我的图片分类习路线

本文总结自己目前对图片分类的认识,和学习过程
什么是图片分类
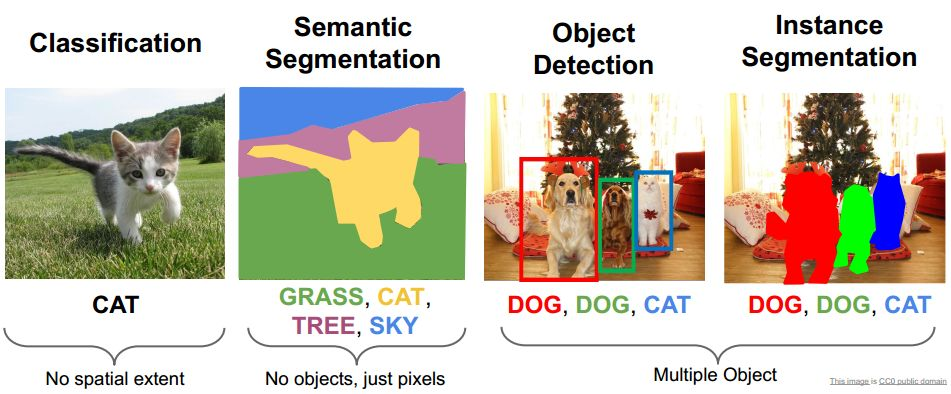
判断图像中包含物体的类别,如果期望判别多种物体则称为多目标分类
图片分类的原理
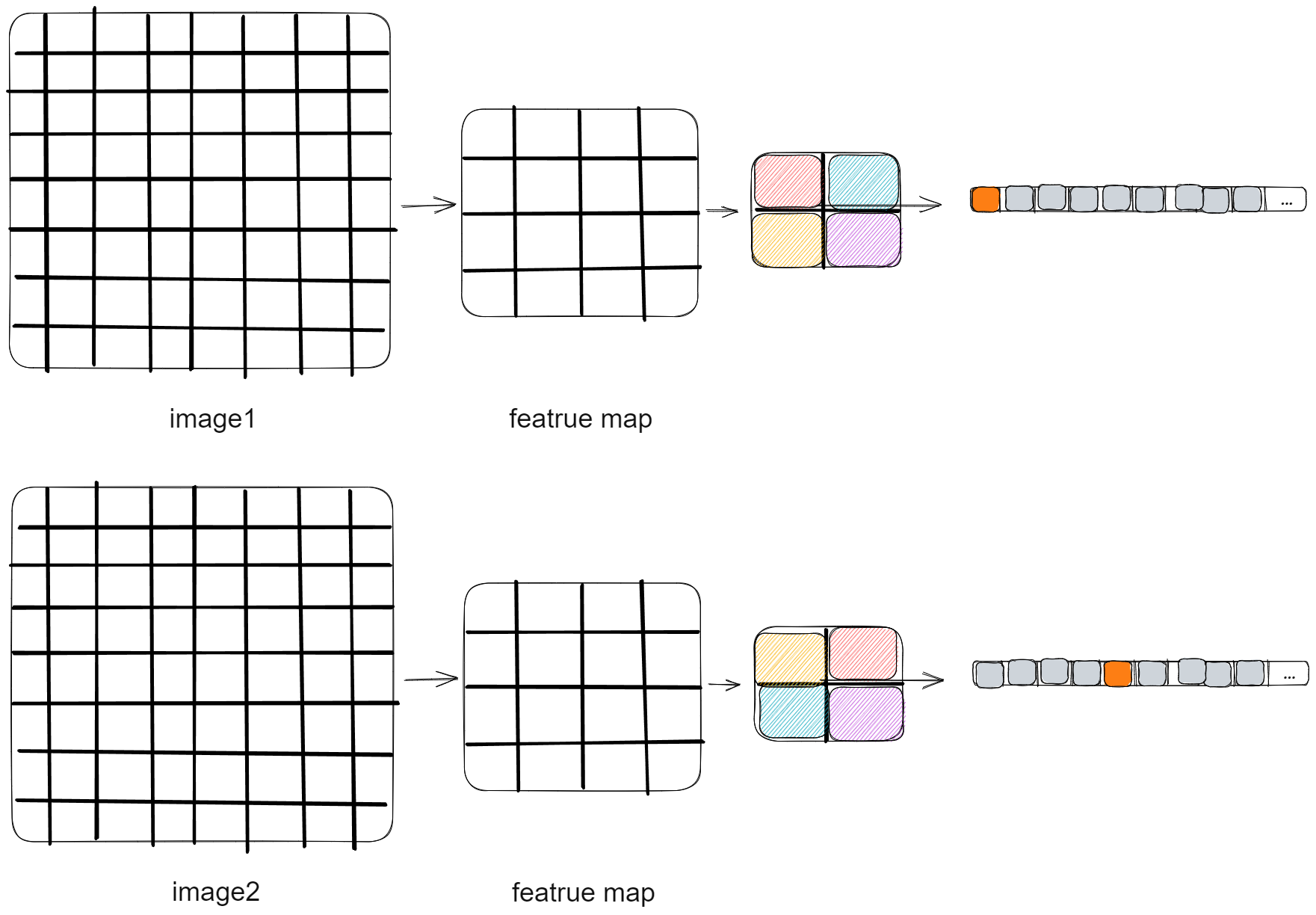
- 输入一张图片,经过 CNN 提取特征后,最后输出这张图在所有类别上的概率
- CNN 提取特征之后通常是 (BCHW) 的输出,因为分类是全局结果,所以需要去掉 HW,通常做法是全局池化,得到 (BC), 然后接 Linear 输出类别打分
CNN 网络设计原则
在 CNN 架构设计上,经常修改哪些指标去提升网络性能?
- 网络的宽度 width:每层卷积的输出通道数
- 网络的深度 depth:网络的层数
- 网络的分辨率 resolution:输入图像的分辨率大小
- 网络的增长率 growth:随着层数的增加,每层卷积输出通道数的增长比例
- 网络的特征复用:如 DenseNet 可以使用更浅的网络,更少的参数,提升特征复用,达到与深度网络相当的性能
- 高效特征融合:InceptionNet 的 split-transforms-merge 模式,将输入分别使用不同的转换分支提取特征,然后将多个分支的结果进行合并实现特征融合
- 上下文依赖:通过类似 SENet 的方式构建像素之间的上下文依赖
图片分类方法
- 基础 CNN:从深度、宽度探索 CNN 的特性
- 残差网络:卷积神经网络半边天,使得深层网络训练成为可能
- 轻量化网络:研究 CNN 部署到移动设备的可能
- 注意力机制:将空间注意力,时间注意力引入到 CNN
评价指标
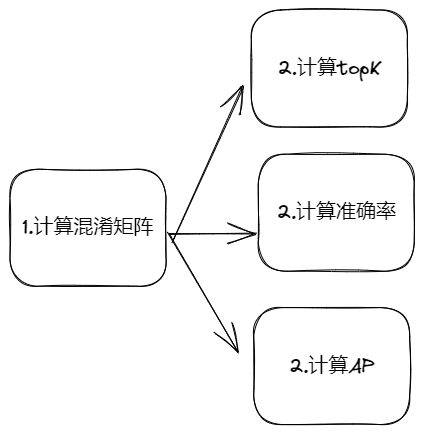
- 分类模型的评价指标,第一步是以图片为单位,以类别为横纵座标计算其结果的混淆矩阵,然后根据混淆矩阵求准确率、AP 值
- 准确率:等于混淆矩阵对角线位置值之和 / 图片数量
- AP 值:每设置一次分类打分阈值,求得一个混淆矩阵,然后计算得到类别的 AP 值,遍历所有阈值,计算得到所有类别 AP 值
学习路线