CBST:Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training
针对语义分割的训练数据和测试数据不匹配问题和类别不平衡问题,该论文提出一个 UDA 和类别平衡方法,使得语义分割更准确
什么是 CBST?
![CBST-20230408142239]()
- CBST 用于解决语义分割的 DA 问题,通过在源域训练的模型处理目标域的数据时,选择置信度最高的伪标签训练网络,再加上空间先验(像素 n 是类别 c 的频率),用于辅助目标域的训练
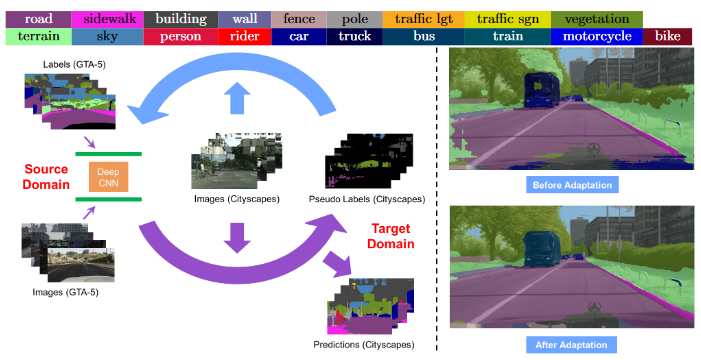
CBST 的自我训练?
- 根据在目标域高置信度的预测交替生成伪标签,然后使用这些伪标签和标注的源域数据微调网络。注意:** 这个框架假设高置信度预测的目标样本有更高的预测准确率
- 同时学习模型参数和未标注数据的伪标签是很困难的,因为很难保证伪标签的正确性。一个更好的策略是采取”easy-to-hard“的策略,即由易到难的步骤学习,这需要用到自步学习。首先生成置信度较高伪标签,希望他们是正确的,然后再考察那些置信度较低的伪标签
![]()
- 交替采用以下训练模式:(1)固定 w,训练 ;(2) 固定 ,训练 w
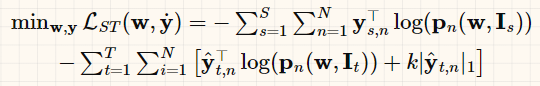
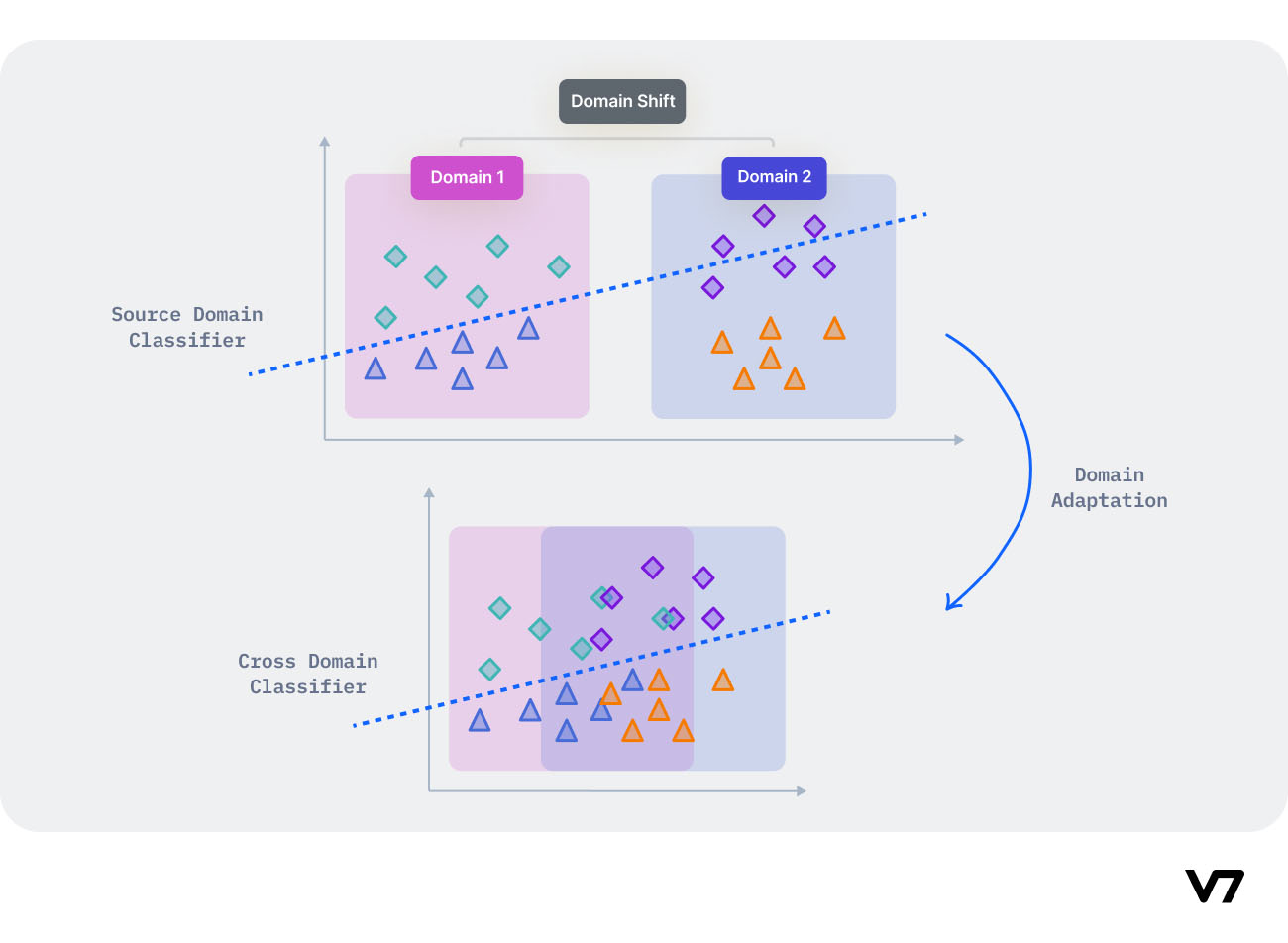
什么是域适应 (domain adaptation, DA)?
![CBST-20230408142240]()
- 迁移学习不一定有效:神经网络需要大量的标记数据进行训练。手动注释它是一项费力的任务。其次,经过训练的深度学习模型只有在与训练数据来自相同的数据分布时才在测试数据上表现良好。由在手机上拍摄的照片创建的数据集与高端数码单反相机的分布明显不同。传统的迁移学习方法失败了
- 重新标注成本高:对于每个新数据集,我们首先需要注释样本,然后重新训练深度学习模型以适应新数据。使用与 ImageNet 数据集一样大的数据集训练一个相当大的深度学习模型,即使一次也需要大量的计算能力(模型训练可能会持续数周),再次训练它们是不可行的
- 域适应是一种尝试解决此问题的方法。使用域自适应,在一个数据集上训练的模型不需要在新数据集上重新训练。相反,可以调整预训练的模型,以在此新数据上提供最佳性能。这节省了大量的计算资源,并且在无监督域适应 (UDA) 等技术中,不需要标记新数据
- 域适应是迁移学习的一种,域适应和微调是迁移学习的两种思路,当源域和目标域都有标签,可以直接微调,只有源域有标签时,使用伪标签微调
参考资料: