CenterNet:Keypoint Triplets for Object Detection
将目标检测当成一个点来检测,即用目标 box 的中心点来表示这个目标,预测目标的中心点偏移量 (offset),宽高 (size) 来得到物体实际 box
什么是 CenterNet?
![CenterNet-20230408141319]()
- 将目标检测当成一个点来检测,即用目标 box 的中心点来表示这个目标,预测目标的中心点偏移量 (offset),宽高 (size) 来得到物体实际 box

CenterNet 的网络结构?
![CenterNet-20230408141320]()
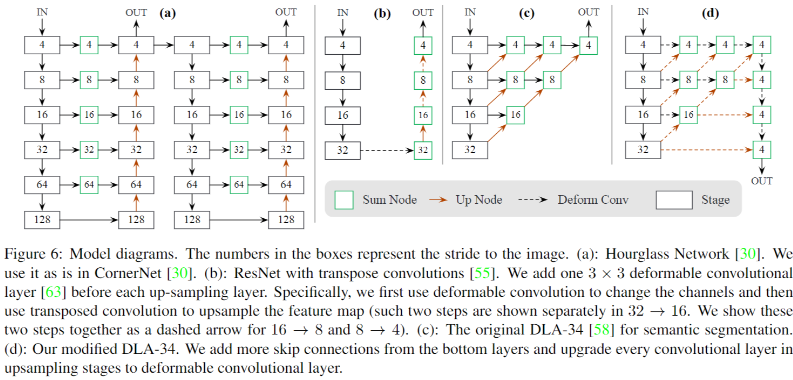
- backbone 和 neck 部分主要使用 DLA-34 结构 (图 d) 搭建,该模块使用大量的反卷积提升深层网络的分辨率,然后和底层的特征融合,这个过程类似 FPN、PAN;head 部分:使用直接基于 DLA-34 输出的 P4 特征做中心点及宽高的回归
- 输入:2,3,512,512
- 输出:
- 热图 + 类别 + 中心点 (2, 20, 128, 128)
- 中心点对应宽高 (2, 2, 128, 128)
- 中心点偏差 (2, 2, 128, 128)
CenterNet 的损失函数?
- 类别损失:使用 focal loss 损失计算
- 中心点损失:L1 loss 计算, Qp 表示预测的偏移值,p 为图片中目标中心点坐标,R 为缩放尺度,p 为缩放后中心点的近似整数坐标
- 宽高损失:目标框的尺度使用 L1 loss 计算, Spk 为预测尺寸,Sk 为真实尺寸
- 总损失:
CenterNet 如何制作样本?
- 输入图片 (N, 3, 512, 512)
- 输出:
- heatmap,并按类别区分 (N, 128, 128, 20)
- W/H (N, 128, 128, 2)
- offset (N, 128, 128, 2)
- positiveInd (N, 128, 128) 记录正样本位置,用于监督框位置
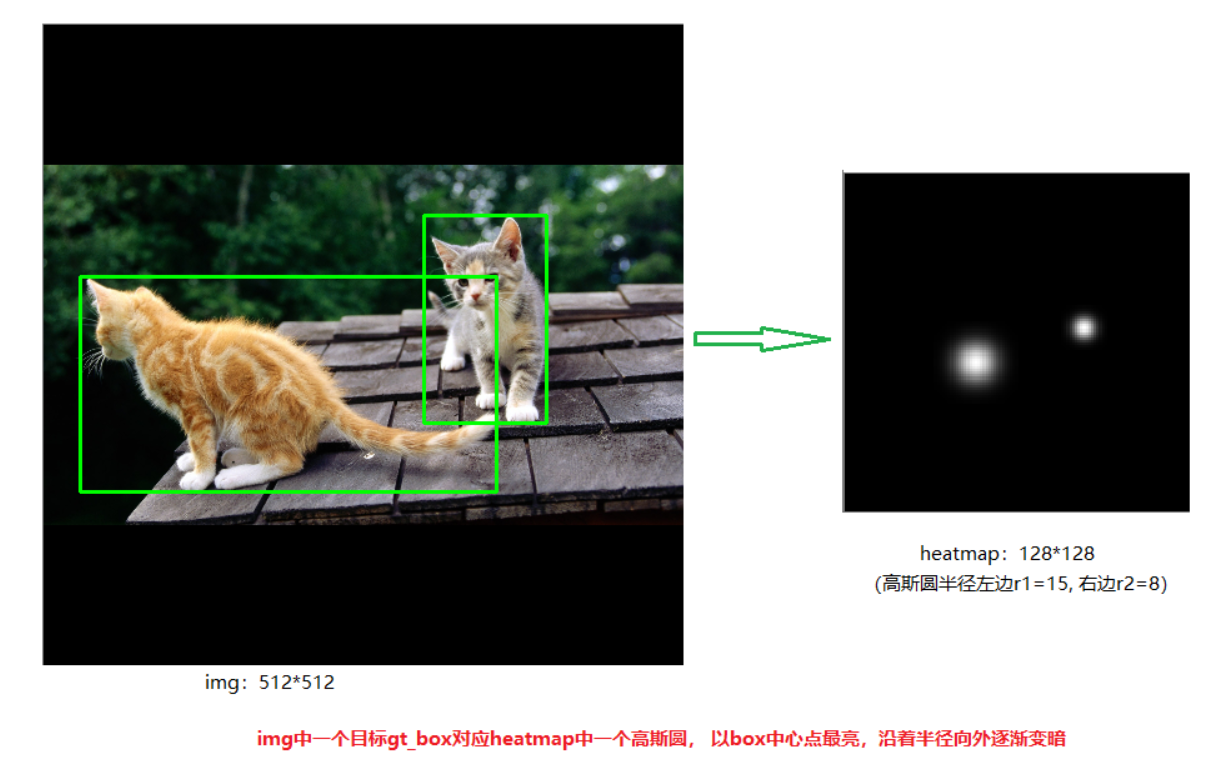
CenterNet 的 heatmap 如何生成?
![]()
- 在目标检测中,中心点附近的点其实都非常相似,如果直接将这些点标为负样本,会给网络的训练带来困扰;如果将其用高斯函数做一个 “软化”,网络就会更好收敛。高斯图能够给网络训练增加一个方向性的引导,距离目标点越近,权重就越大
- 将目标缩放到模型输出的尺度上,目标中心点及大小按照同等比例缩放,然后根据目标的大小计算高斯圆的半径
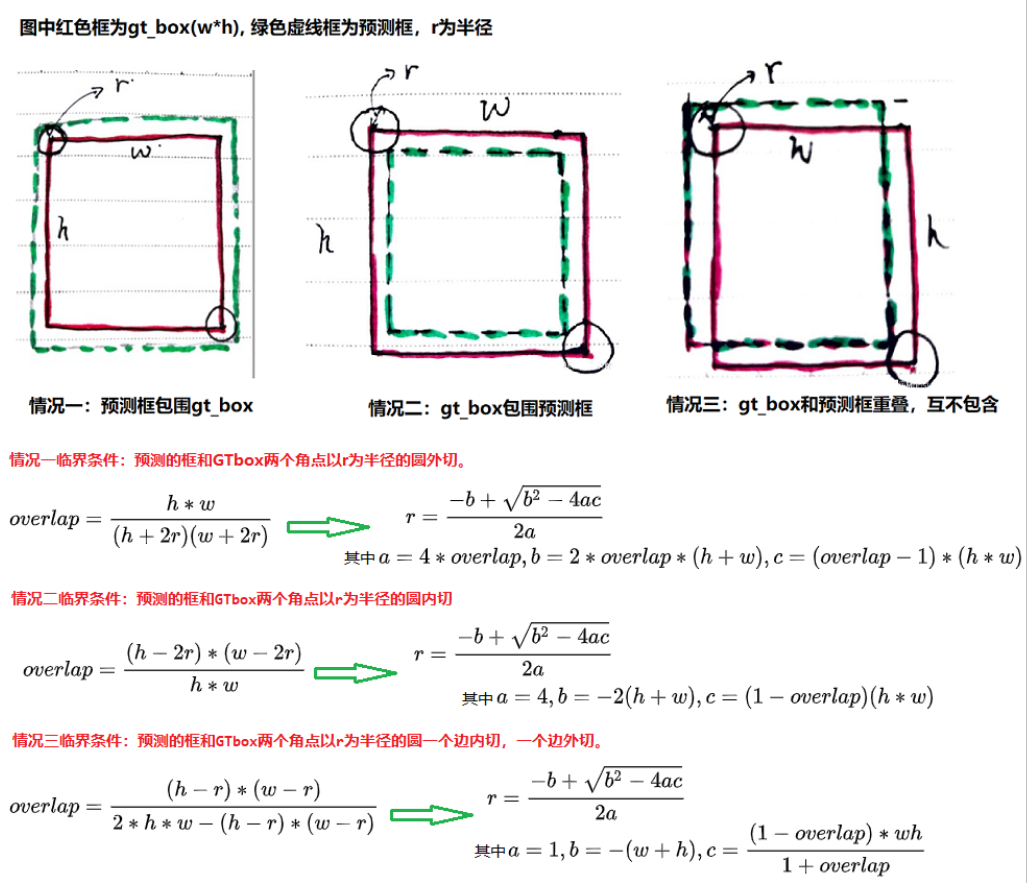
- 关于高斯圆半径确定,主要还是依赖于目标 box 的宽高,实际情况下通常会取 IOU=0.7,即下图中的 overlap=0.7 作为临界值,然后分别计算出三种情况的半径,取最小值作为高斯核的半径 R
![]()
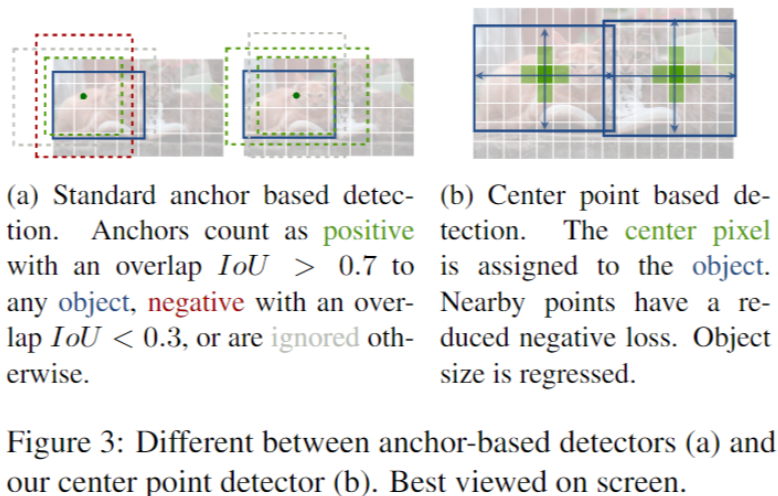
anchor-base 和 Center-Point 的目标检测的区别?
![CenterNet-20230408141328]()
- Center Point 的锚点仅仅是放在位置上,没有尺寸框。没有手动设置的阈值做前后景分类
- Center Point 的每个目标仅仅有一个正的锚点,因此不会用到 NMS,我们提取关键点特征图上局部峰值点
- CenterNet 相比较传统目标检测而言(缩放 16 倍尺度),使用更大分辨率的输出特征图(缩放了 4 倍),因此无需用到多重特征图锚点
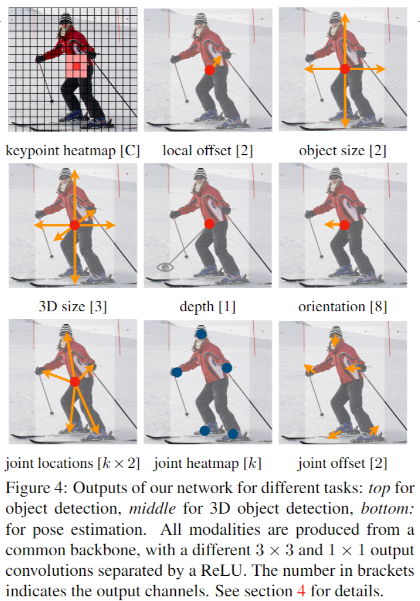
基于 Center Point 的目标检测可延申到哪些领域?
![CenterNet-20230408141331]()
- 3D BBox 检测,我们直接回归得到目标的深度信息,3D 框的尺寸,目标朝向
- 人姿态估计,我们将关节点(2D joint)位置作为中心点的偏移量,直接在中心点位置回归出这些偏移量的值
CenterNet 与 CornerNet 的区别?
- CenterNet 预测的是目标的中心点,而不再是 CornerNet 中的 2 个角点
- 相同点:采用热力图(heatmap)来实现初始位置预测,都引入了预测点的高斯分布区域计算真实预测值,同时损失函数一样(修改版 focal loss),网络输出的热力图也将先经过 sigmod 函数归一化成 0 到 1 后再传给损失函数
- 不同点:(1)CenterNet 不包含 corner pooling 等操作,因为一般目标框的中心点落在目标上的概率还是比较大的,因此常规的池化操作能够提取到有效的特征;(2)CenterNet 不需要匹配关键点
CenterNet 如何处理 “中心” 重合的情况?
- CenterNet 中的冲突是目标框的中心点重合(基于输出特征层计算的中心点),作者从 COCO 数据集的统计信息来看,这种重合框的比例非常少,不到 0.1%,基本上不会对训练稳定产生太大影响,因此没有针对这个进行解决
如何解析 CenterNet 的输出?
- 下图展示网络模型预测出来的中心点、中心点偏置以及该点对应目标的长宽
![CenterNet-20230408141333]()
- 输入: 假设测试输入是一张图像,将图像尺寸处理成 512x512 大小
- 输出: 执行网络的前向计算将得到 3 个输出。heatmap(1, 80, 128, 128)、宽高 wh (1, 2, 128, 128)、offset (1, 2, 128, 128),heatmap 会经过一个 sigmoid 函数使得范围为 0 到 1
- 极大值抑制: 对 heatmap 进行 3x3 的池化 (pad=1),输出保持分辨率不变,将池化后的结果与 heatmap 比较,值改变的位置就是非极大位置,将这些位置的置信度置 0,那么后续这些位置不可能作为角点,这起到非极大值抑制的作用
- 生成预测框: 然后再基于 heatmap 选择 top K 个得分最高的点(默认 K=100),这样就确定了 100 个置信度最高的预测框的中心点位置了。结合 heatmap 的 topk 位置 + 输出的宽高 wh 和 offset ,得到特征图上目标框,将其还原到原图即可

参考文献
CenterNet 算法详解_技术挖掘者的博客 - CSDN 博客_centernet 算法
扔掉 anchor!真正的 CenterNet——Objects as Points 论文解读 - Oldpan 的个人博客