RAG 演进 05-AgenticRAG
本文用于记录学习 AgenticRAG 的过程
RAG 的标准过程是 “索引 - 检索 - 生成”,他们的影响关系如下:
- 索引的目的是为了更好的检索
- 检索的目的是为了提供更好的上下文
- 基于更好的上下文,产生更高质量的回答
在 RAG 发展的不同阶段,对以上 3 个过程进行改进或扩展,到 Agentic RAG 为止,其技术演进思路如下:
| 范式 | 关键特征 | 优势 | 优化 |
|---|---|---|---|
| Naive RAG | 基于关键词的检索 (如 TFIDF、BM25) | 适合事实性查询 | - |
| Advanced RAG | 密集检索模型 (如 DPR) 神经排序和重排序模型 多跳检索 | 提高上下文相关性 | 索引、检索 |
| Modular RAG | 混合检索 (稀疏 + 密集) 工具或 API 集成 可组合流水线 | 高度灵活和定制性 可扩展 | 索引、检索、生成 |
| Graph RAG | 图结构数据集成 多跳响应 通过节点丰富上下文 | 关系推理能力 减少幻觉 适合结构化数据任务 | 索引、检索、生成 |
| Agentic RAG | 自主智能体 动态决策 迭代优化与工作流调整 | 适应实时变化 高可扩展性 适合多模态任务 | 生成 |
RAG 演进历史
Naive RAG

Naive RAG 是 RAG 的基础实现,侧重于关键词检索技术,如 TFIDF,BM25 等传统检索技术,从静态数据集中获取上下文,然后生成输出
缺点
- 缺乏上下文感知 :由于依赖关键词匹配,导致无法捕捉查询的语义细微差别
- 输出碎片化 :缺乏高级预处理或上下文集成,导致生成的响应可能不连贯或过于通用。
- 可扩展性问题 :基于关键词的检索技术,无法处理大规模数据集
Advanced RAG

针对 Naive RAG 的缺点,Advanced RAG 着重提升检索阶段的质量,包括以下改进:
- 密集向量搜索:查询和文档在高维空间表示,实现了用户查询和检索文档之间的更好 语义对齐
- 上下文重排:神经模型重新排序检索到的文档,优先考虑最上下文相关的信
- 迭代检索:Advanced RAG 引入了多跳检索机制,能够对复杂查询进行跨多个文档的推理
Modular RAG
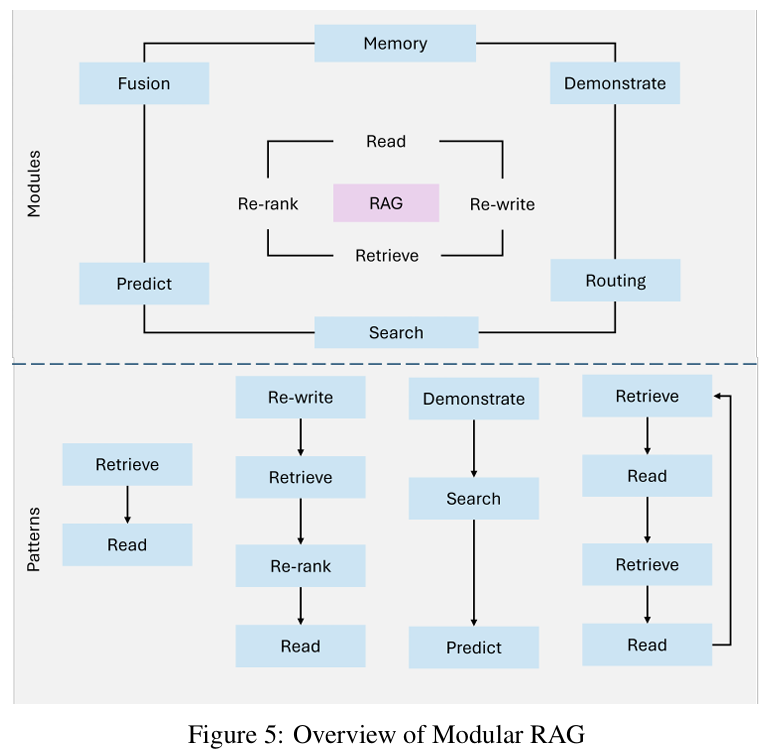
Modular RAG 在灵活性和定制化方向,扩展 RAG 的应用,将 RAG 的关键过程(如:检索、生成、路由) 整合成独立的组件,方便复用,它有以下优势:
- 混合检索策略 :结合稀疏和密集检索方法,以最大化不同查询类型的准确性。
- 工具集成 :整合外部 API、数据库或计算工具来处理专业任务,例如实时数据分析或特定领域的计算。
- 可组合管道 :允许独立替换、增强或重新配置检索器、生成器和其他组件。
Graph RAG
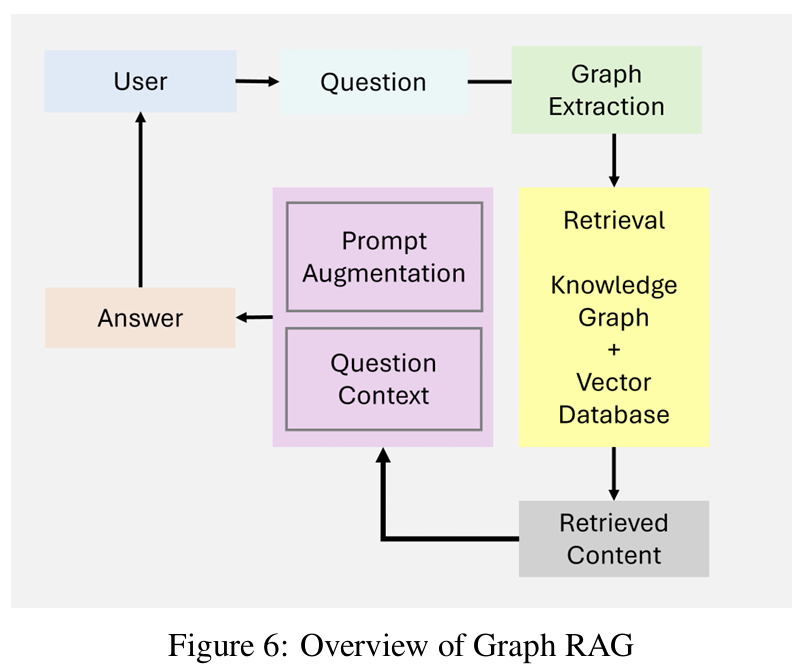
通过对 “全局文档” 构建知识图谱,实现对多跳、复杂推理的进一步提升,本质上是重构数据的索引方式,有原来片段式的索引,变为全局实体及关系的索引
GraphRAG 的特点:
- 节点连接:捕获和响应不同推理实体之间的关系
- 分层知识管理:通过图形化的结构处理结构化和非结构化数据
- 上下文扩充:基于图形化的路径增加关系的理解
GraphRAG 存在以下局限性:
- 扩展限制:图结构化数据限制其扩展性,尤其是使用大量数据源的情况下,知识图谱更新将变得困难
- 数据依赖:需要构建高质量的知识图谱,在非结构化数据或者缺少注释的数据上难以做到
- 集成的复杂性:检索图形化数据、非结构化数据,其集成将使得系统变得复杂
Agentic RAG
Agentic RAG 通过引入动态决策和流程化的自主代理,实现 “静态系统” 到 “动态系统” 的转换,可以进行迭代优化和自适应检索策略处理复杂问题
Agentic RAG 的主要特征包括:
- 自主决策:根据查询的复杂性,自主评估和管理检索策略
- 迭代优化:整合反馈循环,提高检索的准确性和响应相关性
- 工作流优化:动态编排任务,提高实时应用程序的效率
Agentic RAG 存在以下调挑战:
- 协调复杂性:管理代理之间的交互需要复杂的编排机制
- 计算开销:使用多个代理会增加复杂工作所需的资源
- 可扩展性限制:虽然可扩展,但系统的动态特性可能会使高查询量的计算资源紧张
Agentic RAG 详解
Agent 的组成及能力

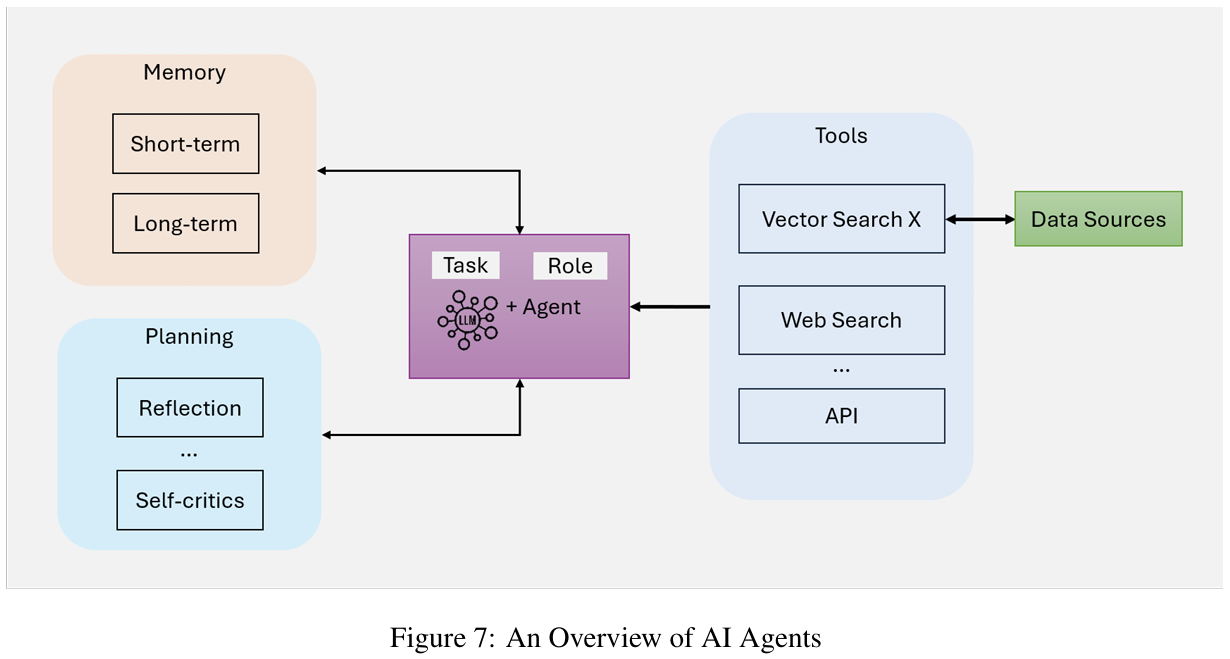
Agent 的组成
- LLM (定义角色和任务):作为 Agent 的主要推理引擎,它解释用户查询、生成响应
- Memory (短期和长期):捕获上下文相关的数据,短期记忆追踪对话状态,长期记忆积累知识和代理体验
- Planning (反思和自我批评):通过反思和自我评判,指导代理迭代过程,确保复杂任务被分解
- Tool (工具):将代理功能扩展到文本生成之外,支持访问外部资源,使用外部工具
支撑 Agent 动态地构建工作流的模式有四种:
1. 反思 (Reflection)

代理工作流中的基本模式,通过评估去迭代优化输出,评估指标包括输出的正确性、风格等
在多智能体系统中,反射可能涉及不同的角色,例如一个智能体生成输出,而另一个智能体批评输出,从而促进协作改进。
2. 规划 (Planning)

规划是另一种代理设计模式,它使代理能够自主将复杂任务分解为更小、可管理的子任务,但是与 Reflection 相比, Planning 产生的结果更难预测,因为子任务相互依赖,后续子任务的质量依赖前序子任务的完成质量
3. 工具使用 (Tool use)
工具使用是代理的另一种工作流,它允许代理调用外部工具、API,提供更准确的上下文
4. 多代理 (Multi-Agent)

多代理是代理工作流的一种关键模式,它支持任务专业化和并行处理。代理之间可以共享数据、相互指派任务,每个代理内部有自己的记忆、工具、反思和规划,从而实现动态和协作地解决问题
Agentic RAG 分类
Single-Agent Agentic RAG: Router

有单一的 Agent 管理检索、路由和整合的过程,简化了系统设计,但是工具或者数据源的数量有限,因为单一的 Agent 无法使用大量的工具
工作流程:
- 查询提交与评估:代理分析查询,分析确定合适的数据源
- 数据源选择:
- 结构化数据:对于需要表格访问的查询,需要将查询转为 SQL 处理
- 语义搜索:处理非结构化数据时,基于向量检索即可
- 网络搜索:对于实时或者广泛上下文,系统利用互联网工具访问最新在线数据
- 推荐系统:对于个性化或上下文查询,利用推荐引擎提供定制化建议
- 数据集成及生成:将检索到的数据集成到 prompt 中,然后交给 llm 生成
Multi-Agent Agentic RAG Systems

由于一个代理绑定的工具有限,那么在 Single-Agent Agentic RAG 的基础上增加多个代理,用于负责不同工具的调用,降低每个 agent 的 prompt 复杂程度
工作流程:
- 查询提交与评估:代理分析查询,分析确定合适的代理
- 代理源:
- 代理 X:负责向量化检索
- 代理 Y:负责网络搜索
- 代理 Z:负责检索邮件或者聊天
- 将检测的数据整合进 prompt,
Hierarchical Agentic RAG Systems

相比较 Multi-Agent Agentic RAG,Hierarchical Agentic RAG 采取多层次的方法构建 Agent,高级代理监督指导低级代理
工作流程:
- 接受查询,委派代理:用户输入查询,通过主代理分析,并将任务委派到子代理,可以委派多个代理
- 子代理执行:子代理执行,并将结果返回给主代理,可以有多个子代理同时执行
- 生成:主代理接收汇总所有子代理的结果,然后生成回答
Agentic Corrective RAG

通过引入自我纠正机制,迭代细化上下文文档和回答,最小化错误并最大化相关性。这个方法是通过以下 3 个代理完成:
- 上下文检索代理:负责从向量库中检索上下文
- 相关性评估代理:评估检索到文档的相关性,过滤或纠正对于标记不相关的文档
- 查询细化代理:利用语义理解来优化检索,以获得更好上下文
- 外部知识代理:当上下文不足时,通过网络搜索补充知识
- 回答合成代理:将经过验证的代理整合生成连贯且准确的回答
Adaptive Agentic RAG

根据查询的复杂性调整处理策略,然后选择合适的方法回答问题,范围从单步推理到多步推理,甚至对于简单回答直接回答,而不需检索
Adaptive Agentic RAG 的核心在于根据查询复杂性动态调整检索策略,比如以下检索:
- 直接查询:对于不需要额外检索的基于事实的问题(例如,“水的沸点是多少?”),系统使用预先存在的知识直接生成答案。
- 简单查询:对于需要最少上下文的中等复杂任务(例如,“我的最新电费单的状态如何?”),系统会执行单步检索以获取相关详细信息。
- 复杂查询:对于需要迭代推理的多层查询(例如,“过去十年 X 市的人口变化如何,影响因素是什么?”),系统采用多步骤检索,逐步提炼中间结果以提供全面的答案
Adaptive Agentic RAG 有以下 3 个核心组件组成
- 分类角色:一个小的 llm 模型,用于分析用户输入复杂性,分类器使用从过去模型结果和查询模式派生的自动标注数据训练
- 动态策略选择:直接查询,使用 llm 回答即可;简单查询,单步检索即可;复杂查询,使用多步检索,迭代细化结果
- LLM 整合:整合检索到的信息,生成回答
Graph-Based Agentic RAG
Agent-G: Agentic Framework for Graph RAG
![[Pasted image 20250214135237.png]]
Agent-G 将图知识库和非结构化的检索相结合,通过结构化的知识图谱和非结构化化数据增强 RAG 的上下文能力,在设计上还使用评估模块,确保可以不断迭代细化,产生高质量输出
工作流程:
- 知识图谱:使用结构化的数据在全文层次提取实体、关系
- 非结构化数据:使用向量检索检索相关文档
- 评估模块:评估检索到信息的相关性和质量,确保与查询一致
- 反馈循环:通过迭代验证和重新查询细化检索和合成
GeAR:Graph-EnhancedAgentforRetrieval-AugmentedGeneration

通过整合基于图的检索机制来增强传统的 RAG 系统。通过利用图扩展技术和基于代理的架构,GeAR 解决了多跳检索场景中的挑战,提高了系统处理复杂查询的能力
- 增强的多跳检索:GeAR 的图形扩展允许系统处理需要对多个互连信息进行推理的复杂查询。
- 代理决策:代理框架支持动态和自主选择检索策略,从而提高效率和相关性。
- 提高准确性:通过整合结构化图形数据,GeAR 提高了检索信息的精度,从而产生更准确和上下文合适的响应。
- 可扩展性:代理框架的模块化特性允许根据需要集成其他检索策略和数据源。
Agentic Document Workflows in Agentic RAG

智能体文档工作流(Agentic Document Workflows, ADW)整合文档解析、检索、推理和结构化输出与智能代理。通过维护状态、协调多步工作流,并将领域特定逻辑应用于文档,解决了智能文档处理(IDP)和 RAG 的限制
工作流程:
- 文档解析和信息结构化:使用企业级工具(例如 LlamaParse)解析文档,提取相关数据字段,如发票号码、日期、供应商信息、明细项和付款条款
- 跨流程的状态维护: 系统维护文档上下文的状态,确保多步工作流之间的一致性和相关性
- 知识检索:从外部知识库或向量索引中检索相关参考文献
- 代理协调:智能代理应用业务规则,执行多跳推理,并生成可操作的建议
- 可操作输出生成:以结构化格式呈现输出,针对特定用例进行定制
Agentic RAG 框架比较
| 特征 | 传统 RAG | Agentic RAG | 代理文档工作流(ADW) |
|---|---|---|---|
| 聚焦 | 孤立的检索和生成任务 | 多代理协作和推理 | 以文档为中心的端到端工作流 |
| 上下文维护 | 有限的 | 通过记忆模块实现 | 在多步骤工作流中保持状态 |
| 动态适应性 | 最小的 | 高 | 针对文档工作流定制 |
| 工作流编排 | 无 | 协调多代理任务 | 集成多步骤文档处理 |
| 外部工具 / API 的使用 | 基本集成(例如,检索工具) | 通过工具如 API 和知识库扩展 | 深度集成业务规则和特定领域的工具 |
| 可扩展性 | 限制在小型数据集或查询 | 多代理系统可扩展 | 适用于多领域企业工作流的扩展 |
| 复杂推理 | 基本的(例如,简单的问答) | 与代理进行多步骤推理 | 在文档间进行结构化推理 |
| 主要应用 | 问答系统,知识检索 | 多领域知识和推理 | 合同审查、发票处理、索赔分析 |
| 优势 | 简单,快速设置 | 高准确性,协作推理 | 端到端自动化,领域特定智能 |
| 挑战 | 较差的上下文理解 | 协调复杂性 | 资源开销,领域标准化 |
Agentic RAG 的出现,意味着 RAG 和 Agent 结合迈向下一步,扩展了 RAG 解决复杂查询的能力,如果 llm 没有进一步发展,可以试想这个架构将统治 RAG 很长一段时间。