HAN
使用两级的 seq 2 seq,实现对文档的分类
什么是 HAN ?
![]()
- 一个使用两级 Seq 2 Seq 结构的文档分类器,第一级结构首先编码句子信息,第二层结构编码文档信息,并最后输出文档类别。在编码信息的过程中,分别使用词注意力、句子注意力
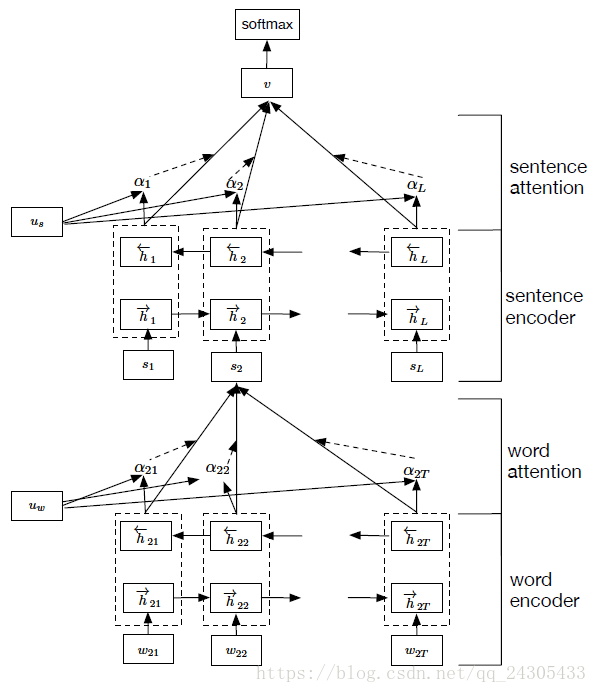
HAN 的网络结构?
![]()
- 网络结构分为两级,第一级的输出是所有词语的隐状态,组成了对句子的表示过程,第二级是所有句子的隐状态,并取最后一个句子的隐状态做分类处理
HAN 的注意力分析?
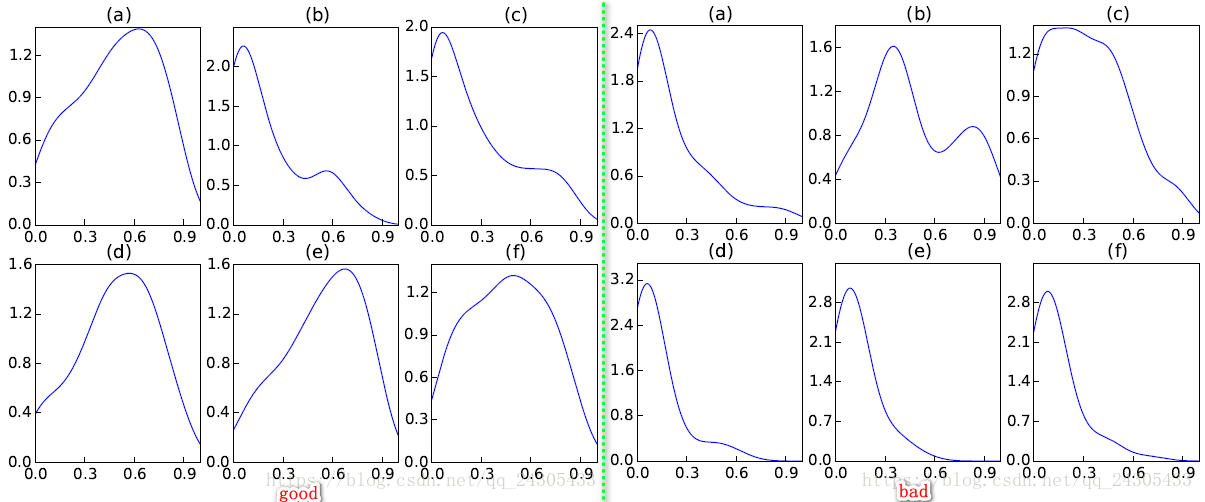
![]()
- 分别分析了模型对于单词 “good” 及 “bad” 的分配情况。左图是对于单词 “good” 的权重分布情况,其中(a)是总体的分布情况,(b)-(f)分别是在由差评逐渐到好评的过度的过程中 “good” 的权重的变化情况。从图中可以看出,随着好评程度的不断上升,“good” 所获得的权重越大,这说明,网络能够自动的将 “注意力” 放在和好评更相关的词汇上。右图对单词 "bad" 做了同样的分析,可发现网络会在差评的时候更加将 “注意力” 放在 “bad” 词汇上
HAN 的注意力可视化?
![]()
- 其中蓝色的程度越深,说明该单词所获得的权重越大,粉色程度越深,说明该句子所获得的权重越大。从图中分析可以看出,像 “delicious”、“terrible”、“amazing” 这样的形容词会获得较大的权重,而其对应的句子也会获得较大的权重。因此该模型确实能够捕获到有助于对文本进行分类的词汇

参考: