DeepPose:Human Pose Estimation via Deep Neural Networks
DeepPose 是人体姿势估计 (HPE) 的鼻祖,类似 AlexNet 对于 CNN 的作用。DeepPose 不构建关键点之间的关系,直接利用强大的 DCNN 回归出所有关键点 (x, y)
什么是 DeepPose ?
![]()
- DeepPose 是人体姿势估计 (HPE) 的鼻祖,类似 AlexNet 对于 CNN 的作用。DeepPose 不构建关键点之间的关系,直接利用强大的 DCNN 回归出所有关键点 (x, y),因此也只能对单目标的关键点进行分析
- 为提高性能,DeepPose 训练一个级联的姿态回归器。在第一个阶段,先粗略的估计出部分的姿态轮廓,然后在下个阶段,将通过已知关键点位置不断的优化其他关键点的位置。每个 stage 都使用已经预测的关键点来切出基于这个关键点的邻域,这个子图像将被用于接下来的网络输入,而接下来的网络就会看到更高分辨率的图像,最终达到更好的精确率
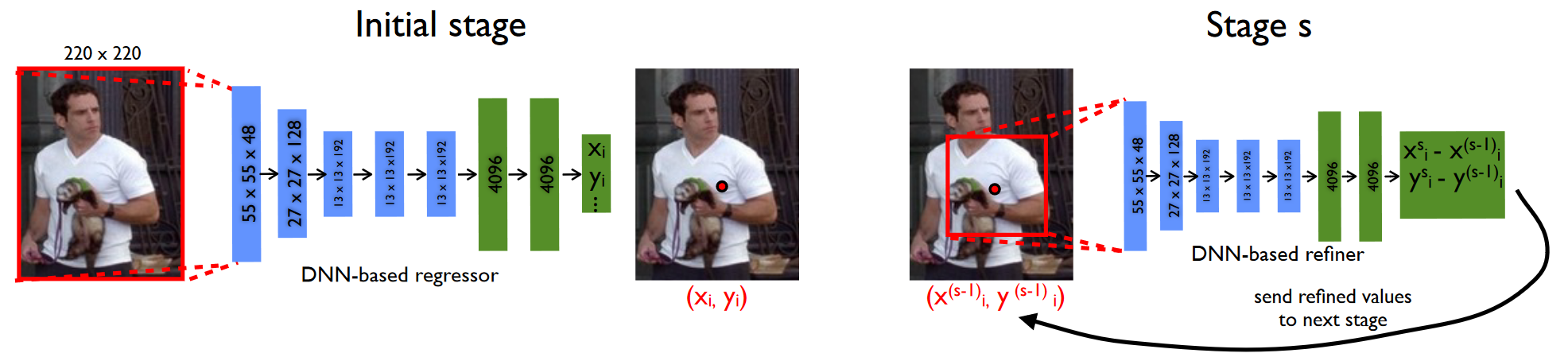
DeepPose 的网络结构?
![]()
- DeepPose 使用 CNN 提取特征,然后直接按关键点 2 倍输出预测
- 为提高性能,DeepPose 还训练一个级联的姿态回归器,不断将预测区域放大分辨率训练下一个 CNN
DeepPose 的样本构造?
- 由于关节坐标是绝对图像坐标,因此需要根据人体框大小将它们标准化。假设框由中心位置、宽和高定义 ,则关键点 按以下公式进行归一化
- 为了简洁,将人体框认定为图片(即按照图片大小进行归一化),针对 gt 关键点构建训练标签,驱动网络学习
DeepPose 的级联回归器?
![]()
- 上图是三级级联网络预测姿态 (红色) 和 ground truth(绿色)
- 训练一个级联的姿态回归器。在第一个阶段,先粗略的估计出部分的姿态轮廓,然后在下个阶段,将通过已知关键点位置不断的优化其他关键点的位置。每个 stage 都使用已经预测的关键点来切出基于这个关键点的邻域,这个子图像将被用于接下来的网络输入,而接下来的网络就会看到更高分辨率的图像,最终达到更好的精确率

DeepPose 的损失函数?
- 不是用的分类损失,而是使用线性回归损失,预测的关键点和 ground-true 的 L2-loss
参考: