06-TensorRT 实践
TensorRT 如何指定 GPU?
- Python 直接使用环境变量
1
2import os
os.environ['CUDA_DEVICE'] = '1' - C++ 使用 cuda 设置
1
2
3
4
5if (cudaSetDevice(device) != cudaSuccess)
{
gLogError << "cudaSetDevice failed" << std::endl;
return;
} - 注意,有文章指出多线程运行时,数据从内存拷贝至 GPU 之前,需要再次指定设备,未验证
1
2
3
4
5cudaSetDevice(mDevice); #最关键的一行一定要加入
CHECK(cudaMemcpyAsync(buffers[0], input, batchSize * 3 *mInputH * mInputW * sizeof(float),cudaMemcpyHostToDevice, stream));
context.enqueue(batchSize, buffers, stream, nullptr);
CHECK(cudaMemcpyAsync(output, buffers[1], batchSize * mOutPutSize * sizeof(float), cudaMemcpyDeviceToHost, stream));
cudaStreamSynchronize(stream);
什么是 TensorRT 异步推理?
- 异步推理时输入从主机 (CPU) 复制到设备 (GPU) ,然后通过 enqueue 函数执行推断,并异步复制结果
- 异步推理执行通常通过重叠计算提高性能,因为它最大限度地提高了 GPU 的利用率
- Enqueue 函数将推断请求放在 CUDA 流上,并接受运行时批处理大小、指向输入、输出的指针,以及用于内核执行的 CUDA 流作为输入。异步数据传输是使用 cuda/emcpyasync 从主机到设备进行的
- 推理结束后使用 cudaStreamSynchronize 函数可以确保 GPU 在访问结果之前完成计算
TensorRT 异步推理、同步推理有什么差异?
- 使用 execute/sync api 的好处是简单性 / 代码可以内联执行
- 使用 Enqueue/async api 的挑战是在使用 / 释放缓冲区时处理信号事件的额外工作,且使用异步模型的 GPU 效率更高
C++ 端的 TensoRT 异步推理时的关键步骤?
- 创建上下文
1
2
3// 创建一些空间来存储中间激活值。由于引擎保存网络定义和训练参数,因此需要额外的空间。这些保存在执行上下文中
// 一个引擎可以有多个执行上下文,允许一组权重用于多个重叠的推理任务,如使用一个引擎和每个流的上下文处理并行的CUDA流中的对象,每个上下文都在与引擎相同的GPU上创建
IExecutionContext *context = engine->createExecutionContext(); - 异步推理
1
2// 要在多个 CUDA 流中同时执行推理,要求每个 CUDA 流使用一个执行上下文
context->enqueueV2(buffers, stream, nullptr);
使用 TensorRT 层缓存文件注意事项?
- 该功能从 tensorrt8 开始支持
- 在具有不同 CUDA 设备属性的设备之间共享缓存可能会导致功能 / 性能问题
- 建议仅当设备具有相同的设备型号但不同的通用唯一标识符 (UUID) 时才执行此操作
- 加载的缓存必须由与当前构建器实例相同版本的 TensorRT 生成
TensorRT 层缓存文件在同版本软件环境但不同版本的硬件条件下的使用?
- 跨设备使用层缓存文件没有报错
- 引擎的构建过程和从 onnx 开始构建引擎的时间基本一样,没有明显的时间减少
C++ 构建层计时缓存的步骤?
- 读取层计时缓存文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28// 读取引擎构建时的缓存
const string timingCacheFile = onnxEncryptFilePath + ".timingCache"; //不带后缀的文件路径
std::vector loadedCache = loadTimingCacheFile(timingCacheFile);
std::unique_ptr timingCache{ nullptr };
timingCache.reset(config->createTimingCache(static_cast(loadedCache.data()), loadedCache.size()));
if (!timingCache) {
CLog::get_instance()->WriteLog("[ERROR][segment]LoadTensorrtEngine.cpp:TimingCache creation failed");
return -6;
}
config->setTimingCache(*timingCache, false);
inline std::vector loadTimingCacheFile(const std::string inFileName)
{
std::ifstream iFile(inFileName, std::ios::in | std::ios::binary);
if (!iFile)
{
//sample::gLogWarning << "Could not read timing cache from: " << inFileName
// << ". A new timing cache will be generated and written." << std::endl;
return std::vector();
}
iFile.seekg(0, std::ifstream::end);
size_t fsize = iFile.tellg();
iFile.seekg(0, std::ifstream::beg);
std::vector content(fsize);
iFile.read(content.data(), fsize);
iFile.close();
//sample::gLogInfo << "Loaded " << fsize << " bytes of timing cache from " << inFileName << std::endl;
return content;
} - 保存层计时缓存文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// 保存引擎构建时的缓存
auto serializedTimingCache = config->getTimingCache();
std::unique_ptr timingCacheHostData{ serializedTimingCache->serialize() };
//IHostMemory* timingCacheHostData = serializedTimingCache->serialize();
if (!timingCacheHostData) {
CLog::get_instance()->WriteLog("[ERROR][segment]LoadTensorrtEngine.cpp: Timing Cache serialization failed");
return -12;
}
saveTimingCacheFile(timingCacheFile,timingCacheHostData.get());
inline void saveTimingCacheFile(const std::string outFileName, const IHostMemory* blob)
{
std::ofstream oFile(outFileName, std::ios::out | std::ios::binary);
if (!oFile)
{
//sample::gLogWarning << "Could not write timing cache to: " << outFileName << std::endl;
return;
}
oFile.write((char*)blob->data(), blob->size());
oFile.close();
//sample::gLogInfo << "Saved " << blob->size() << " bytes of timing cache to " << outFileName << std::endl;
}
TensorRT 构建网络时占用设备内存解释?
- 构建过程可以暂时使用比网络运行时需要更多的设备内存
- 这个阶段具有以下特点
- 为引擎所需的权重使用两倍的内存,没有为激活分配内存
- 构建时间线记录器需要消耗内存,FP32 中的层进行计时所消耗的设备内存是 FP16 操作的两倍,是 INT8 操作的四倍,包括权重及其输入 / 输出激活
- 在具有统一 CPU/GPU 内存的系统上, 构建器的 CPU 内存消耗会进一步影响内存需求。 构建器 CPU 内存中不仅可以保存通过 API 提供的原始权重,还可以保存不同精度的权重副本,或者根据来自原始网络的多个权重计算得出
- 注意: CUDA 基础设施和设备代码也会消耗设备内存。内存量因平台、设备和 TensorRT 版本而异。使用 cudaGetMemInfo 以确定正在使用的设备内存总量
TensorRT 运行网络时占用设备内存的解释?
- TensorRT 引擎将设备内存用于三个目的
- 保存网络所需的权重
- 保存每个上下文的持久状态信息
- 保存网络所需的中间激活执行上下文
- 权重的大小可以与序列化引擎的大小近似
- 每个上下文持久状态信息是在创建执行上下文期间使用 GPU 分配器分配的(即使当 createExecution Context withoutDeviceMemory () 使用 API), 分配的持久内存的大小在创建执行上下文期间生成的详细日志中报告
- 所需的激活内存的大小可以通过调用来确定 ICudaEngine: : getDeviceMemorySize (). 这些总和是 TensorRT 在运行时为引擎分配的设备内存量,以运行网络
- 注意: CUDA 基础设施和设备代码也会消耗设备内存。内存量因平台、设备和 TensorRT 版本而异。使用 cudaGetMemInfo 以确定正在使用的设备内存总量
如何在 TensorRT 中安全地重用执行上下文设备内存?
- IExecutionContext 出于持久和无状态的目的,需要设备内存
- 用户可以通过使用 createexecutioncontextwithdevicememory () 和 setDeviceMemory () 在上下文执行后被应用程序重用,但是 TensorRT 在上下文创建期间分配的持久内存不能在引擎执行之间重用
- 如果用户使用 createExecutionContext () API,没有简单的方法来区分持久内存和无状态内存
使用 TensorRT 推理时,耗时很不稳定?
- 现象:连续执行 TensorRT 时,耗时稳定在 50 ms 左右;一旦执行了 sleep,耗时就很不稳定,在 50-130 ms 之间
- 原因:显卡为了保持性能和功率,会在工作模式和低功耗模式之间切换,但是切换模式是耗时的,导致耗时不稳定
- 解决:
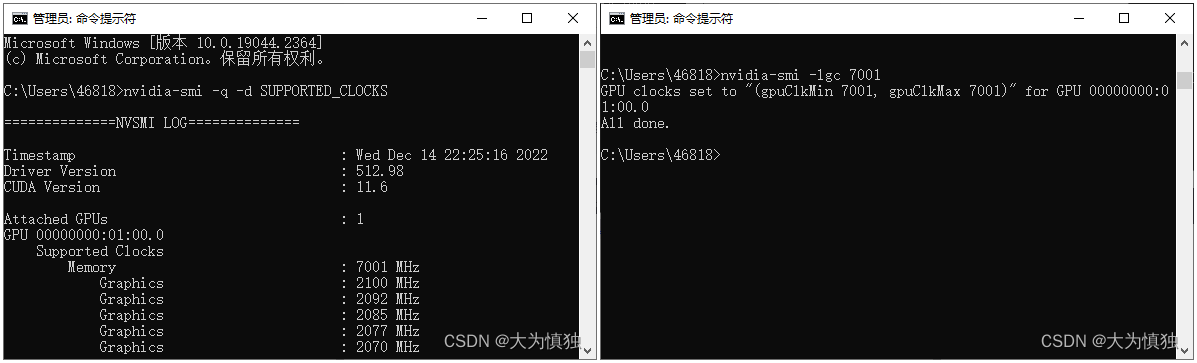
- (1)查询并设置 GPU 支持的最高频率
![]()
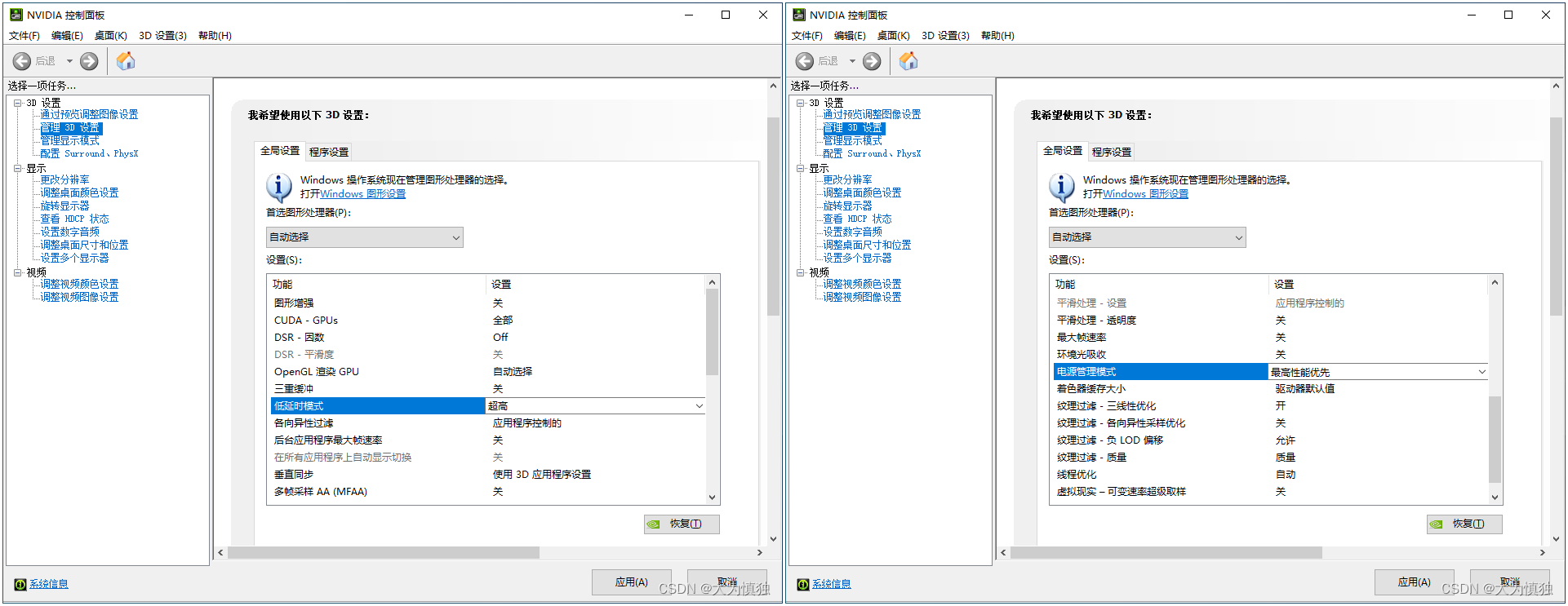
- (2)通过 GPU 设置低时延模式、最高性能模式
![]()
参考:
- (1)查询并设置 GPU 支持的最高频率