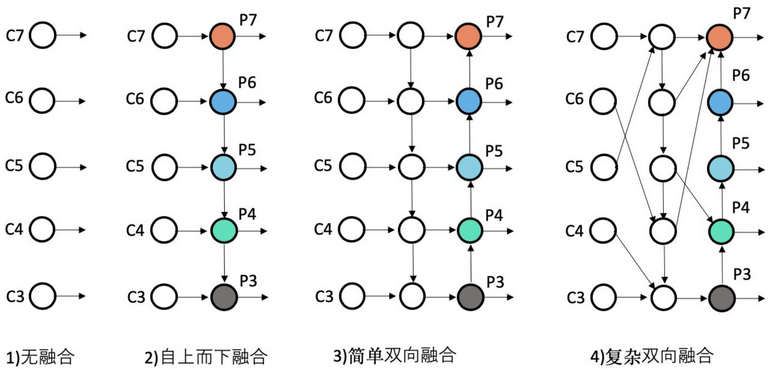
FPN 系列的演进方向?
![]()
- 1)无融合: 直接利用不同 stage 的特征图分别负责不同 scale 大小物体的检测 SSD 使用该思想
- 2)自上而下: 自上而下单向融合特征金字塔 (Feature Pyramid Network,FPN),事实上仍然是当前物体检测模型的主流融合模式。如我们常见 Faster RCNNMask RCNNYOLOv3、RetinaNet、Cascade RCNN 等
- 3)简单双向: PAN 是第一个提出从下向上二次融合的模型
- 4)复杂双向: EfficientDet 是 google 出品,在 FPN 中寻找一个有效的 block,然后重复叠加,这样就可以弹性的控制 FPN 的大小
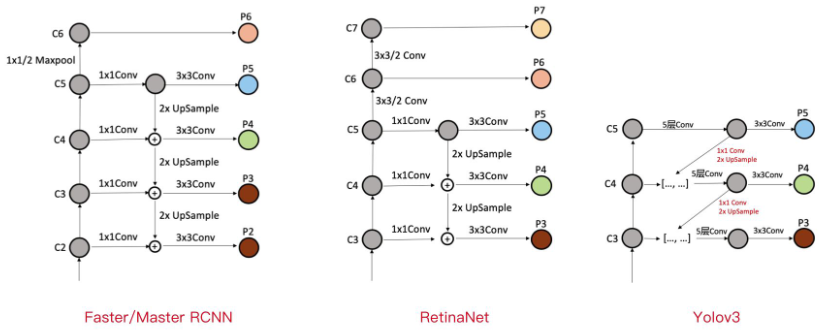
Faster RCNN、Mask RCNN、YOLOv3、RetinaNet、Cascade RCNN 使用 FPN 的区别?
![]()
- 1)Faster/Mask/CascadeRCNN: 利用了 C2-C6 五个 stage 的特征,其中 C6 是从 C5 直接施加 1x1/2 的 MaxPooling 操作得到。FPN 融合后得到 P2-P6,其中 P6 直接等于 C6,P5 是先经过 1x1Conv,再经过 3x3Conv 得到,P2-P4 均是先经过 1x1Conv,再融合上一层 2xUpsample 的特征,再经过 3x3Conv 得到 -
- 2)RetinaNet: 基本与 Faster/Master/CascadeRCNN 中的 FPN 一脉相承。只是利用的 stage 的特征略有差别,Faster/Master/CascadeRCNN 利用了高分辨率低语义的 C2,RetinaNet 利用了更低分辨率更高语义的 C7。其他都是细微的差别
- 3)YOLOv3: FPN 与上述两个有比较大的区别。首先,YOLOv3 中的 FPN 只利用到了 C3-C5 三个 stage 的特征;其次,从 C5 征到 P5 特征,会先经过 5 层 Conv,然后再经过一层 3x3Conv;最后,C3-C4 到 P3-P4 特征,上一层特征会先经过 1x1Conv+2xUpsample,然后先与本层特征 concatenate,再经过 5 层 Conv,之后经过一层 3x3Conv