贪婪柱搜索 beam_search
Beam Search 是一种受限的宽度优先搜索方法,每个时间步选择 K 个候选预测序列
其原理描述如下:
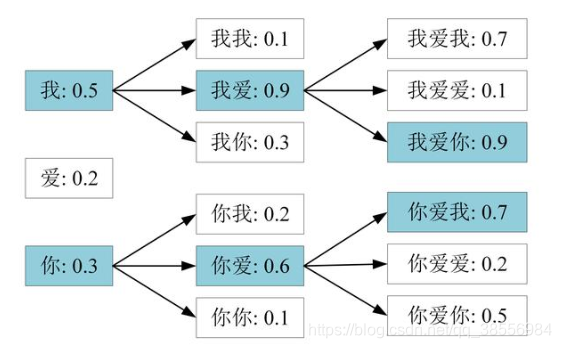
- 假设束宽 K=2,时间步 t 0 预测输出 [我、爱、你] 三个 token,按照概率,选择 [我、你] 两个作为 t 0 的预测,并输入 LLM 预测下一时间步
- 下一时间步输出后,可能链路有 [我我、我爱、我你、你我、你爱、你你],通用选择其联合概率最大的 K 个,本例是 [我爱、你爱]
- 同理,分析下一时间步的预测
Beam Search 倾向输出短序列
因为随着链路的加长,不断乘上小于 1 的概率,整体得分会不断变小,所以:总体上短链路得分高于长链路,为此对 Beam Search 进行基于文本长度的惩罚项来解决这个问题
S 是初始得分,由于 S 是负数,乘上小于 1 的数后,S * 会变大。因此 length_penalty<1,则使得更加倾向短文本,length_penalty>1 则更倾向使用长文本
除此之外,还存在 重复问题、无限生成序列问题