基于 llamaindex 探究 graphrag 原理
本文利用 llamaindex 的 KnowledgeGraphIndex 非结构化文档的知识图谱,并使用该知识图谱回答问题
环境设置
设置推理模型及 embedding 模型
1 | from llama_index.core import Settings |
构建知识图谱
首先,使用 SimpleDirectoryReaderd 读取非结构化文档
1 | # 1.自定义documents |
其次利用 KnowledgeGraphIndex 在全局知识层面构建知识图谱 (也就是索引)
1 | from llama_index.core import SimpleDirectoryReader,StorageContext, KnowledgeGraphIndex |
Parsing nodes: 0%| | 0/3 [00:00<?, ?it/s]
Processing nodes: 0%| | 0/3 [00:00<?, ?it/s]
最后,使用 pyvis 工具查看知识图谱的内容
1 | show_knowledge_graph(index,name='example.html') |
由可视化结果看出,使用 llm 构建的知识图谱,将中文名改为了英文,而且感觉图谱质量不高。
实际上,知识图谱的构建本质是 N 个三元组 (实体 1,实体 2,关系) 组成,所以也可以直接向索引对象添加三元组,实现 “手动” 知识图谱的构建
1 | # 2.文档chunk化 |
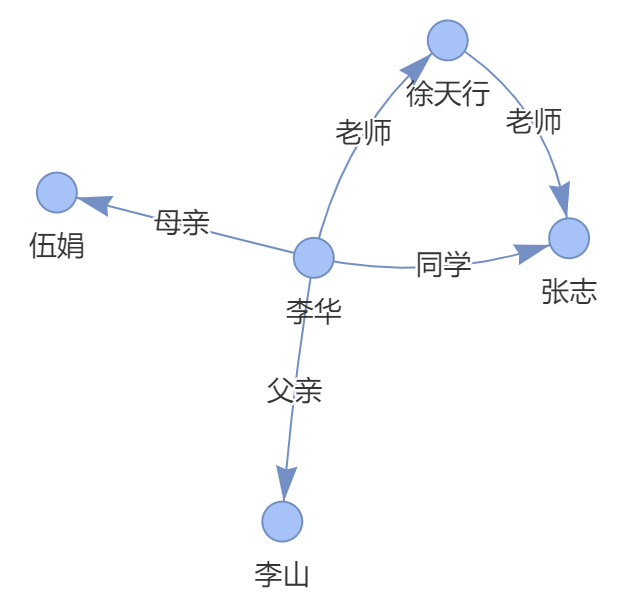
使用知识图谱
1 | # 直接使用索引,分析文本中的三元组 |
[('李华', '去', '徐天行老师家'), ('王五', '去', '徐天行老师家'), ('补课', '发生在', '徐天行老师家')]
1 | # 索引->检索器 |
1 | [NodeWithScore(node=TextNode(id_='d38689d8-a7c2-41f8-a8de-d79c84bc4034', embedding=None, metadata={}, excluded_embed_metadata_keys=[], excluded_llm_metadata_keys=[], relationships={<NodeRelationship.SOURCE: '1'>: RelatedNodeInfo(node_id='97ee7e69-7ebf-4343-a587-8ee10e281cae', node_type='4', metadata={}, hash='96f4e9c8f81325976a25213572d9255024347d55bce55e980bc6d1ec03bd33f7')}, metadata_template='{key}: {value}', metadata_separator='\n', text='徐天行举着李华的作业本:“横平竖直,一夜进步神速!”原来李华熬夜练习书法,只因徐老师曾说“字如心正”。', mimetype='text/plain', start_char_idx=0, end_char_idx=51, metadata_seperator='\n', text_template='{metadata_str}\n\n{content}'), score=1000.0), |
1 | # 索引->RAG引擎 |
徐天行对李华的书法进步给予了积极评价,说他的字 “横平竖直,一夜进步神速”。至于张志的情况,文中并未提及具体课程作业的评价信息。
后面两个应用中,可以发现知识图谱并没有准确检索到文档,或者准确回答问题,这是因为只使用了 “实体(关键字)” 去知识图谱检索文档,下面我们在知识图谱的基础上添加文档的整体语义信息,检索时,同时考虑实体及语义,看看其检索与回答效果
1 | index = KnowledgeGraphIndex( |
1 | [NodeWithScore(node=TextNode(id_='d38689d8-a7c2-41f8-a8de-d79c84bc4034', embedding=None, metadata={}, excluded_embed_metadata_keys=[], excluded_llm_metadata_keys=[], relationships={<NodeRelationship.SOURCE: '1'>: RelatedNodeInfo(node_id='97ee7e69-7ebf-4343-a587-8ee10e281cae', node_type='4', metadata={}, hash='96f4e9c8f81325976a25213572d9255024347d55bce55e980bc6d1ec03bd33f7')}, metadata_template='{key}: {value}', metadata_separator='\n', text='徐天行举着李华的作业本:“横平竖直,一夜进步神速!”原来李华熬夜练习书法,只因徐老师曾说“字如心正”。', mimetype='text/plain', start_char_idx=0, end_char_idx=51, metadata_seperator='\n', text_template='{metadata_str}\n\n{content}'), score=1000.0), |
1 | # 索引->RAG引擎 |
根据新提供的信息,我们仍然没有关于老师对李华和张志生物课程作业的具体评价。文中仅描述了徐天行是张志的老师以及与李华相关的一些家庭成员关系,并未提及任何有关生物课程作业的内容。因此,无法回答关于他们的生物课程作业情况。
可以发现,检测、回答效果并没有改善,看来 GraphRAG 并不是在所有场景有效,或者是其效果依赖于知识图谱的质量,在本脚本中,知识图谱太小,使用受限
构建知识图谱的原理
知识图谱的目的是使用 llm 提取文本的三元组,我们首先来看看 llm 的相关 prompt
1 | from llama_index.core import KnowledgeGraphIndex |
PromptTemplate(metadata={‘prompt_type’: <PromptType.KNOWLEDGE_TRIPLET_EXTRACT: ‘knowledge_triplet_extract’>}, template_vars=[‘max_knowledge_triplets’, ‘text’], kwargs={‘max_knowledge_triplets’: 10}, output_parser=None, template_var_mappings=None, function_mappings=None, template=“Some text is provided below. Given the text, extract up to {max_knowledge_triplets} knowledge triplets in the form of (subject, predicate, object). Avoid stopwords.\n---------------------\nExample:Text: Alice is Bob’s mother.Triplets:\n(Alice, is mother of, Bob)\nText: Philz is a coffee shop founded in Berkeley in 1982.\nTriplets:\n(Philz, is, coffee shop)\n(Philz, founded in, Berkeley)\n(Philz, founded in, 1982)\n---------------------\nText: {text}\nTriplets:\n”)
其中 prompt 内容如下:
1 | Some text is provided below. Given the text, extract up to {max_knowledge_triplets} knowledge triplets in the form of (subject, predicate, object). Avoid stopwords.\n |
内容显示,要求 llm 提供数量为 max_knowledge_triplets 个的 (subject, predicate, object) s 三元组,并且给出提示例子
应用小例子
1 | from llama_index.core import SimpleDirectoryReader |
Loading files: 100%|██████████| 8/8 [00:00<00:00, 74.28file/s]
1 | from llama_index.core import StorageContext, KnowledgeGraphIndex |
Parsing nodes: 0%| | 0/8 [00:00<?, ?it/s]
Processing nodes: 0%| | 0/80 [00:00<?, ?it/s]
1 | query_engine = index.as_query_engine( |
董卓通过给予礼物的方式收买了吕布,将他收为了义子。根据信息,董卓用一匹名为 “赤兔马” 的千里马和数不尽的黄金珠宝作为礼物送给了吕布,成功地让他拜自己为义父。
1 | query_engine = index.as_query_engine( |
根据提供的信息,刘备最初是通过军事才能为朝廷效力的。在故事中提到,关羽和张飞在战场上英勇无敌,而刘备则既有勇又有谋,三人接连取胜,战功赫赫。但是,随着时间推移,朝廷变得更加腐败,实行卖官鬻爵的行为。尽管如此,刘备并未放弃为国家贡献力量的机会,在担任安喜县县尉期间,他与百姓秋毫无犯,深得民心,展现了其忠于职守的一面。
总结:本文使用 llamaindex 学习了知识图谱的构建,并基于知识图谱创建 RAG 应用,发现 GraphRAG 的回答质量不是在所有场景适用,而是依赖于高质量的知识图谱