openvino 基础知识
什么是 OpenVINO?
![]()
- OpenVINO 是一个开源工具包,用于优化和部署模型到目标设备,包括云及边缘设备,可以被部署的模型可以来自 Pytorch、Tensorflow、ONNX 等。
- OpenVINO 针对 Inter 的硬件设备进行特定优化,尤其是要进行 CPU 推理时,是优先选择框架。
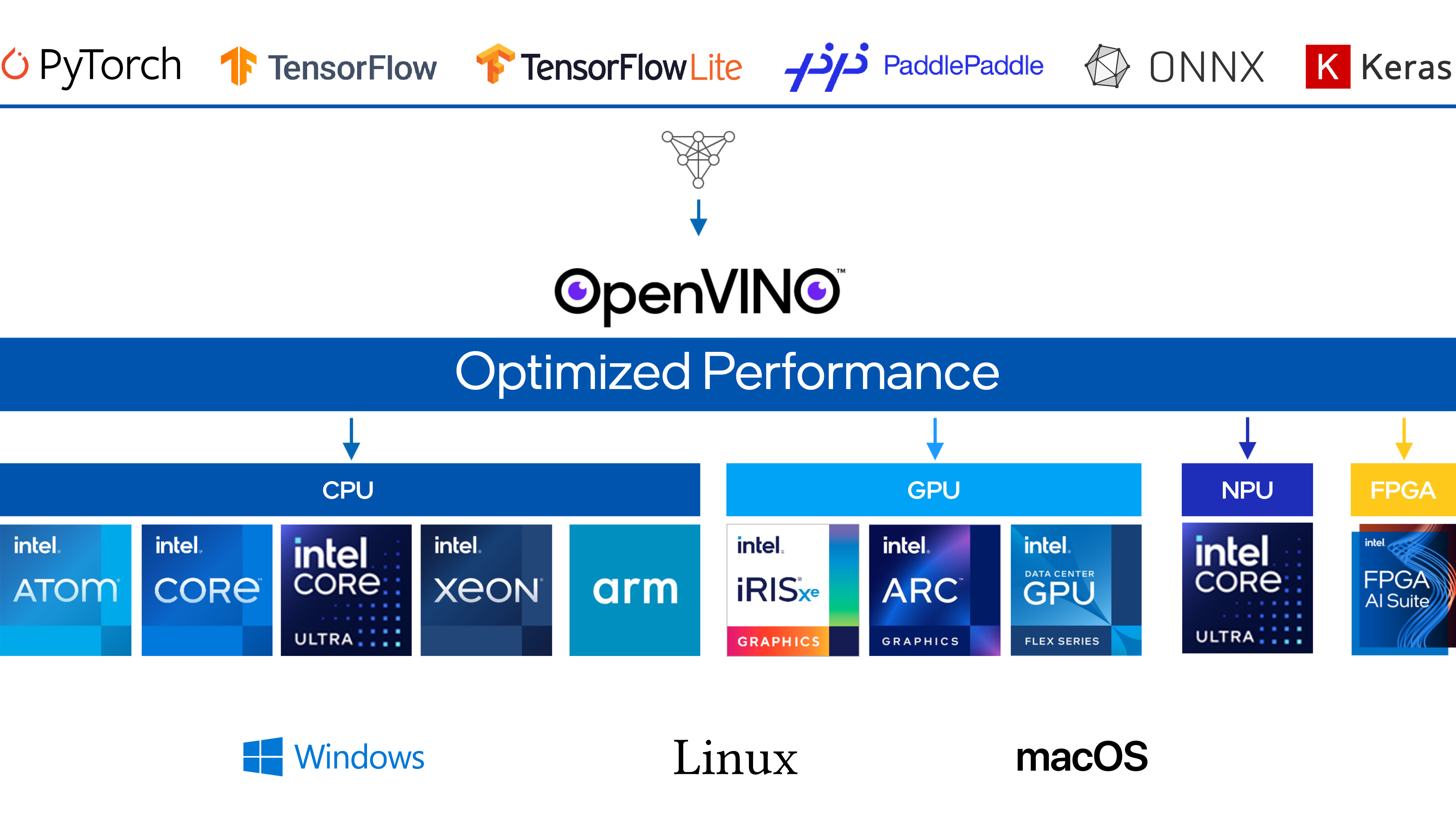
OpenVINO 支持的硬件设备?
- 支持 CPU、iGPU、NPU 设备,具体查看 System Requirements — OpenVINO™ documentation
OpenVINO 支持的模型类型?
- 支持以下模型格式转为为 OpenVINO 模型:PyTorch,TensorFlow,TensorFlow Lite,ONNX,PaddlePaddle,OpenVINO IR
- 使用
convert_model将其他框架模型转为为 OpenVINO 模型1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import openvino as ov
import torch
from torchvision.models import resnet50
model = resnet50(weights='DEFAULT')
# prepare input_data
input_data = torch.rand(1, 3, 224, 224)
ov_model = ov.convert_model(model, example_input=input_data)
###### Option 1: Save to OpenVINO IR:
# save model to OpenVINO IR for later use
ov.save_model(ov_model, 'model.xml')
###### Option 2: Compile and infer with OpenVINO:
# compile model
compiled_model = ov.compile_model(ov_model)
# run inference
result = compiled_model(input_data)
OpenVINO 的模型表示?
- 在使用 OpenVINO 时,模型存在 3 种状态:保存在磁盘上、加载但未编译、加载和编译
- 保存在磁盘上:保存在驱动器上的一个或多个文件,完全表示神经网络。 不同的模型格式以不同的方式存储。例如:OpenVINO IR 的.xml 和 .bin 文件对,ONNX:.onnx 文件
- 加载但未编译:即 ov.Model,通过解析模型文件或者从其他框架转换得来,该对象没用附加到任何设备,不能进行推理,但可以对模型进行重塑,包括添加前处理步骤
- 加载和编译:即 ov.CompiledModel,允许进行设备优化并启用推理
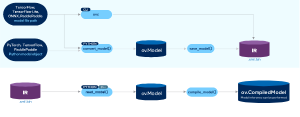
OpenVINO 的工作流程?
![]()
- 在 Python 上完成模型优化,并保存为 openVINO 的中间表示
- 在 C++ 加载 openVINO 模型,并执行推理
OpenVINO 的推理过程?
![]()
- 使用 OpenVINO Runtime 部署 OpenVINO 的模型推理
1
2
3
4
5
6
7
8
9
10
11
12
13
14#Load model
import openvino as ov
core = ov.Core()
compiled_model = core.compile_model("model.xml", "AUTO")
infer_request = compiled_model.create_infer_request()
#Create tensor from external memory
input_tensor = ov.Tensor(array=memory, shared_memory=True)
#Set input tensor for model with one input
infer_request.set_input_tensor(input_tensor)
infer_request.start_async()
infer_request.wait()
#Get output tensor for model with one output
output = infer_request.get_output_tensor()
output_buffer = output.data

如何降低 OpenVINO Runtime 的推理时延?
- 编译模型时,设置为性能模式
1
2
3
4import openvino.properties as props
import openvino.properties.hint as hints
config = {hints.performance_mode: hints.PerformanceMode.LATENCY}
compiled_model = core.compile_model(model, "GPU", config) - 有多个设备时,使用多模型推理
如何提升 OpenVINO Runtime 的吞吐量?
- 编译模型时,设置为吞吐量模式
1
2
3
4import openvino.properties as props
import openvino.properties.hint as hints
config = {hints.performance_mode: hints.PerformanceMode.THROUGHPUT}
compiled_model = core.compile_model(model, "GPU", config) - 使用异步推理,将前处理和模型推理时间重叠
如何将模型前处理编译进 OpenVINO 模型?
- 为模型的每个输入指定前处理过程,使用 PrePostProcessor 对象声明前处理过程,包含 3 个步骤
- (1) 指定前处理输入:指定前处理之前的输入数据格式,包括 shape、NCHW 等
1
2
3
4
5
6
7from openvino.preprocess import ColorFormat
from openvino import Layout, Type
ppp.input(input_name).tensor() \
.set_element_type(Type.u8) \
.set_shape([1, 480, 640, 3]) \
.set_layout(Layout('NHWC')) \
.set_color_format(ColorFormat.BGR) - (2) 前处理操作:指定前处理步骤
1
2
3
4
5
6
7
8from openvino.preprocess import ResizeAlgorithm
ppp.input(input_name).preprocess() \
.convert_element_type(Type.f32) \
.convert_color(ColorFormat.RGB) \
.resize(ResizeAlgorithm.RESIZE_LINEAR) \
.mean([100.5, 101, 101.5]) \
.scale([50., 51., 52.])
# .convert_layout(Layout('NCHW')) # Not needed, such conversion will be added implicitly - (3) 指定模型输入:指定模型输入布局
1
2# `model's input` already `knows` it's shape and data type, no need to specify them here
ppp.input(input_name).model().set_layout(Layout('NCHW')) - 以上过程完成后,使用以下命令,将前处理编译进模型
1
model = ppp.build()
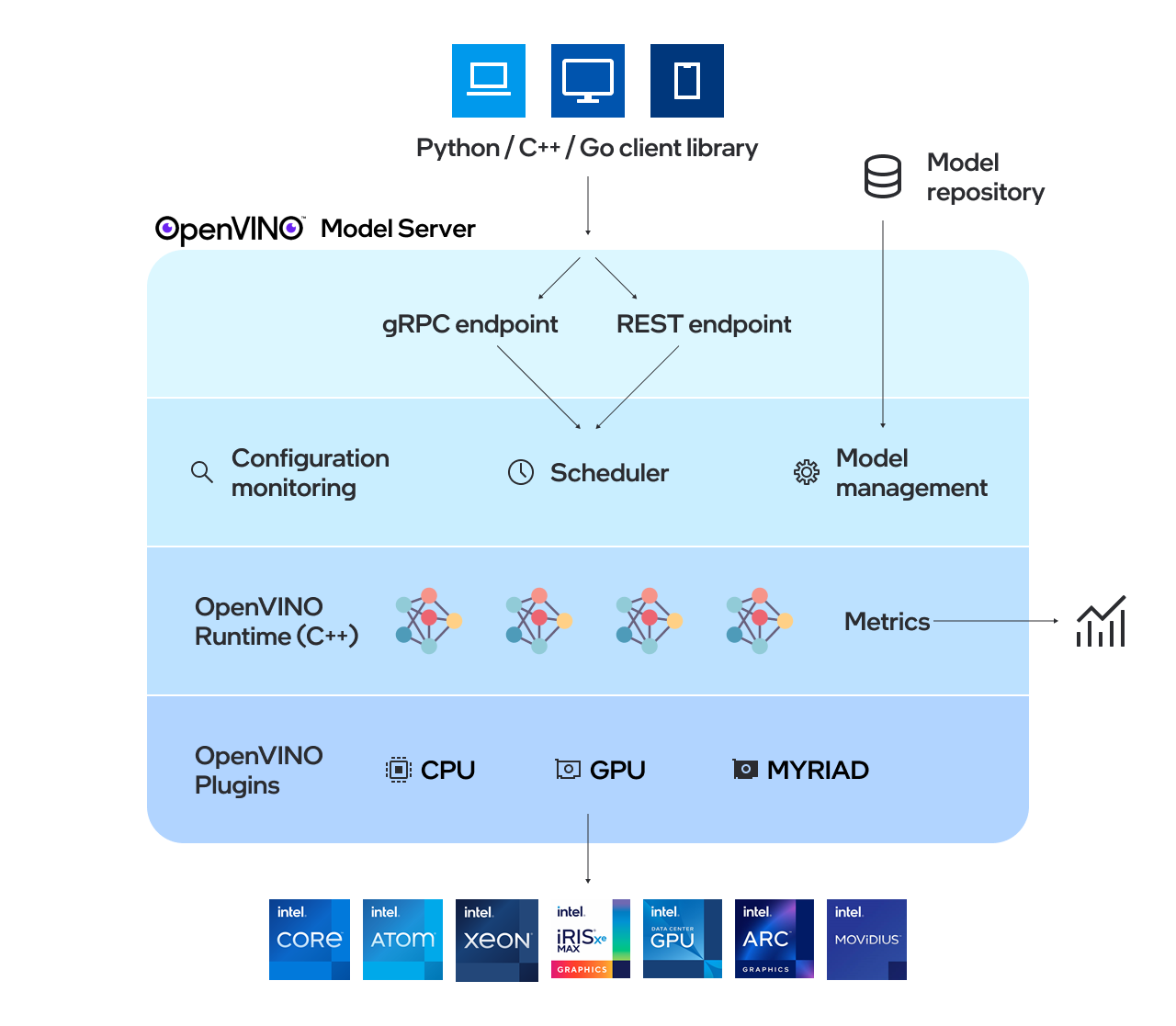
什么是 OpenVINO 模型服务器 (OVMS)?
![]()
- 种用于为模型提供服务的高性能系统。该模型服务器使用 C++ 实现以实现可扩展性,并针对在 Intel 架构上的部署进行了优化,在应用 OpenVINO 执行推理时。推理服务通过 gRPC 或 REST API 提供
- OpenVINO 模型服务器可以使用 OpenVINO IR、ONNX、PaddlePaddle 或 TensorFlow 格式的预训练模型执行推理,以下是执行步骤
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20#1-准备 Docker
docker run hello-world #确保docker安装成功
#2-下载 OpenVINO™ 模型服务器
docker pull openvino/model_server:latest
#3-提供模型
mkdir -p model/1
wget https://www.kaggle.com/api/v1/models/tensorflow/faster-rcnn-resnet-v1/tensorFlow2/faster-rcnn-resnet50-v1-640x640/1/download -O 1.tar.gz
tar xzf 1.tar.gz -C model/1
#4-启动 Model Server 容器
docker run -d -u $(id -u) --rm -v ${PWD}/model:/model -p 9000:9000 openvino/model_server:latest --model_name faster_rcnn --model_path /model --port 9000
#5-准备示例客户端组件
wget https://raw.githubusercontent.com/openvinotoolkit/model_server/releases/2024/4/demos/object_detection/python/object_detection.py
wget https://raw.githubusercontent.com/openvinotoolkit/model_server/releases/2024/4/demos/object_detection/python/requirements.txt
wget https://raw.githubusercontent.com/openvinotoolkit/open_model_zoo/master/data/dataset_classes/coco_91cl.txt
#6-下载数据进行推理
wget https://storage.openvinotoolkit.org/repositories/openvino_notebooks/data/data/image/coco_bike.jpg
#7-运行推理
pip install --upgrade pip
pip install -r requirements.txt
python3 object_detection.py --image coco_bike.jpg --output output.jpg --service_url localhost:9000
参考: