LoRA:Low-Rank Adaptation of Large Language Models
什么是 LoRA ?
![]()
- 一种在预训练语言模型(PLM)旁边增加旁路进行微调的技术,通过低秩(LOW-RANK)自适应(LoRA) 的概念,将可训练的秩分解矩阵注入 Transformer 架构的每一层,从而大大减少了下游任务的可训练参数数量
- 与用 Adam 微调的 GPT-3175B 相比,LoRA 可以将可训练参数的数量减少 10000 倍,GPU 内存需求减少 3 倍
- LoRA 的优势在于它可以在不改变原始 PLM 结构的情况下,通过少量的额外参数来实现对模型的微调,一是可以大大减少微调过程中的计算成本和内存占用,二是能提高模型在特定任务上的性能。比如:训练一个基础的大模型,通过加载不同的 LoRA 微调权重,可以将大模型应用到不同领域
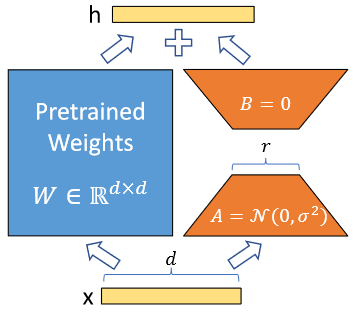
LoRA 的原理?
- 旁路结构:在原始的预训练语言模型(PLM)基础上,增加一个旁路结构,该旁路通过降维和升维操作来模拟所谓的 intrinsic rank,假设权重更新的过程中也有一个较低的本征秩,对于预训练的权重参数矩阵 ,使用低秩分解来表示其更新
- 参数固定:在微调过程中,保持原始 PLM 的参数 不变,只训练新增的降维矩阵 A 和升维矩阵 B,因此 LoRA 的前向传递函数为:$$h=W_0x+\Delta Wx=W_0x+BAx$$
- 初始化策略:使用随机高斯分布初始化降维矩阵 A,而升维矩阵 B 则用 0 矩阵初始化,使用 Adam 进行优化,确保在训练开始时此旁路不影响模型的输出
- 参数更新:在微调过程中,通过更新降维矩阵 A 和升维矩阵 B 来适应下游任务,而不是直接修改 PLM 的原有参数,正常使用 进行计算,不会带来额外的延迟。减去 BA 就是原来的预训练
LoRA 的步骤?
- 旁路添加:在 PLM 的每一层中,特别是 Self-Attention 部分,添加降维和升维的旁路结构
- 参数选择:确定哪些层的参数需要进行 LoRA 微调。对于基于 Transformer 结构的模型,通常只对 Self-Attention 的部分进行微调
- Rank 设置:选择合适的 Rank(r),即降维后的维度大小。研究表明,Rank 在 4-8 之间时效果最佳,但对于更广泛的指令微调任务,可能需要选择更高的 Rank 值
- 微调过程:在微调过程中,通过后向传播算法更新降维矩阵 A 和升维矩阵 B,以最小化下游任务的损失函数
- 模型输出:在模型输出时,将经过旁路矩阵变换的结果与 PLM 的原始参数叠加,形成最终的模型输出
LoRA 的低秩权重对不同权重的影响?
![]()
- 将所有参数设置为∆Wq 或∆Wk 会显著降低性能,而调整 Wq 和 Wv 会产生最佳结果。这表明,即使是 rank=4 也能捕获∆W 中的足够信息,因此,与采用更大 rank 的单一类型权重相比,更适合采用更多权重矩阵

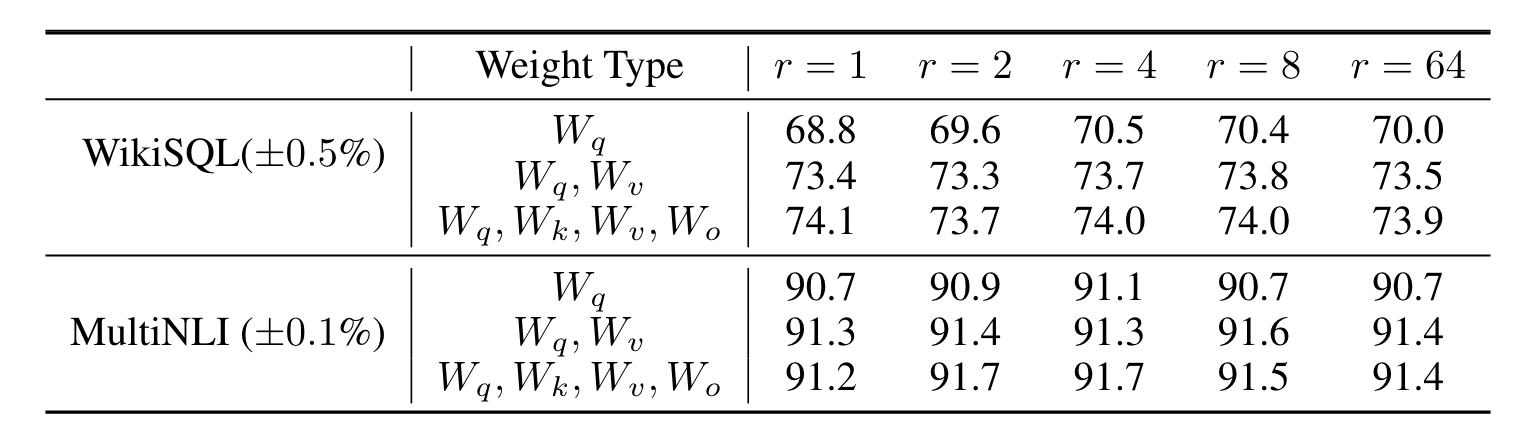
LoRA 的最佳秩 (rank)?
![]()
- 对相同层进行不同 rank 的低秩分解,其效果差别不大
- 但是令人惊讶的是,LoRA 已经以非常小的 r 表现出了竞争力,这表明更新矩阵∆W 可能具有非常小的 “内在秩”
参考: