CrowdPose:Efficient Crowded Scenes Pose Estimation and A New Benchmark
为解决传统 SPPE 处理密集姿态估计带来的偏差,CrowdPose 设计了 Joint Candidate SPPE 生成众多的候选关节点,然后通过 KM (Keypoint Match) 算法匹配行人实例和候选关节点
什么是 CrowdPose ?
![]()
- 为解决传统 SPPE 处理密集姿态估计带来的偏差 (左图),CrowdPose 设计了 Joint Candidate SPPE 生成众多的候选关节点,然后通过 KM 算法匹配行人实例和候选关节点 (右图)
- CrowdPose 难点在于如何通过 KM (Keypoint Match) 算法整理模型输出,其核心思想是二部图划分,目标是最大化实例与关键点之间的权重

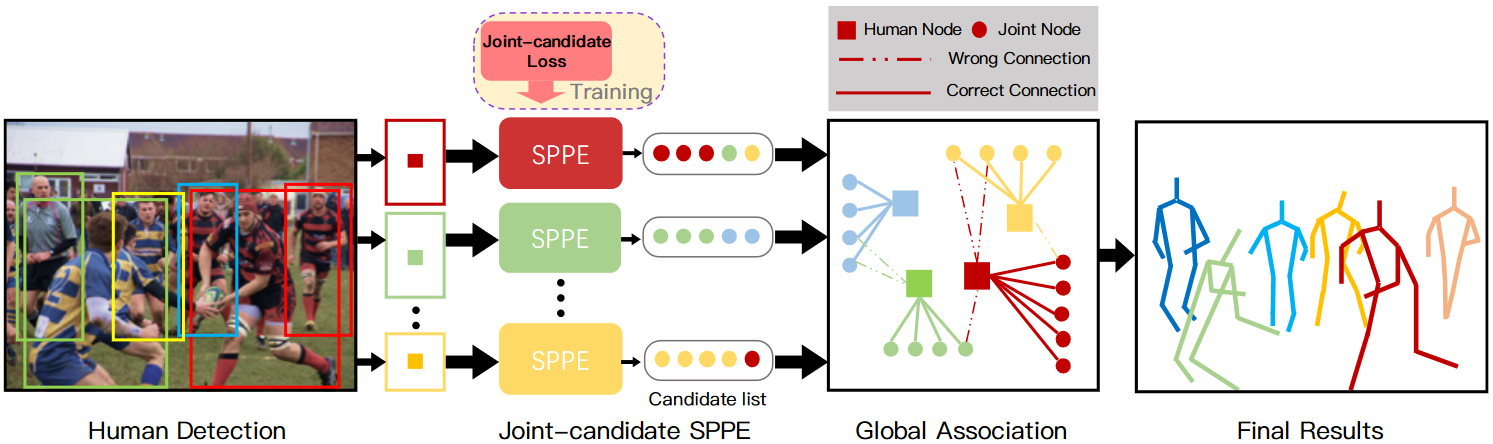
CrowdPose 的网络结构?
![]()
- Human Detection:行人检测器,用于获得单人的 proposal
- Joint-candidate SPPE:针对每个 Human Detection 的结果进行单人姿态检测,注意此时每个关节点的 heatmap 不是取 top 1, 而是取某个阈值以上的所有点 (Joint-candidate)
- Global Assoiciation:针对 Joint-candidate,通过关键点匹配为每个行人实例分配预测关节点
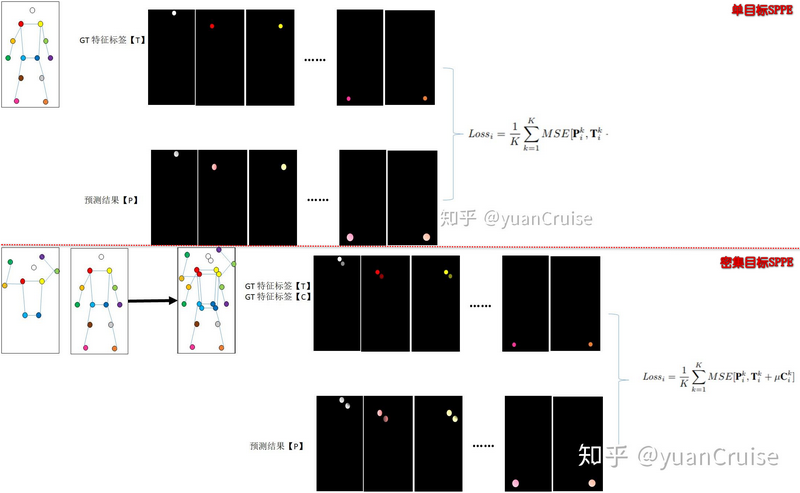
CrowdPose 的 Joint-candidate SPPE?
![]()
- SPPE:上图是 SPPE 的模型输出,可以看出每个关节点 heatmap 只输出 top 1 个预测,其正样本的损失只有 top 1 位置
- Joint-candidate SPPE:下图是 Joint-candidate SPPE 的模型输出,对于某个关节点,通过定义预测阈值得到多个预测位置,这些位置有属于当前行人,也可能属于其他行人的。正样本的损失计算激活位置的损失,但是给于当前行人的关节更大权重,给于非当前行人更小权重
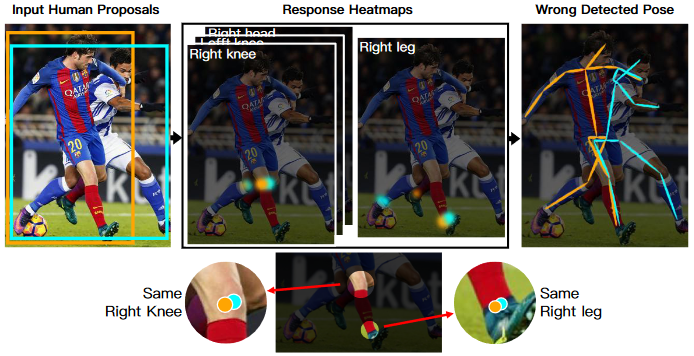
CrowdPose 如何建立 person-joint 连接图?
![]()
- 基于我们的 JC 机制和来自 SPPE 的富余的 human proposals,JC 在数值上要远远多于实际的关节点数。为了减少富余的关节点,我们建立了一种行人 - 关节点图模型,然后通过最大行人 - 关节点匹配算法来获得最终的行人姿态
- 1)Joint Node Building:由于高度重叠的行人 proposals 倾向于预测同样的实际关节(如图)所示。我们首先对这些 JC 进行分组,这样表示同一个实际关节点的视为一个点。分组的依据是预测位置之间的距离,最终得到的 “关节点预测集合”
- 2)Person Node Building:行人节点表示有行人检测器检测到的行人 proposals,最终得到 “行人实例集合”
- 3)Person-Joint Edge:连接 “行人实例集合” 和 “关节点预测集合”,边上的权重为模型在某行人实例在某个关节点的输出打分
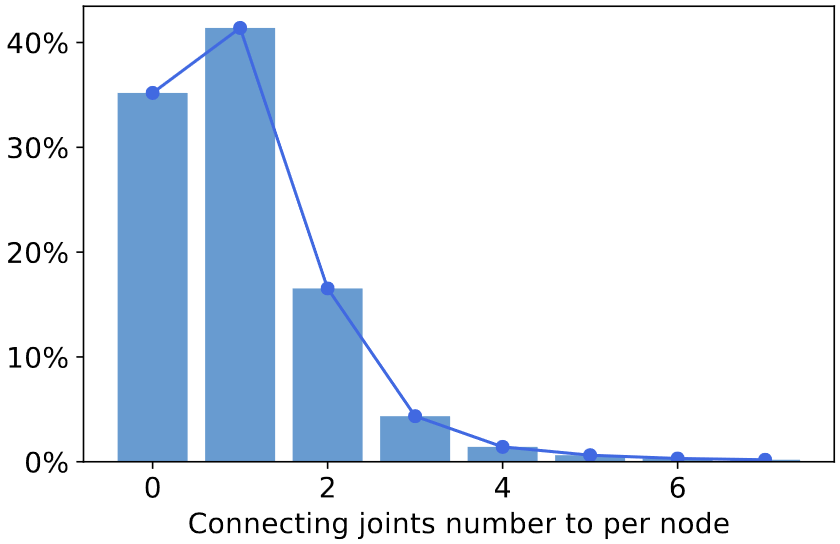
CrowdPose 的 Global Assoiciation?
![]()
- 基于得到的 “行人实例集合” 和 “关节点预测集合” 连接图,通过最大化所有边的权重,完成行人实例 - 预测关节点的匹配
- 和传统的 pose-NMS 相比,KM 算法在全局预测上匹配关节点,可以很好出来遮挡的情况
- 上图是每个行人实例节点数的分布。X 轴表示同一个节点被行人检测框覆盖的框的个数(基于 GT 统计,即行人的 proposals+KM 匹配算法得到)。可以看到:1)超过 30% 的 GT 关节点是未匹配上去,有近一半的预测关节点被分配到一个实例
CrowdPose 的损失函数?
- 整个网络,只有 Joint-candidate SPPE 部分需要训练,计算的损失包含两部分,即当前行人的损失和非当前行人的损失
- 公式 K 的关节点数量,i 表示 heatmap 上的位置,P、K、C 表示预测 heatmap、GT heatmap 以及预测 heatmap 上不属于当前行人的打分
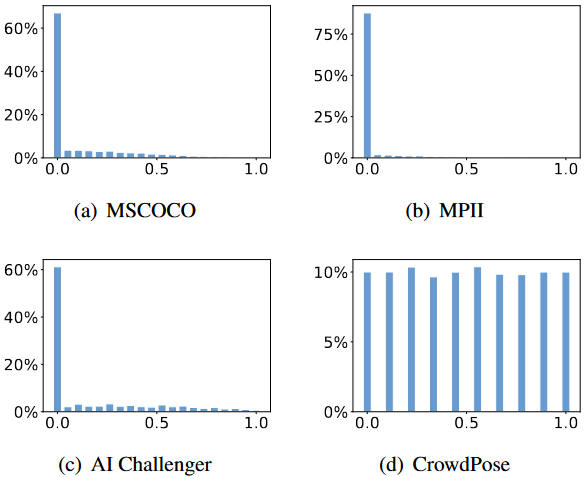
CrowdPose 定义的行人密集程度指标?
![]()
- 对于某个行人实例 i 包含的 box 内,不是本人关节点的数量 和本人关节点数量 的比例,计算所有实例的平均即拥挤程度。上图是 4 个数据集的拥挤程度
参考: