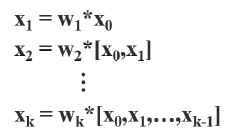DenseNet:Densely Connected Convolutional Networks
通过设计更加激进的跨连接,实现大量的重复梯度传递,因此可以使用较少的参数实现较快的收敛
什么是 DenseNet ?
![DenseNet-20230408135926]()
- 实践证明,ResNet 只有少数的残差块参与学习,随机丢掉某些层可以提升 ResNet 的泛化能力,带来两点启发:1)网络表现得像个整体,某一层可以不仅仅依赖前一层;2)每层提取的特征不是非必要的,说明其他大部分特征比较冗余。基于以上两点 DenseNet 提出让网络的每一层和前面的所有层相连,同时把每一层设计地特别窄,学习很少的特征图以此降低冗余性
- 密集连接机制有 2 个好处:1)梯度可以传递更远:不会因为网络深而出现梯度消失的问题;2)特征更集中:通过降低 block 的输出通道数,降低冗余的可能
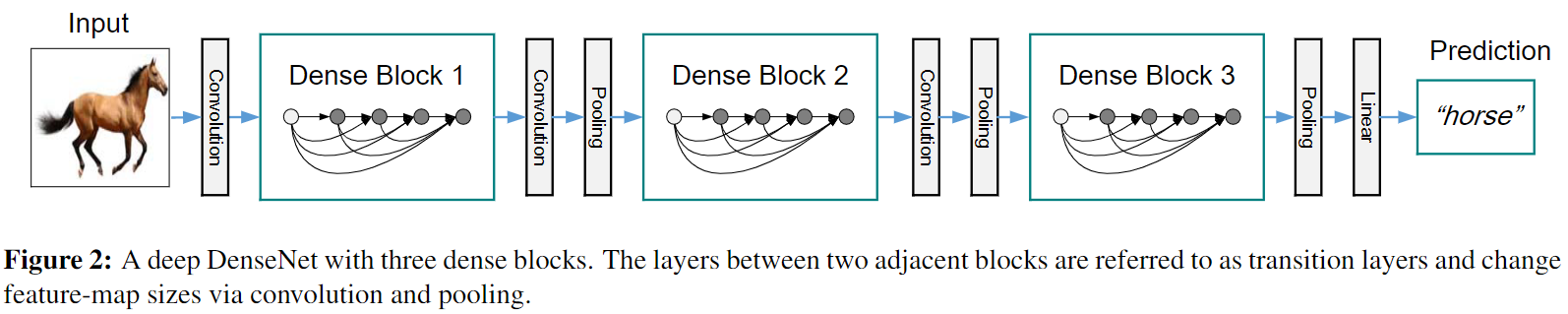
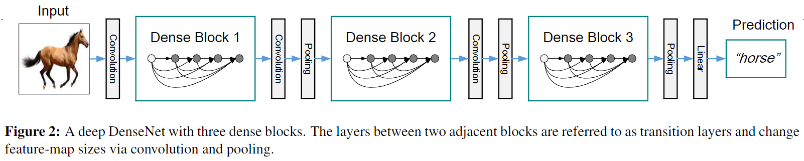
DensNet 的网络结构?
![DenseNet-20230408135926-1]()
- 每个阶段都包含 1 个 DenseBlock 和 1 个 Transition 组成,每个 DenseBlock 由 K 个 dense layer 组成,Transition 负责串联两个 DenseBlock
- 最后的 DenseBlock 之后是一个 global AvgPooling 层,然后送入一个 softmax 分类器
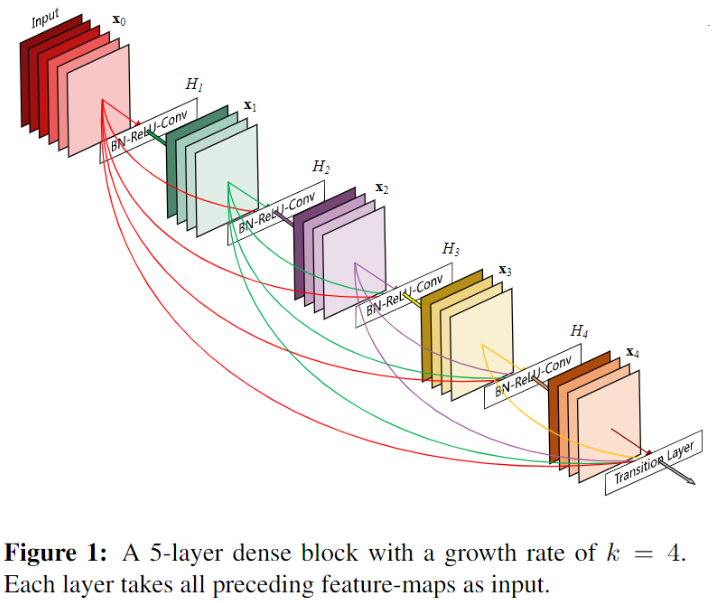
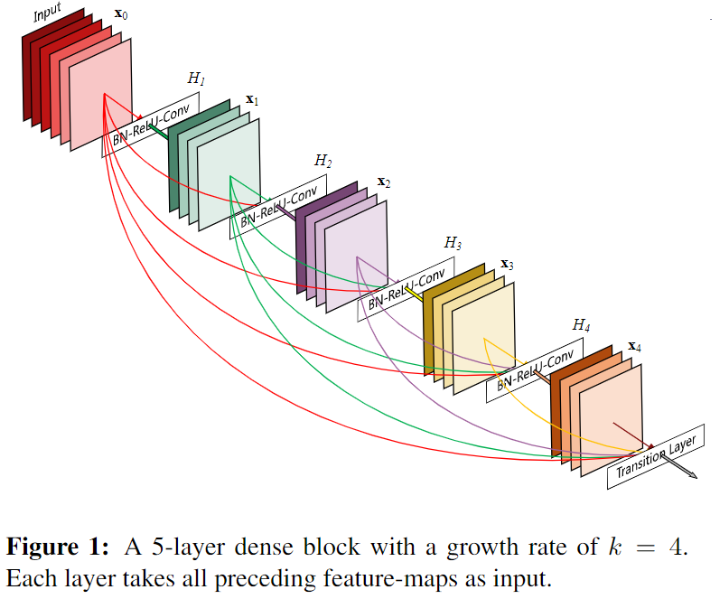
DensNet 网络结构的 DenseBlock 部分?
- DenseBlock 内各个层的特征图大小一致,因此可以在 channel 维度上连接
![DenseNet-20230408135927]()
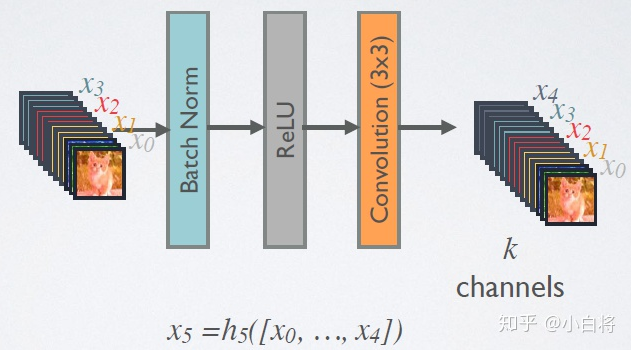
- 每个卷积块输出 k 通道特征: 所有 DenseBlock 中各个层卷积之后均输出 个特征图,这是 DenseNet 的 Growth rate ,假定输入层的特征图的 channel 数为 , 那么 l 层的输入特征图为 , 因此随着层数增加,尽管 设定得较小,DenseBlock 的输入会非常多,不过这是由于特征重用所造成的
![]()
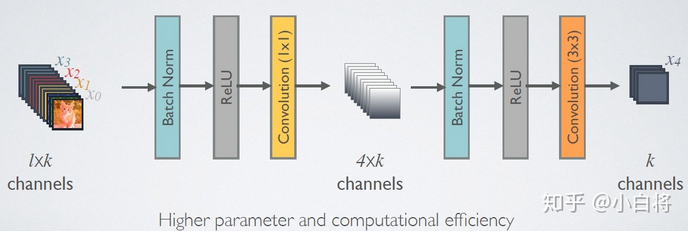
- 由于后面层的输入会非常大,DenseBlock 内部可以采用 bottleneck 层来减少计算量,主要是原有的结构中增加 1x1 Conv
![]()
DensNet 网络结构的 Transition 部分?
![DenseNet-20230408135926-1]()
- 负责连接两个相邻的 DenseBlock,结构为 BN+ReLU+1x1 Conv+2x2 AvgPooling, 同时具有降低特征图大小及压缩模型的作用
- 降低特征图大小: 使用 2x2 AvgPooling 减小特征图
- 压缩模型: 假定 Transition 的上接 DenseBlock 得到的特征图 channels 数为 Transition 层可以产生 个特征图,其中 是压缩系数。当 时,特征个数经过 Transition 层没有变化,即无压缩,而当压缩系数小于 1 时被压缩
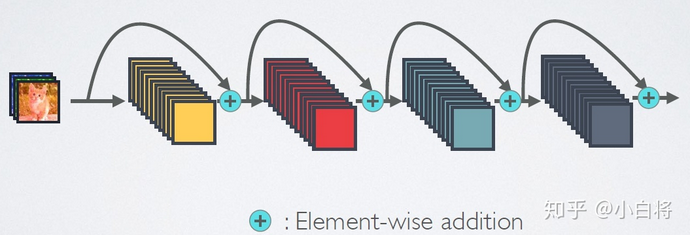
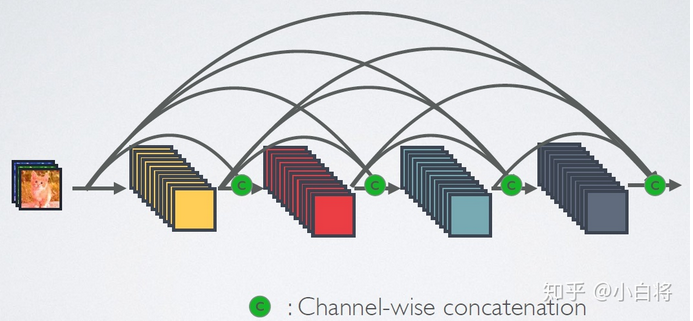
DensNet 与 ResNet 在网络结构上的差异?
- ResNet 连接示意图
![]()
- DensNet 连接示意图
![]()
- ResNet 的跨连接只在 ResNetBlock 上,没有跨更远;而 DensNet 的同一 DenseBlock 内每个卷积层接受前面所有卷积层 k 个特征图输入
- ResNet 跨连接后的融合操作是 “加法”,DensNet 是 **“拼接”
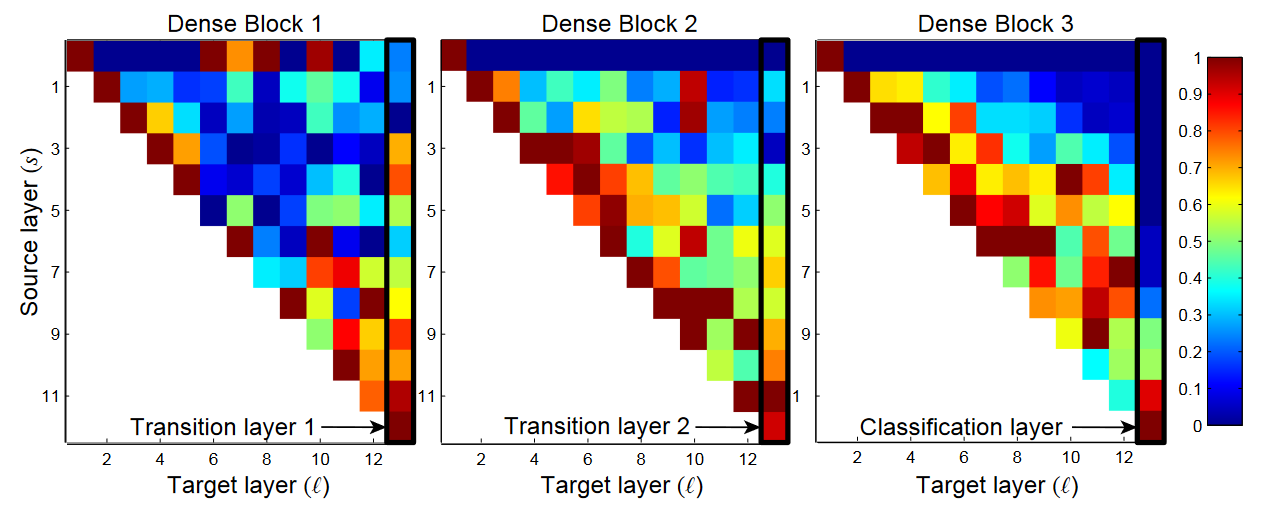
如何理解 DensNet 的 Feature Reuse (特征重用)?
![]()
- 作者训练的 L=40,K=12 的 DenseNet, 对于任意 Denseblock 中的所有卷积层,计算之前某层 feature map 在该层权重的绝对值平均数,这一平均数表明了这一层对于之前某一层 feature 的利用率,下图为由该平均数绘制出的热力图 ,红色表示 strong use,蓝色表示 almost no use,横坐标是选定层,纵坐标为选定层的之前层,最右侧以及第一行 为 Transition 层
- a) 一些较早层提取出的特征仍可能被较深层直接使用
- b) 即使是 Transition layer 也会使用到之前 Denseblock 中所有层的特征
- c) 第 2-3 个 Denseblock 中的层对之前 Transition layer 利用率很低,说明 transition layer 输出大量冗余特,证明 Compression 的必要性
- d) 最后的分类层虽然使用了之前 Denseblock 中的多层信息,但更偏向于使用最后几个 feature map 的特征,说明在网络的最后几层,某些 high-level 的特征可能被产生
DenseNet 特别耗费显存吗?
- DenseNet 在训练时对内存消耗非常厉害这个问题,其实是算法实现不优带来的,对于大多数框架(如 Torch 和 TensorFlow),每次拼接操作都会开辟新的内存来保存拼接后的特征。这样就导致一个 L 层的网络,要消耗相当于 L (L+1)/2 层网络的内存(第 l 层的输出在内存里被存了 (L-l+1) 份)
- 解决这个问题的思路其实并不难,我们只需要预先分配一块缓存,供网络中所有的拼接层(Concatenation Layer)共享使用,这样 DenseNet 对内存的消耗便从平方级别降到了线性级别。在梯度反传过程中,我们再把相应卷积层的输出复制到该缓存,就可以重构每一层的输入特征,进而计算梯度
ResNet 和 DensNet 如何进行反向传播?
![]()
![]()
- cat 为运算算子,cat=concate, 将两个张量按照维度拼接起来,W cat 1 是在 W 上按照的 shape 的 1 全部 concate 到 W 上
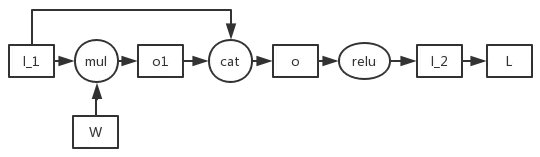
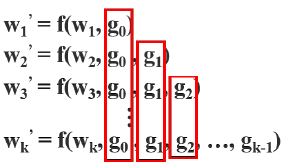
DenseNet 的梯度传播特点?
- 前馈传递和权重更新方程:在 DenseNet 中,第 i 个密集层的输出将与第 i 个密集层的输入连接
![DensNet-20230408140018-2]()
- 前馈传递和权重更新方程为
![]()
![]()
- 大量梯度信息被重新用于更新不同密集层的权重。这将导致不同的密集层反复学习复制的梯度信息