大分辨率图片下的多类别多目标识别
在大分辨率图片的多类别多目标识别领域,技术的发展经历了从传统模板匹配到现代人工智能技术的转变。传统模板匹配方法,尽管在目标特征固定时表现出色,却难以适应目标的旋转、放大或部分遮挡,这限制了它在复杂场景中的应用。随着技术的进步,直接应用 AI 技术成为可能
本文该方法首先对大分辨率图片进行重叠切割,这一步骤允许我们更细致地处理图像的每个部分,避免了因缩放而丢失小目标的问题。随后,利用多线程技术并行处理各个分块,显著提升了处理速度。在此基础上,应用 AI 技术对每个分块进行快速而准确的识别,确保了识别的精度。最终,通过智能的结果融合策略,将各个分块的识别结果综合起来,不仅提高了识别的准确性,也增强了系统的鲁棒性。
思路
本发明提供一种大分辨率图片下的多类别多目标识别方法,包括以下步骤:
1. 重叠切割: 在处理大分辨率图片时,我们首先采用重叠切割的方法。这种策略的引入是为了解决目标在图像边缘被切割导致 AI 无法学习的问题。以 14400x10800 像素的图片为例,我们将图片划分为 1024x1024 像素的块,同时保证每个块在上下左右方向上具有 20% 的重叠区域。这样的设计确保了即使目标对象位于图像的边缘,也能在至少一个分块中完整呈现。通过这种方法,我们最终能够从原始图像中切出 235 张具有重叠区域的图片,为后续的 AI 识别提供了更加精确的输入数据。
2. 训练 AI 识别器:在完成图片的重叠切割之后,接下来的任务是对这些小图进行 AI 识别器的训练。我们选择 YOLOv10 模型作为识别器,该模型以其在目标检测任务中的速度和精度而著称。通过在切割后的小图上进行训练,YOLOv10 能够学习到多类别多目标的特征,从而在小图上实现高效的目标识别。这一步骤是实现快速且准确识别的关键,为后续的多线程并行处理打下了坚实的基础。
3. 多线程识别大图:利用多线程技术,我们可以显著提高大图的识别效率。在这一步骤中,我们将利用多线程快速处理切割后的图片块,同时并行地应用训练好的 AI 识别器对每个分块进行分析。这种方法不仅能够充分利用现代多核处理器的计算能力,还能够大幅度缩短整体的处理时间,实现对大分辨率图片的快速响应。
4. 多目标识别结果融合:最后,为了解决由于重叠切割带来的重复识别问题,我们采用了非极大值抑制(Non-Maximum Suppression, NMS)算法。在这一步骤中,我们根据目标识别的置信度对结果进行筛选和融合。通过比较不同分块中识别到的同一目标,我们保留置信度最高的结果,并抑制其他低置信度的识别,从而有效减少重复识别,提高识别的准确性。这一融合过程是确保最终结果既精确又一致的关键环节。
创新点
原始的 nms 直接按照预测打分排序预测框,然后使用 iou 过滤重叠框,这就要求对 “预测打分” 有足够自信,所谓足够自信,就是相信模型输出 “好预测框的分数” 比 “次一些的预测框分数” 高,这在单图优化确实可以做到。比如下图,假设图片有目标 A、B、C,其中红色框是标注的真实框,目标 A 的预测框有 2 个,分别标为 1、2,可以看出预测框 2 比 1 号预测框好。神经网络学习的目的是计算预测框和真实框的距离,然后再更新网络,所以预测框 2 比预测框 1 的距离更小,网络学习使得预测框 2 与预测框 1 的预测分数有竞争排斥关系,即预测框 2 越来越接近真实框,所以其分数越来越高,预测框 1 越来越远离真实框,其分数越来越低,这样最后才能通过高分数选择高质量的预测结果,因此可以得出结论:网络学习目的是输出越来越准确的预测框,并给出越来越高的预测分数。
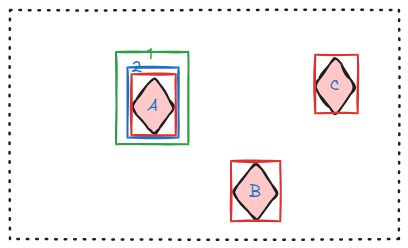
有了这个结论,可以认为当模型对同一目标进行预测时,预测分数越高其预测框越准确,那么就可以使用 nms 对选择高预测分数的预测框,过滤掉预测分数低的,但是这个传统的目标检测处理后处理方式在大分辨率重叠预测上不适用。
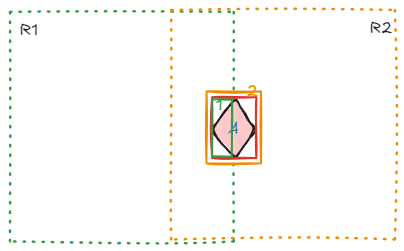
假设图片进行重叠切图时,切图边缘刚好经过目标,图片 R1 只包含部分目标 A,R2 包含整体目标,网络训练时 R1、R2 图片分别进行,神经网络并不知道这两个目标是来自大图同一目标的不同部分,所以他们分数没有竞争排斥关系,所以网络学习的目的是各自推高框 1、框 2 的预测分数。这样会带来一个问题,预测框 1 只有一小部分,更容易学习,其预测分数比预测框 2 的预测分数更高,直接使用 nms 会过滤掉预测框 2,但是明显我们需要的是预测框 2。
关于使用框融合的问题,还是以上图为例,实际上预测框 2 已经接近真实框,如果预测框 1 和预测框 2 进行加权平均,其预测框效果更差,如果有多个类似预测框 1 时,效果就是靠近预测框 1,这还是无法实现 “保留预测框 2、过滤预测框 1” 的目的。
再回头思考一下,造成 nms 无法使用的原因是重叠切图带来的目标在不同图像块上多次预测,由于不同图像块的预测分数没有竞争排斥关系,所以分数最高的预测框不一定是框得最准的。既然是重叠切图造成的,那修改 nms,确保预测框面积较大的结果被保留,过滤面积较小,实践效果如下:
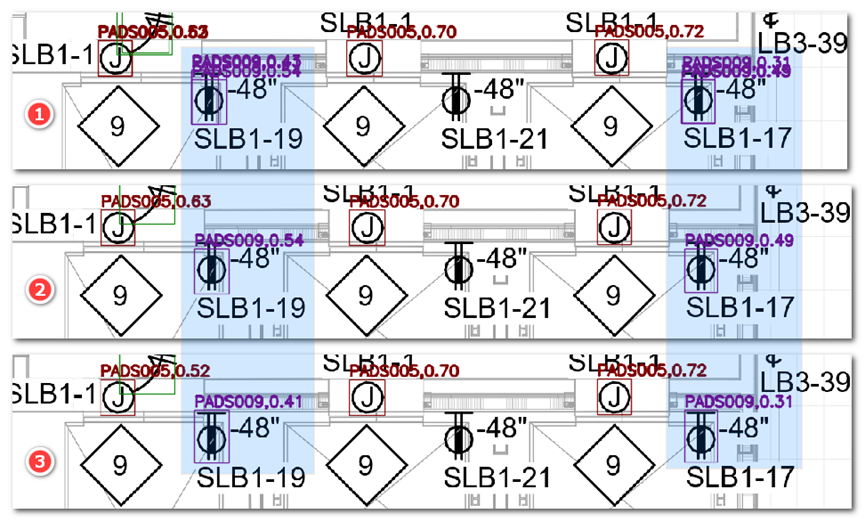
图片 1、2、3 分别是未进行 nms、根据预测分数进行 nms、根据面积进行 nms,从 1 可知着色区域的目标有两个预测结果,根据预测分数 nms 得到的框,预测分数更高,但是并没有框住目标,而根据面积进行 nms 的预测框虽然预测分数低一点,但是更贴合目标。
更进一步,使用面积替代预测分数选择预测框,能解决问题的原因是:假定任何目标在重叠切图下,必定有一个切块存在完整目标(预测面积最大的),如果存在一个大目标,横跨多个切图时,比如下图,切图 R1、R2 都无法预测到完整目标,只使用面积 nms 会从预测框 1 或预测框 2 选择其中一个或者认为有两个预测框,这都是不准确的。实际上,这里应该使用框融合,融合 2 个小框为 1 个大框。那么什么情况下只使用面积 nms,什么情况下使用框融合呢?
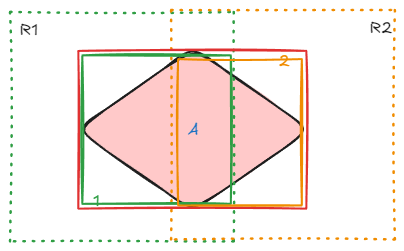
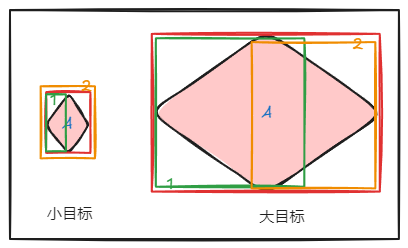
本文通过计算 “重叠面积对待分析预测框面积占比 “的后处理方式,下面分小目标和大目标情况进行讨论,小目标的预测框 1、2 的重叠区域占各自面积百分比为 100%,40%,预测框 1 占比为 100%,这时按照面积 nms 过滤即可;大目标的预测框 1、2 的重叠区域占各自面积百分比为 30%,40%,说明两个框很大部分没重叠,此时使用 WBF 对这两个框进行融合。
实践证明,加入 “重叠面积对待分析预测框面积占比” 的阈值后,可以解决单纯面积阈值过滤方式的两个问题,一是重叠时 nms 的 IOU 阈值大于实际 IOU 导致无法过滤的情况,如下图,标号 1、2、3 分别是无 nms、面积 nms、面积 nms+“重叠面积对待分析预测框面积占比” 阈值,从标号 1 看出,AI 输出 3 个检测框,从标号 2 可以看出,由于计算的 IOU 小于 nms 的过滤 IOU 阈值,所以有一个重叠框没被过滤,在使用 “重叠面积对待分析预测框面积占比” 阈值后,内部的预测框被过滤。
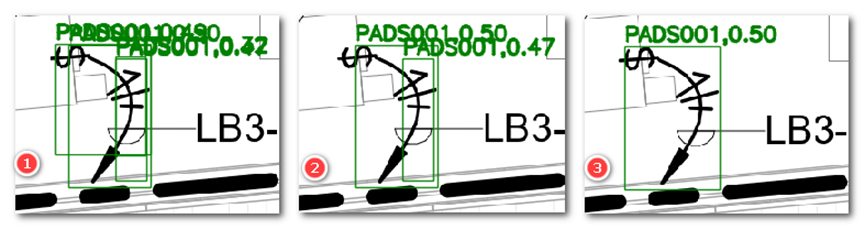
还有一个优势是,重新组合预测框提升框的准确度,如下图标号 1、2、3 分别是无 nms、面积 nms、面积 nms+“重叠面积对待分析预测框面积占比” 阈值,从标号 1 可以看出,AI 输出 2 个预测框,仅使用面积过滤,只能过滤一个框,使用 “重叠面积对待分析预测框面积占比” 阈值后,对这两个框进行重新组合,得到一个新的框,新的框更加准确框住目标。

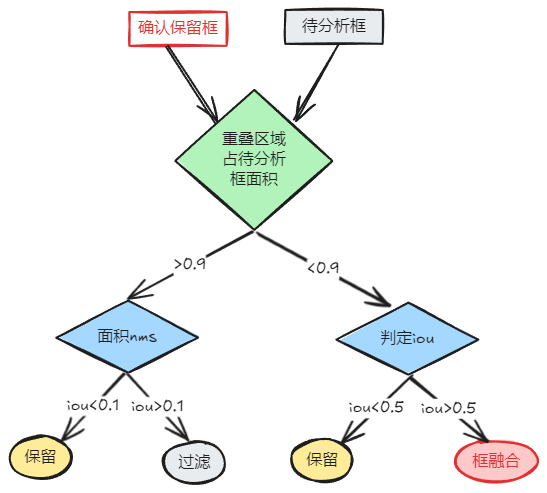
所以,总结基于大分辨率下的 nms 思路如下:待分析框被保留认为 AI 预测了 2 个目标的检测框,而不是 1 个目标的重叠框,框融合使用取确认保留框与待分析框的横纵座标最小最大值即可,假设确认保留框的左上角和右下角座标为,待分析框的左上角及右下角座标为,那么框融合后座标变为
效果
本文提出的大分辨率图片下的多类别多目标识别方法大大提高识别效率及识别精度,在对某一张包含 100 以上目标的 14400x10800 分辨率的图片分析实践中,使用模板匹配的技术耗时 5 分钟,识别准确率只有 60%,而直接在大图上使用 AI 的技术耗时 1 分钟,识别准确率达到 85%,而采用本文的技术,可以在 5 秒内实现 98% 以上的识别效果,在速度和精度上超越现有方法。