BiSeNetv3:Rethinking BiSeNet For Real-time Semantic Segmentation
使用 BiSeNet 中的 context path 提取上下文信息,并且针对 GT 利用 Laplacian Conv 生成网络的中间监督信息,使得中间特征更加符合后续任务
什么是 STDC-Seg ?
![BiSeNetv3-20230408142131]()
- 使用 BiSeNet 中的 context path 提取上下文信息,并且针对 GT 利用 Laplacian Conv 生成网络的中间监督信息,使得中间特征更加符合后续任务

STDC-Seg 的网络结构?
![BiSeNetv3-20230408142131]()
- backbone:使用 BiSeNet 中的 context path 提取上下文信息,使用 STDC 网络作为 backbone,网络中的 Stage3、Stage4 和 Stage5 均对 feature map 进行下采样操作,然后使用 global average pooling 提取全局上下文信息
- ARM:借鉴自 BiSeNet,引入通道注意力,对特征进行重表示
- FFM:借鉴自 BiSeNet,融合不同尺度的特征
- Seg Head:包括 1 个 3 × 3 的卷积、BN 和 ReLU 操作,以及 1×1 卷积,最终输出 N 维度特征,N 为分割类别数
- Detail Head:为了弥补去除 BiSeNet 中的 Spatial 分支造成的细节损失,在 Stage3 后面插入了 Detail Head,使得 Stage3 能够学到细节信息。需要注意的是,Detail Head 只在训练时使用,目的是让 Stage3 输出的 feature map 包含更多的细节特征,用于与 Context 分支的高层次语义特征融合
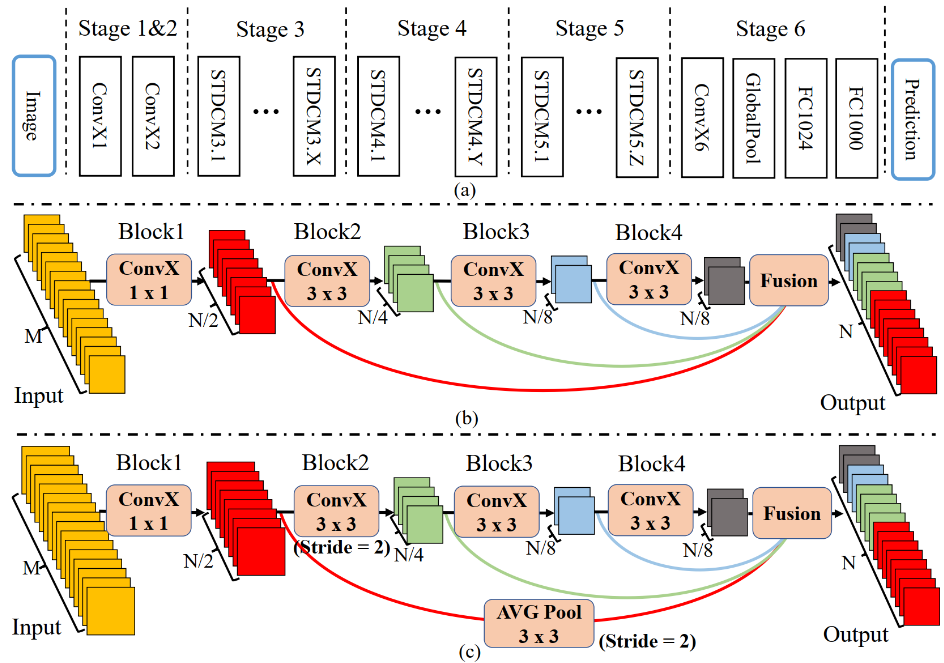
STDC-Seg 的 STDC 模块?
![BiSeNetv3-20230408142157]()
- a 是 STDC 的网络架构,b 在网络中使用短期密集连接模块,c 表示 stride=2 的 STDC 模块,M、N 表示输入输出通道数,ConvX 指 Conv-BN-ReLU
- 与传统的 backbone 不同的是,STDC 模块中深层的特征通道数少,浅层的特征通道数多。STDC 认为,浅层需要更多通道的特征编码细节信息;深层更关注高层次语义信息,过多的特征通道数量会导致信息冗余
STDC-Seg 的 Detail GT 监督的作用?
![BiSeNetv3-20230408142158]()
- 图(a)表示输入图像,图(b)和图(d)分别表示未使用 Detail Guidance 时 Stage3 和网络预测结果,图(c)和图(e)表示使用了 Detail Guidance 时 Stage3 和网络预测结果,图(f)表示 ground truth
- 从图中可以看出,使用了 Detail Guidance 后,Stage3 的 feature map 细节更丰富,分割结果中的细节也更好

STDC-Seg 与 BiSeNet 的差别?
![BiSeNetv3-20230408142159]()
- STDC 分割网络使用 Detail Guidance 替代 BiSeNet 中的 Spatial 分支,在保留细节特征的同时减少了计算量

参考: