CornerNet:Detecting Objects as Paired Keypoints
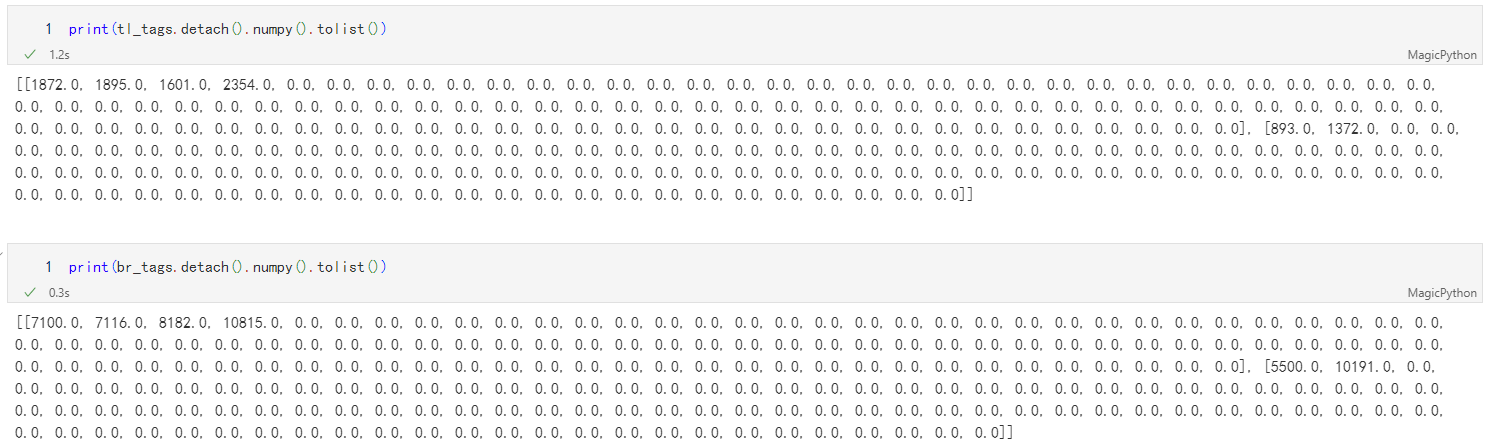
通过预测图片目标的左上角(top-left corner)点、右下角 (bottom-right corner) 点坐标实现对物体的检测
什么是 CornerNet?
![CornerNet-20230408152622-1]()
- 通过预测图片目标的左上角(top-left corner)点、右下角 (bottom-right corner) 点坐标实现对物体的检测
- 为每个预测点分配一个 embedding vector,同一个目标的 vector 的距离较小,不同物体的 vector 的距离较大,以便实现左上角与右下角配对
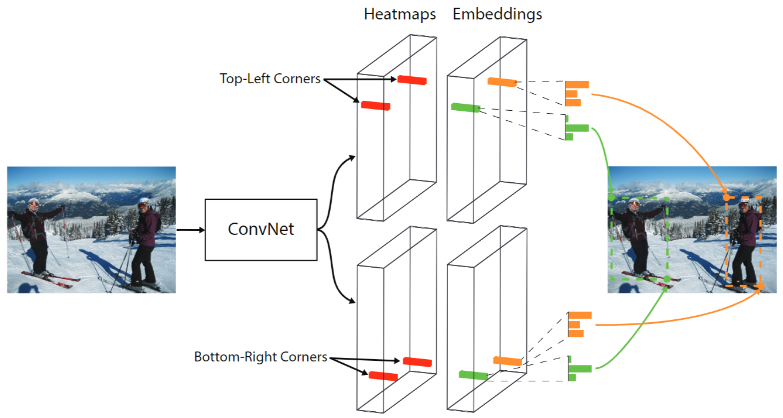
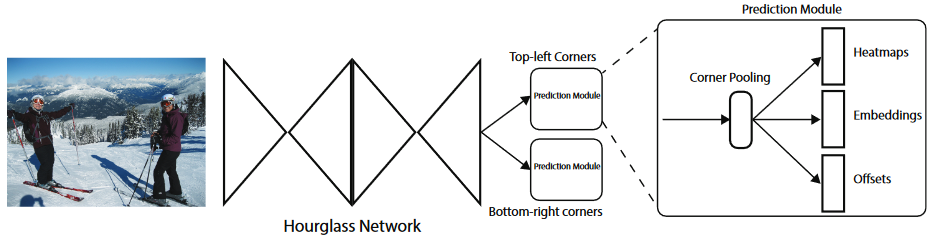
CornerNet 的网络结构?
![]()
- CornerNet 的主干网络是 2 个 Hourglass 组成,其中下采样不使用 pooling 实现实现,而是通过 stride=2 实现
- 输入:输入图片,(1, 3, 416, 416)
- 输出:
![Drawing 2023-02-08 08.54.46.excalidraw]()
CornerNet 的损失函数?
- heatmaps loss: 直接使用 focal loos 计算 heatmap 的损失,所有样本均计算损失
- offsets loss: 先使用 tag 监督信息拿到当前预测位置的 offset 值,再与监督的 offset 计算损失,仅正样本计算损失
- embeddings loss: 先使用 tag 监督信息拿到当前预测位置的 embeddings 值,然后按照配对的接近,不配对的远离计算损失,仅正样本计算损失
CornerNet 如何解码模型输出的?
- 热图(heatmaps)nms 处理:对 heatmap 进行 3x3 的池化 (pad=1),输出保持分辨率不变,将池化后的结果与 heatmap 比较,值改变的位置就是非极大位置,将这些位置的置信度置 0,那么后续这些位置不可能作为角点,这起到非极大值抑制的作用
- 选取候选角点:不分类别,从上面的 heatmp 选择 top100 个左上角和 top100 右下角的位置,并根据位置预测的 offsets 调整角点位置
- 根据嵌入向量 (embeddings) 配对角点:计算左上角和右下角(每个左上角都和其余 99 个右下角)位置对应的 embedings 之间的距离距离大于 0.5 、属于不同类别、座标关系不满足(左上不能大于右下)的角点不能配对
- 目标检测分数:角点匹配完成后,根据每对角点的平均置信度选出 top100 对,每对平均得分作为各目标的检测分数
- 目标 nms:分别对各个类别的 bbox 进行 nms 处理
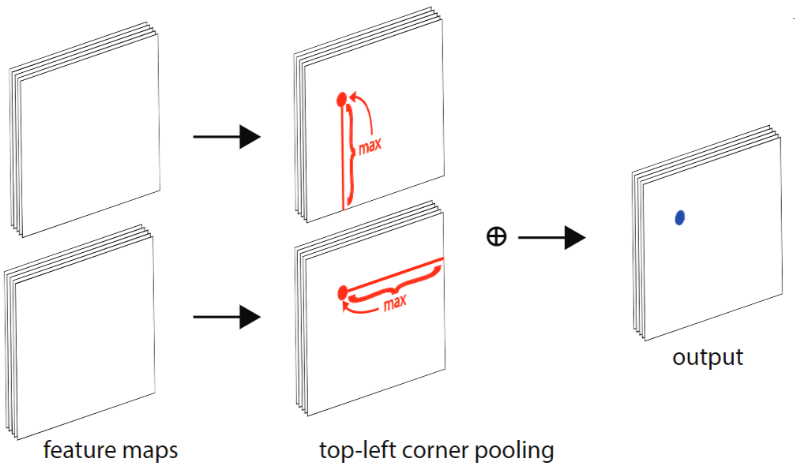
什么是 Corner pooling?
![CornerNet-20230408152549]()
![CornerNet-20230408152549-1]()
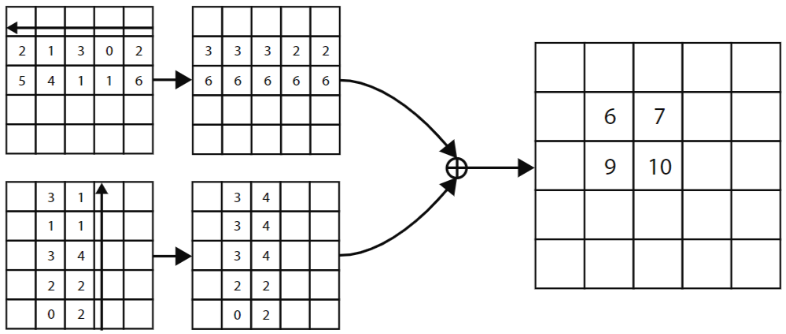
- 求解某一个点的 top-left corner pooling 时,就是以该点为起点,水平向右看遇到的最大值以及竖直向下看最大的值之和
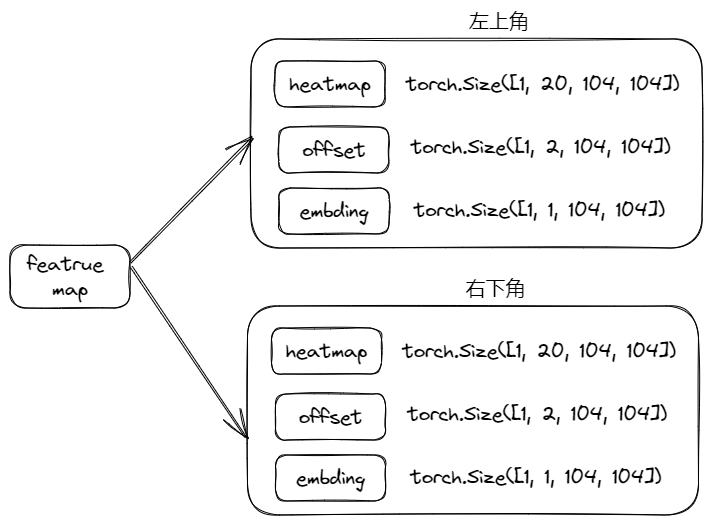
CornerNet 如何制作样本?
- 输入:输入图片,(2, 3, 416, 416)+ 人工标注
- 输出:
- 左上角 heatmap (tl_heatmaps) (2, C, 104, 104)
- 右上角 heatmap(br_heatmaps) (2, C, 104, 104)
- 左上角便签编码(tl_tags) (2, 100)
- 右上角便签编码(br_tags) (2, 100)
- 左上角 offset(tl_regrs) (2, 100, 2)
- 右上角 offset(br_regrs) (2, 100, 2)
- 前 100 个元素有需要被预测的赋值 1,否则 0 tag_masks(2, 100)
- C 表示目标的类别(注意:没有背景类),这个特征图的每个通道都是一个 mask,mask 的每个值(范围为 0 到 1)表示该点是顶点的分数,由高斯核生成
- CornerNet 每张图只预测前 100 个点,tl_tags、br_tags 记录前 100 个预测点的坐标,计算损失时只计算前 100 个预测点的损失
什么是 embedding vector?
![]()
- 监督信息:(1) 左上角便签编码 tl_tags(2, 100);(2) 右上角便签编码 br_tags (2, 100)
- 先使用 tag 监督信息拿到当前预测位置的 embeddings 值,然后按照配对的接近,不配对的远离计算损失