深度学习模型量化技术
总结模型量化的技术
量化原理
量化是模型压缩的一种方式,通过将模型参数从宽范围调整宰范围,使得计算量降低
未量化前权重和激活的表示范围是 FP32,量化可以是 FP16、TF8,甚至是 4bit、2bit
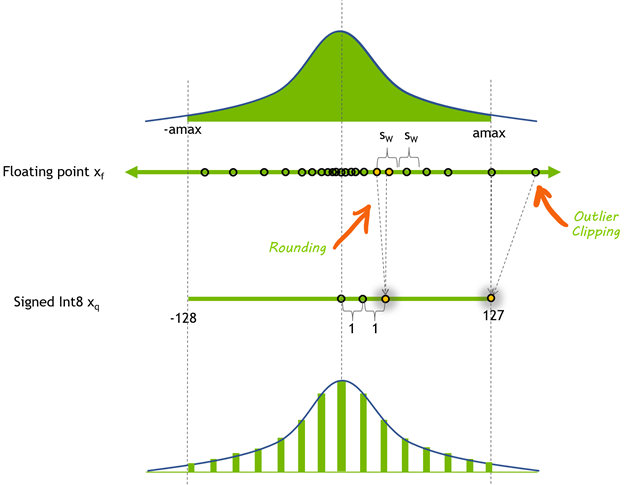
- FP32 表示的范围:浮点数范围在 [-3.4e38,3.4e38] 之间,这个区间被称为动态范围 (dynamic-range)
- int8 量化:使用 scale-factor 将浮点张量的动态范围映射到 [-128,127],又称对称量子化,因为范围关于原点对称,TensoRT 使用对称量化来表示激活值与权重
- 量化计算公式:对任意浮点张量分布,拿到绝对值最大的元素 max,量化的目的是将浮点数从 [-max,max] 缩小到 [-128,127],则先计算 [-max,max] 被 256 等分,然后判断浮点数处于第几等分上
为什么量化后模型推理变快了呢?可以从以下角度分析:
- 吞吐量变大:使用更加快速的 INT8 内核进行计算,其速度更快
- 数据交换时间更少:尤其是数据交换从原来的 32 位,变为 8 位,交换的数据量减少到 1/8
- 减少带宽占用:有些层有带宽限制(内存有限)。这意味着它们的实现将大部分时间用于读写数据,因此减少它们的计算时间并不会减少它们的总体运行时间。带宽限制层从减少的带宽需求中获益最大
- 减少内存占用:模型需要更少的存储空间,参数更新更小,缓存利用率更高
量化按技术路线
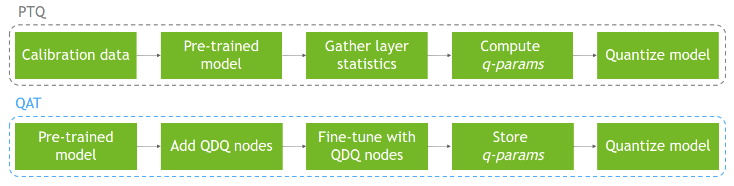
训练后量化 (PTQ):
- 在训练得到的高精度模型后,统计权重和激活值的动态范围和量化参数(q-parms)后,再进行量化操作
- 分为 2 个量化阶段:1) 量化权重,这个很简单,因为权重可以直接被访问,所以可以很轻松计算得到其分布;2) 量化激活,这个比较麻烦,因为必须使用实际输入数据才能测出其分布
- 校准 (Calibration): 在量化激活时,输入代表性数据集,获得层间激活分布的过程
- 训练得到模型后再进行量化,按照是否提前确定激活值量化参数,又分为静态量化:提前通过校准确定量化参数;动态量化:前向推理过程中动态计算量化参数
量化感知 (QAT):
- 训练后量化 (PTQ) 有时候出现无法接受的精度损失,这时候就需要使用量化感知训练 Quantization Aware Training (QAT),它的主要思想是:在训练阶段包含加入量化算子,训练时学习量化参数,使得网络可以适应量化后的权值与激活
- 通过在训练图中插入量化操作 (Q) 和反量化操作 (DQ),实现将量化误差包含在网络中,以使得 量化参数 更加符合网络,减少精度损失
训练后量化核心过程的是校准,比较简单,量化感知训练涉及训练过程,比较复杂,我们来看看是怎么回事
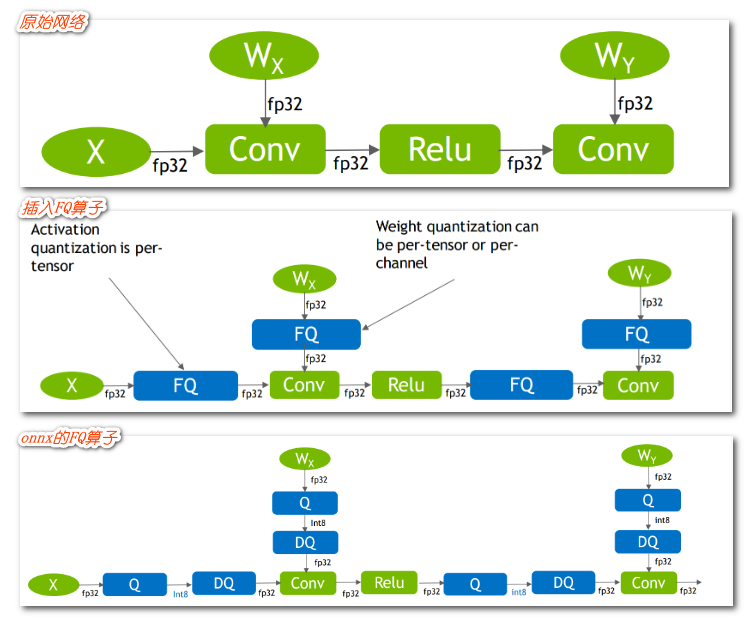
- QAT 量化中最重要的就是 fake 量化算子,fake 算子负责将输入该算子的参数和输入先量化后反量化,然后记录这个 scale
- 上图原始网络精度是 FP32,输入和权重因此也是 FP32
- FQ (fake-quan) 算子会将 FP32 精度的输入和权重转化为 INT8 再转回 FP32,记住转换过程中的尺度信息
- FQ (fake-quan) 算子在 ONNX 中可以表示为 QDQ 算子
在带量化算子的 pytorch 模型转为 onnx 后,模型中会带有 Q/DQ 的算子,那么在 tensorrt 部署框架如何使用这个模型呢?
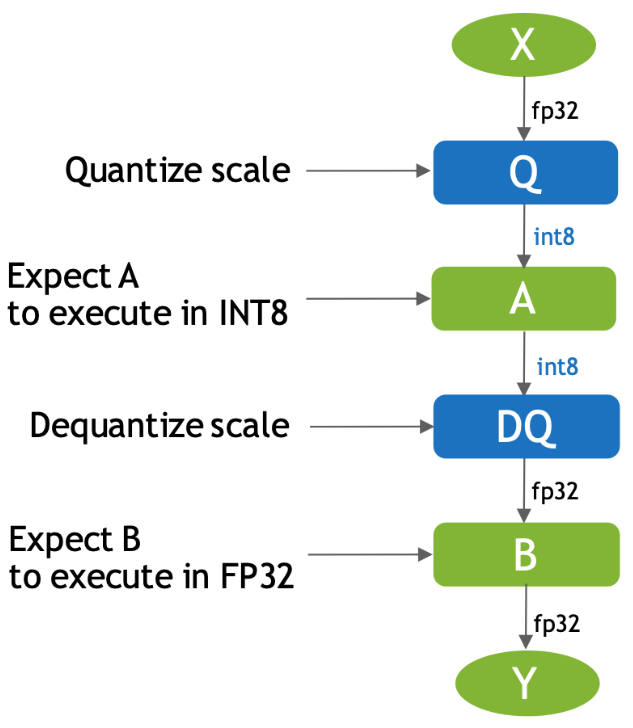
- 输入 X 是 FP32 类型的 op,输出是 FP32,在输入 A 这个 op 时会经过 Q(即量化)操作,这个时候操作 A 我们会默认是 INT8 类型的操作,A 操作之后会经过 DQ(即反量化)操作将 A 输出的 INT8 类型的结果转化为 FP32 类型的结果并传给下一个 FP32 类型的 op
- 有了 QDQ 信息,TensorRT 在解析模型的时候会根据 QDQ 的位置找到可量化的 op,然后与 QDQ 融合(吸收尺度信息到 OP 中)
![Pasted-image-20230103150719]()
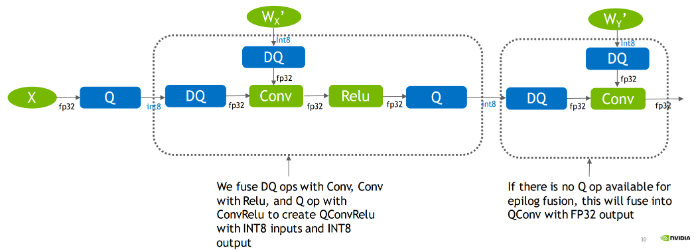
在 tensorrt 优化这个 Q/DQ 操作的方式很多,比如 QDQ-ONNX 网络在输入到 TensorRT 中的时候,TensorRT 的算法会 propagate 整个网络,根据一些规则适当移动 Q/DQ 算子的位置,(需要尽可以拼凑出 QDQ 结构,使整个网络尽可能多的 op 变为量化算子)然后再执行 QDQ 融合策略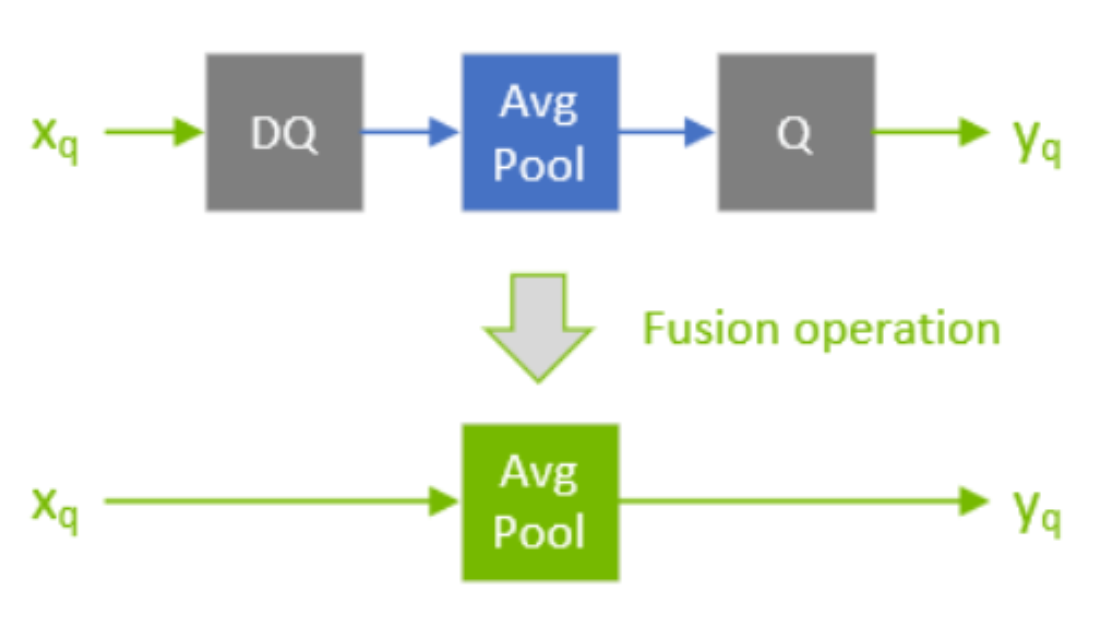
然后尽可能将 DQ 算子推迟,推迟反量化操作 ± 尽可能将 Q 算子提前,提前量化操作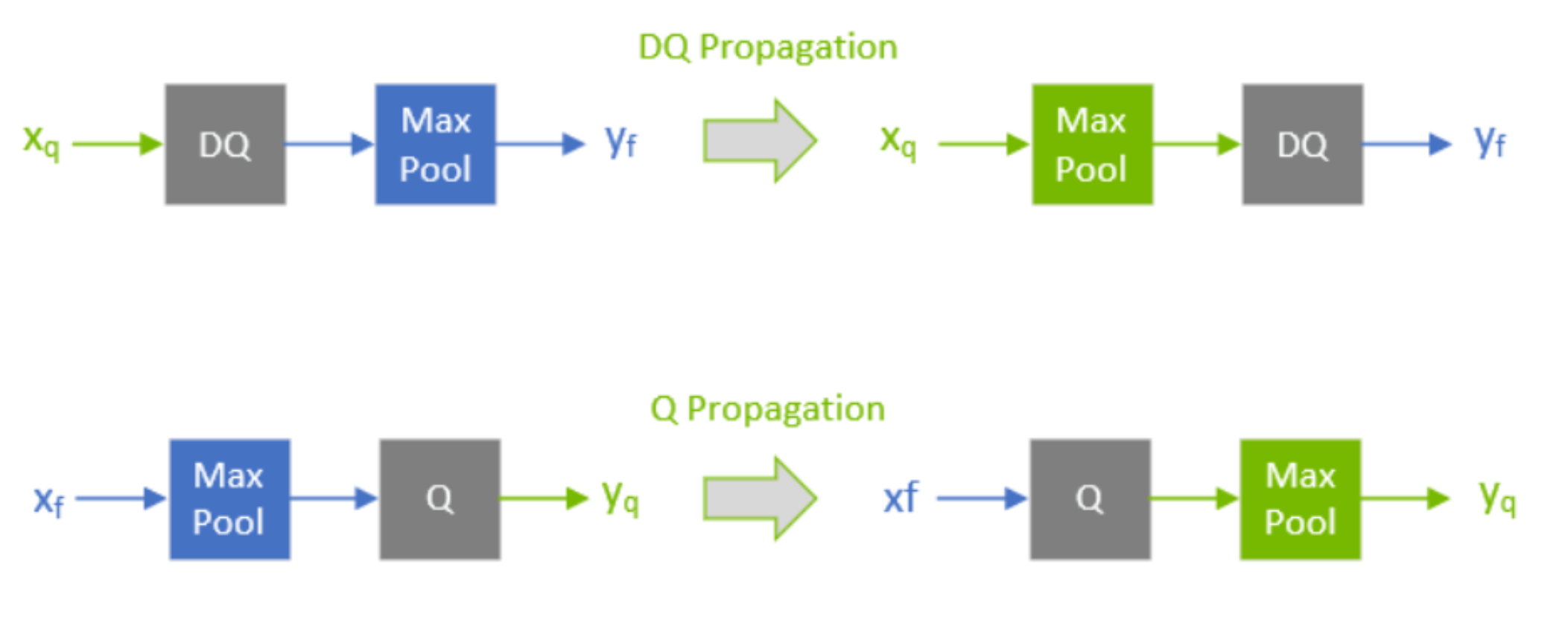
参考: