机器学习的模型选择与评估
本文主要解决如何选择更好的模型问题,通常办法是交叉验证,文章最后也介绍了参数搜索的办法
在机器学习中,模型的选择指的是?如何进行模型选择?
- 模型选择:就是算法模型及模型参数的选择
- 如何进行模型选择:K 折交叉验证
机器学习中模型参数和超参的区别?超参给定的方式有那些?
- 模型参数:模型内部的配置变量,可以用数据估计模型参数的值
- 模型超参:是模型外部的配置,必须手动设置参数的值,可以通过网格参数搜索 (GridSearchCV) 来取值,也可以通过经验选定
什么是训练集 (training set)?
- 数据集的子集,用于训练模型
什么是测试集 (testing set)?
- 数据集的子集,用于在模型经由验证集的初步验证之后测试模型。与训练集和验证集相对
- 与训练集 (training set) 相对
什么是验证集 (validation set)?
- 数据集的一个子集,从训练集分离而来,用于调整超参数
在机器学习中,样本划分的原则?
- 在样本量有限的情况下,有时候会把验证集和测试集合并。实际中,若划分为三类,那么训练集:验证集:测试集 = 6:2:2;若是两类,则训练集:验证集 = 7:3。这里需要主要在数据量不够多的情况,验证集和测试集需要占的数据比例比较多,以充分了解模型的泛化性
- 海量样本的情况下,这种情况在目前深度学习中会比较常见。此时由于数据量巨大,我们不需要将过多的数据用于验证和测试集。例如拥有 1 百万样本时,我们按训练集:验证集:测试集 = 98:1:1 的比例划分,1% 的验证和 1% 的测试集都已经拥有了 1 万个样本。这已足够验证模型性能了
- 此外,三个数据集的划分不是一次就可以的,若调试过程中发现,三者得到的性能评价差异很大时,可以重新划分以确定是数据集划分的问题导致还是由模型本身导致的。其次,若评价指标发生变化,而导致模型性能差异在三者上很大时,同样可重新划分确认排除数据问题,以方便进一步的优化
sklern 中,如何快速进行数据集划分?
- train_test_split 在 scikit-learn 中,可以使用辅助函数快速计算随机分成训练集 (training set) 和测试集 (testing set)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16>>> import numpy as np
>>> from sklearn.model_selection import train_test_split
>>> from sklearn import datasets
>>> from sklearn import svm
>>> X, y = datasets.load_iris(return_X_y=True)
>>> X.shape, y.shape
((150, 4), (150,))
>>> X_train, X_test, y_train, y_test = train_test_split(
... X, y, test_size=0.4, random_state=0)
>>> X_train.shape, y_train.shape
((90, 4), (90,))
>>> X_test.shape, y_test.shape
((60, 4), (60,))
>>> clf = svm.SVC(kernel='linear', C=1).fit(X_train, y_train)
>>> clf.score(X_test, y_test)
0.96... - 注意事项:1)训练集的比例要足够多,一般大于一半;2)训练集和测试集要均匀抽样
什么是交叉验证?
- 一种检验模型的效果的方法,可用于模型及其参数选择,具有一定的避免过拟合的能力
什么是自助法(Bootstrap)评估模型?
- 一种有放回的抽样,选择数据中的 63.2% 构建训练集,其余为测试集 (但改变了数据集的分布,会引入估计偏差)
交叉验证几种方法
- K 折交叉验证:一般取 5 折交叉验证或者 10 折交叉验证,重复做 p 次
- 留 P 法 (LPO) 法:简单地将原始数据集随机划分为训练集,验证集,测试集三个部分.
- 留一个 (LOO) 法:每次只留一个样本作为数据的测试集,其余作为训练集(只适用于较少的数据集)
什么是 K 折交叉验证?
- K 折交叉验证是将原始数据分成 K 组(一般是均分),将每个子集数据分别做一次验证集,其余的 K-1 组子集数据作为训练集,这样会得到 K 个模型,再用这 K 个模型最终的验证集的分类准确率的平均数,作为此 K 折交叉验证下分类器的性能指标
k 折交叉验证中 k 取值多少有什么关系
- 1)K=1,所以数据都被用于训练,模型很容易出现过拟合,因此容易是低偏差、高方差
- 2)K=1~n,可以理解为一种方差和偏差妥协的结果,2017 年的一项研究给出了另一种经验式的选择方法,作者建议 k=log (n) 且保证 n/K>3d ,n 代表了数据量,d 代表了特征数
- 3)K=n,随着 K 值的不断升高,单一模型评估时的方差逐渐加大而偏差减小。因此容易是高偏差、低方差
- K 值选择: K 一般大于等于 2,实际操作时一般从 3 开始取值,只有在原始数据集和数据量小的时候才会尝试取 2。K 折交叉验证可以有效地避免过学习及欠学习状态的发生,最后得到的结果也比较具有说服力。通常情况下,K 的取值为 3、5、10
- 使用交叉验证的根本原因是数据集太小,而较小的 K 值会导致可用于建模的数据量太小,所以小数据集的交叉验证结果需要格外注意。建议选择较大的 K 值,同时也要考虑较大 K 值的计算开销
sklern 中,如何进行交叉验证?
- 使用交叉验证最简单的方法是 cross_val_score 在估计器和数据集上调用辅助函数
1
2
3
4
5>>> from sklearn.model_selection import cross_val_score
>>> clf = svm.SVC(kernel='linear', C=1, random_state=42)
>>> scores = cross_val_score(clf, X, y, cv=5)
>>> scores
array([0.96..., 1. , 0.96..., 0.96..., 1. ])
sklern 中,如何进行多指标评估?
- 使用 cross_validate 函数
1
2
3
4
5
6
7
8
9>>> from sklearn.model_selection import cross_validate
>>> from sklearn.metrics import recall_score
>>> scoring = ['precision_macro', 'recall_macro']
>>> clf = svm.SVC(kernel='linear', C=1, random_state=0)
>>> scores = cross_validate(clf, X, y, scoring=scoring)
>>> sorted(scores.keys())
['fit_time', 'score_time', 'test_precision_macro', 'test_recall_macro']
>>> scores['test_recall_macro']
array([0.96..., 1. ..., 0.96..., 0.96..., 1. ])
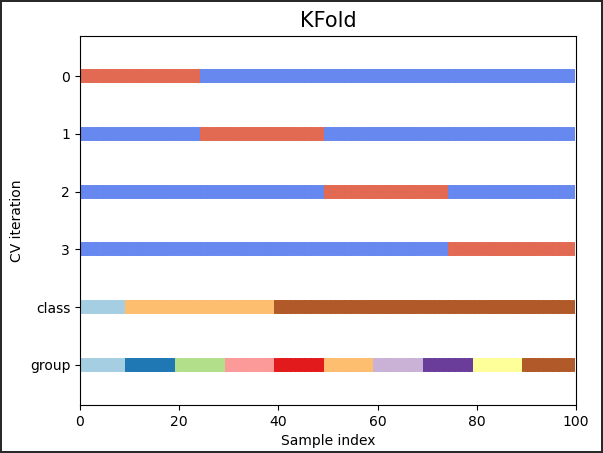
sklern 中,如何进行 K 折交叉验证?
- KFold 将所有样本分成 k 样本组,称为折叠(如果 k=n,这相当于留一出策略),大小相等(如果可能)
1
2
3
4
5
6
7
8>>> import numpy as np
>>> from sklearn.model_selection import KFold
>>> X = ["a", "b", "c", "d"]
>>> kf = KFold(n_splits=2)
>>> for train, test in kf.split(X):
... print("%s %s" % (train, test))
[2 3] [0 1]
[0 1] [2 3]
sklern 中,如何进行 n 次 K 折交叉验证?
- RepeatedKFold 重复 K 折 n 次。它可以在需要运行 KFoldn 次时使用,在每次重复中产生不同的拆分
![]()
1
2
3
4
5
6
7
8
9
10
11>>> import numpy as np
>>> from sklearn.model_selection import RepeatedKFold
>>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
>>> random_state = 12883823
>>> rkf = RepeatedKFold(n_splits=2, n_repeats=2, random_state=random_state)
>>> for train, test in rkf.split(X):
... print("%s %s" % (train, test))
[2 3] [0 1]
[0 1] [2 3]
[0 2] [1 3]
[1 3] [0 2]
sklern 中,如何进行留一个 (LOO) 交叉验证?
- LeaveOneOut(或 LOO)是一个简单的交叉验证。每个学习集都是通过获取除一个之外的所有样本创建的,测试集是被遗漏的样本
1
2
3
4
5
6
7
8
9>>> from sklearn.model_selection import LeaveOneOut
>>> X = [1, 2, 3, 4]
>>> loo = LeaveOneOut()
>>> for train, test in loo.split(X):
... print("%s %s" % (train, test))
[1 2 3] [0]
[0 2 3] [1]
[0 1 3] [2]
[0 1 2] [3]
sklern 中,如何进行留 P 个 (LPO) 交叉验证?
- LeavePOut 非常相似,LeaveOneOut 因为它通过删除创建所有可能的训练 / 测试集 p 来自完整集合的样本
1
2
3
4
5
6
7
8
9
10
11>>> from sklearn.model_selection import LeavePOut
>>> X = np.ones(4)
>>> lpo = LeavePOut(p=2)
>>> for train, test in lpo.split(X):
... print("%s %s" % (train, test))
[2 3] [0 1]
[1 3] [0 2]
[1 2] [0 3]
[0 3] [1 2]
[0 2] [1 3]
[0 1] [2 3]
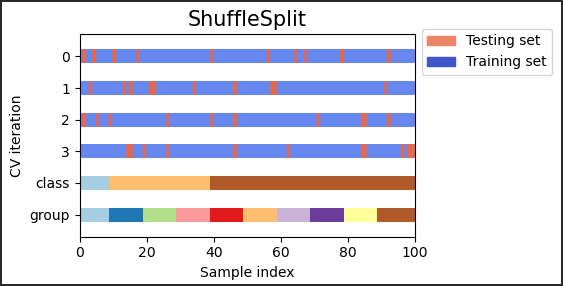
sklern 中,如何进行随机排列交叉验证?
- 迭代器将 ShuffleSplit 生成用户定义数量的独立训练 / 测试数据集拆分。样本首先被打乱,然后分成一对训练集和测试集
![]()
1
2
3
4
5
6
7
8
9
10>>> from sklearn.model_selection import ShuffleSplit
>>> X = np.arange(10)
>>> ss = ShuffleSplit(n_splits=5, test_size=0.25, random_state=0)
>>> for train_index, test_index in ss.split(X):
... print("%s %s" % (train_index, test_index))
[9 1 6 7 3 0 5] [2 8 4]
[2 9 8 0 6 7 4] [3 5 1]
[4 5 1 0 6 9 7] [2 3 8]
[2 7 5 8 0 3 4] [6 1 9]
[4 1 0 6 8 9 3] [5 2 7]
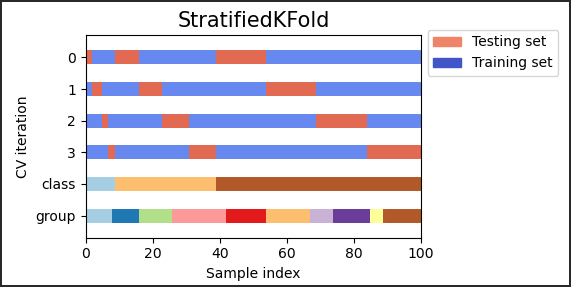
sklern 中,如何进行分层 K-flod 的交叉验证?
- StratifiedKFold 是返回分层折叠的 k-fold 的变体 :每组包含的每个目标类的样本百分比与完整集大致相同
![]()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17>>> from sklearn.model_selection import StratifiedKFold, KFold
>>> import numpy as np
>>> X, y = np.ones((50, 1)), np.hstack(([0] * 45, [1] * 5))
>>> skf = StratifiedKFold(n_splits=3)
>>> for train, test in skf.split(X, y):
... print('train - {} | test - {}'.format(
... np.bincount(y[train]), np.bincount(y[test])))
train - [30 3] | test - [15 2]
train - [30 3] | test - [15 2]
train - [30 4] | test - [15 1]
>>> kf = KFold(n_splits=3)
>>> for train, test in kf.split(X, y):
... print('train - {} | test - {}'.format(
... np.bincount(y[train]), np.bincount(y[test])))
train - [28 5] | test - [17]
train - [28 5] | test - [17]
train - [34] | test - [11 5]
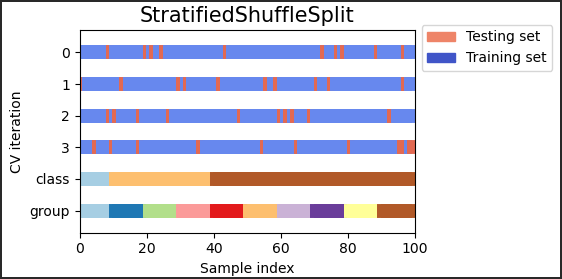
sklern 中,如何进行分层随机的交叉验证?
- StratifiedShuffleSplit 是 ShuffleSplit 的变体,它返回分层拆分,即通过为每个目标类保留与完整集合中相同的百分比来创建拆分
![]()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18>>> import numpy as np
>>> from sklearn.model_selection import StratifiedShuffleSplit
>>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
>>> y = np.array([0, 0, 0, 1, 1, 1])
>>> sss = StratifiedShuffleSplit(n_splits=5, test_size=0.5, random_state=0)
>>> sss.get_n_splits(X, y)
5
>>> print(sss)
StratifiedShuffleSplit(n_splits=5, random_state=0, ...)
>>> for train_index, test_index in sss.split(X, y):
... print("TRAIN:", train_index, "TEST:", test_index)
... X_train, X_test = X[train_index], X[test_index]
... y_train, y_test = y[train_index], y[test_index]
TRAIN: [5 2 3] TEST: [4 1 0]
TRAIN: [5 1 4] TEST: [0 2 3]
TRAIN: [5 0 2] TEST: [4 3 1]
TRAIN: [4 1 0] TEST: [2 3 5]
TRAIN: [0 5 1] TEST: [3 4 2]
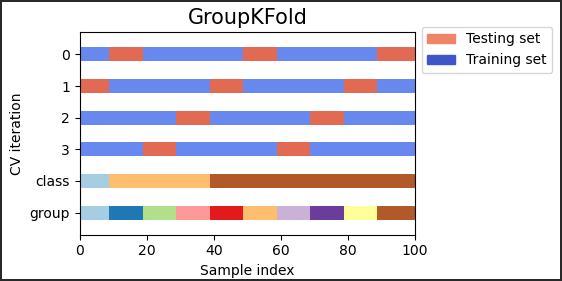
sklern 中,如何进行分组 K 折的交叉验证?
- GroupKFold 是 k-fold 的一种变体,它确保同一组在测试和训练集中都没有出现。例如,如果数据是从每个主题有多个样本的不同主题中获得的,并且如果模型足够灵活,可以从高度个人特定的特征中学习,则它可能无法推广到新主题
![]()
1
2
3
4
5
6
7
8
9
10>>> from sklearn.model_selection import GroupKFold
>>> X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 8.8, 9, 10]
>>> y = ["a", "b", "b", "b", "c", "c", "c", "d", "d", "d"]
>>> groups = [1, 1, 1, 2, 2, 2, 3, 3, 3, 3]
>>> gkf = GroupKFold(n_splits=3)
>>> for train, test in gkf.split(X, y, groups=groups):
... print("%s %s" % (train, test))
[0 1 2 3 4 5] [6 7 8 9]
[0 1 2 6 7 8 9] [3 4 5]
[3 4 5 6 7 8 9] [0 1 2]
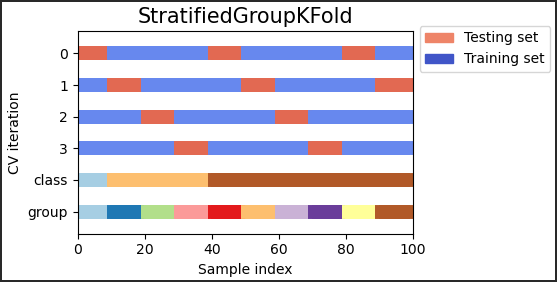
sklern 中,如何进行分层分组 K 折的交叉验证?
- StratifiedGroupKFoldStratifiedKFold 是一种结合了和的交叉验证方案 GroupKFold。这个想法是尝试在每个拆分中保留类的分布,同时将每个组保持在一个拆分中。当您有一个不平衡的数据集时,这可能很有用,因此使用 justGroupKFold 可能会产生倾斜的拆分
![]()
1
2
3
4
5
6
7
8
9
10>>> from sklearn.model_selection import StratifiedGroupKFold
>>> X = list(range(18))
>>> y = [1] * 6 + [0] * 12
>>> groups = [1, 2, 3, 3, 4, 4, 1, 1, 2, 2, 3, 4, 5, 5, 5, 6, 6, 6]
>>> sgkf = StratifiedGroupKFold(n_splits=3)
>>> for train, test in sgkf.split(X, y, groups=groups):
... print("%s %s" % (train, test))
[ 0 2 3 4 5 6 7 10 11 15 16 17] [ 1 8 9 12 13 14]
[ 0 1 4 5 6 7 8 9 11 12 13 14] [ 2 3 10 15 16 17]
[ 1 2 3 8 9 10 12 13 14 15 16 17] [ 0 4 5 6 7 11]
sklern 中,如何进行留一组交叉验证?
- LeaveOneGroupOut 是一种交叉验证方案,它根据第三方提供的整数组数组保留样本。该组信息可用于对任意领域特定的预定义交叉验证折叠进行编码
1
2
3
4
5
6
7
8
9
10>>> from sklearn.model_selection import LeaveOneGroupOut
>>> X = [1, 5, 10, 50, 60, 70, 80]
>>> y = [0, 1, 1, 2, 2, 2, 2]
>>> groups = [1, 1, 2, 2, 3, 3, 3]
>>> logo = LeaveOneGroupOut()
>>> for train, test in logo.split(X, y, groups=groups):
... print("%s %s" % (train, test))
[2 3 4 5 6] [0 1]
[0 1 4 5 6] [2 3]
[0 1 2 3] [4 5 6]
sklern 中,如何进行留 P 组交叉验证?
- LeavePGroupsOut 与 类似 LeaveOneGroupOut,但删除了与 P 每个训练 / 测试集的组
1
2
3
4
5
6
7
8
9
10>>> from sklearn.model_selection import LeavePGroupsOut
>>> X = np.arange(6)
>>> y = [1, 1, 1, 2, 2, 2]
>>> groups = [1, 1, 2, 2, 3, 3]
>>> lpgo = LeavePGroupsOut(n_groups=2)
>>> for train, test in lpgo.split(X, y, groups=groups):
... print("%s %s" % (train, test))
[4 5] [0 1 2 3]
[2 3] [0 1 4 5]
[0 1] [2 3 4 5]
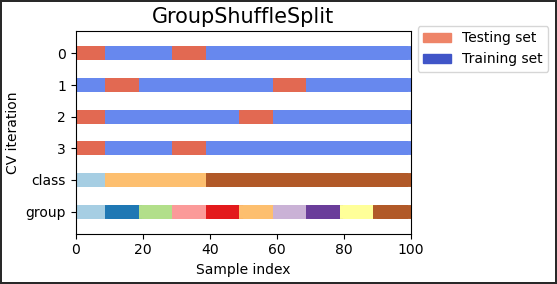
sklern 中,如何进行组随机拆分交叉验证?
- GroupShuffleSplit 迭代器表现为 和 的组合 ,ShuffleSplit 并 LeavePGroupsOut 生成一系列随机分区,其中为每个拆分保留一组组的子集
![]()
1
2
3
4
5
6
7
8
9
10
11
12>>> from sklearn.model_selection import GroupShuffleSplit
>>> X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 0.001]
>>> y = ["a", "b", "b", "b", "c", "c", "c", "a"]
>>> groups = [1, 1, 2, 2, 3, 3, 4, 4]
>>> gss = GroupShuffleSplit(n_splits=4, test_size=0.5, random_state=0)
>>> for train, test in gss.split(X, y, groups=groups):
... print("%s %s" % (train, test))
...
[0 1 2 3] [4 5 6 7]
[2 3 6 7] [0 1 4 5]
[2 3 4 5] [0 1 6 7]
[4 5 6 7] [0 1 2 3]
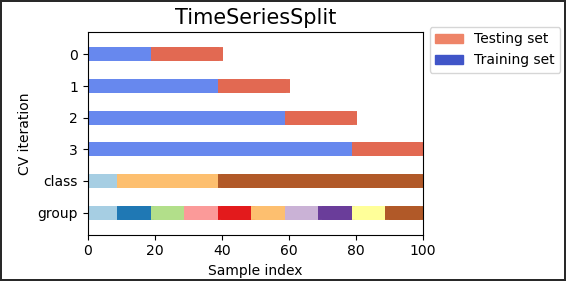
sklern 中,如何进行时间序列数据的交叉验证?
- TimeSeriesSplit 是 k-fold 的一种变体,它首先返回 k 折叠为火车组和 (k+1) 作为测试集折叠。请注意,与标准交叉验证方法不同,连续训练集是之前的训练集的超集。此外,它将所有剩余数据添加到第一个训练分区,该分区始终用于训练模型
![]()
1
2
3
4
5
6
7
8
9
10
11>>> from sklearn.model_selection import TimeSeriesSplit
>>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
>>> y = np.array([1, 2, 3, 4, 5, 6])
>>> tscv = TimeSeriesSplit(n_splits=3)
>>> print(tscv)
TimeSeriesSplit(gap=0, max_train_size=None, n_splits=3, test_size=None)
>>> for train, test in tscv.split(X):
... print("%s %s" % (train, test))
[0 1 2] [3]
[0 1 2 3] [4]
[0 1 2 3 4] [5]
什么是网格参数搜索 (GridSearchCV)?
- GridSearchCV 实例实现了通常的估计器 API:当将其 “拟合” 到数据集上时,会评估所有可能的参数值组合,并保留最佳组合
- 网格搜索优化参数适用于三四个(或更少)的超参数(当超参数的数量增加时,网格搜索的计算复杂度会呈现指数型增长,这时要换用随机搜索)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15>>> from sklearn import svm, datasets
>>> from sklearn.model_selection import GridSearchCV
>>> iris = datasets.load_iris()
>>> parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]}
>>> svc = svm.SVC()
>>> clf = GridSearchCV(svc, parameters)
>>> clf.fit(iris.data, iris.target)
GridSearchCV(estimator=SVC(),
param_grid={'C': [1, 10], 'kernel': ('linear', 'rbf')})
>>> sorted(clf.cv_results_.keys())
['mean_fit_time', 'mean_score_time', 'mean_test_score',...
'param_C', 'param_kernel', 'params',...
'rank_test_score', 'split0_test_score',...
'split2_test_score', ...
'std_fit_time', 'std_score_time', 'std_test_score']
什么是随机参数搜索 (RandomizedSearchCV)?
- 目前最广泛使用的参数优化方法,但其他搜索方法具有更有利的特性。 RandomizedSearchCV 实现对参数的随机搜索,其中每个设置都是从可能的参数值的分布中采样的
- 格搜索优化参数是一种算法参数优化的方法。它是通过遍历已定义参数的列表,来评估算法的参数,从而找到最优参数
1
2
3
4
5
6
7
8
9
10
11
12
13>>> from sklearn.datasets import load_iris
>>> from sklearn.linear_model import LogisticRegression
>>> from sklearn.model_selection import RandomizedSearchCV
>>> from scipy.stats import uniform
>>> iris = load_iris()
>>> logistic = LogisticRegression(solver='saga', tol=1e-2, max_iter=200,
... random_state=0)
>>> distributions = dict(C=uniform(loc=0, scale=4),
... penalty=['l2', 'l1'])
>>> clf = RandomizedSearchCV(logistic, distributions, random_state=0)
>>> search = clf.fit(iris.data, iris.target)
>>> search.best_params_
{'C': 2..., 'penalty': 'l1'}
什么是连续减半的网格参数搜索 (HalvingGridSearchCV)?
- 搜索策略开始用少量的资源评估所有的候选人,然后迭代地选择最佳候选人,使用越来越多的资源
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15>>> from sklearn.datasets import load_iris
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
...
>>> X, y = load_iris(return_X_y=True)
>>> clf = RandomForestClassifier(random_state=0)
...
>>> param_grid = {"max_depth": [3, None],
... "min_samples_split": [5, 10]}
>>> search = HalvingGridSearchCV(clf, param_grid, resource='n_estimators',
... max_resources=10,
... random_state=0).fit(X, y)
>>> search.best_params_
{'max_depth': None, 'min_samples_split': 10, 'n_estimators': 9}
什么是连续减半的随机参数搜索 (HalvingRandomSearchCV)?
- 搜索策略开始用少量的资源评估所有的候选人,然后迭代地选择最佳候选人,使用越来越多的资源
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19>>> from sklearn.datasets import load_iris
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingRandomSearchCV
>>> from scipy.stats import randint
>>> import numpy as np
...
>>> X, y = load_iris(return_X_y=True)
>>> clf = RandomForestClassifier(random_state=0)
>>> np.random.seed(0)
...
>>> param_distributions = {"max_depth": [3, None],
... "min_samples_split": randint(2, 11)}
>>> search = HalvingRandomSearchCV(clf, param_distributions,
... resource='n_estimators',
... max_resources=10,
... random_state=0).fit(X, y)
>>> search.best_params_
{'max_depth': None, 'min_samples_split': 10, 'n_estimators': 9}
网格搜索优化参数、随机搜索优化参数如何选择?
- 如果算法的参数少于三个,推荐使用网格搜索优化参数
- 如果需要优化的参数超过三个,推荐使用随机搜索优化参数