文本类 prompt 编写指南
文本类 prompt 的编写指南
目前 prompt 技巧包含以下种类:
| 种类 | 描述 |
|---|---|
| 直接提示 | 侧重点在于通过特定的指令设计,来提示模型产生更好的输出 |
| 链式提示 | 关注 LLM 的内部逻辑,在这个过程中,一般会将复杂问题进行拆解,分成多个步骤进行推理 |
| 图谱提示 | 和链条提示方式非常相似,都是关注大模型内部结构化的推理过程。但这个过程并不是线性的,而是假定训练过程中隐式地构建了网状或者是图形结构的知识图谱 |
| 生成类提示 | 利用 LLM 内部的知识来迭代补充知识的生成 |
| 集成式提示 | 大语言模型与外部资源进行交互,从而实现复杂任务,提升答案质量 |
直接提示
零样本提示 ZeroShot
可以理解为不给 llm 任何上下文,直接向其发出指令,如以下命令
| 提示 | llm 输出 |
|---|---|
| 将文本分类为中性、负面或正面。 文本:我认为这次假期还可以。 情感: | 中性 |
模型的零样本能力是模型经过预训练后的基础能力,这个和后面 “零样本思维链” 作区分,可以认为:“零样本思维链”= 零样本 +“一步一步地思考”,但是 “零样本思维链” 一般用于解决复杂的,需要多步骤去解决的任务
少样本提示 FewShot
当零样本提示没有作用时,可以向模型提供少量样本,引导模型有更准确的输出
| 提示 | llm 输出 |
|---|---|
| A “whatpu” is a small, furry animal native to Tanzania. An example of a sentence that uses the word whatpu is: We were traveling in Africa and we saw these very cute whatpus. To do a “farduddle” means to jump up and down really fast. An example of a sentence that uses the word farduddle is: | When we won the game, we all started to farduddle in celebration. |
| This is awesome! // Negative This is bad! // Positive Wow that movie was rad! // Positive What a horrible show! // | Negative |
少样本提示可以解决一些上下文明确的提问,对于哪些复杂的、有多步推理的问题,即使提示样本,llm 也可能也无法得到正确答案
| 提示 | llm 输出 |
|---|---|
| The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1. A: The answer is False. The odd numbers in this group add up to an even number: 17, 10, 19, 4, 8, 12, 24. A: The answer is True. The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24. A: The answer is True. The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2. A: The answer is False. The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1. A: | The answer is True. |
此时 llm 输出是错误的,对于这种类型的推理问题,似乎 few-shot prompting 不足以获得可靠的响应。此时需要使用更高级的提示词技术少样本思维链 FewShot-CoT 去解决类似问题
ReAct
无论是样本提示,还是生成更多、更准确的上下文,都涉及人工设计内容或者规则,既然 llm 如此有效,能不能让 llm 代替完成这些工作呢?答案是 ReAct

ReAct 通过重复 “thought->act->Obs”,不断重复这个过程,直到问题能被回答,也就是 llm 不断通过自己上一步的结果,规划自己的下一步。在 “Act” 过程中,llm 通过外部工具,获取最新的、明确的知识,一定程度缓解幻觉问题
方向性刺激
通过一个可调节的 LM 生成 Prompt 的方向性刺激或提示,使得 LLM 回答更加准确,这个可调节的 LM 通过增强训练优化
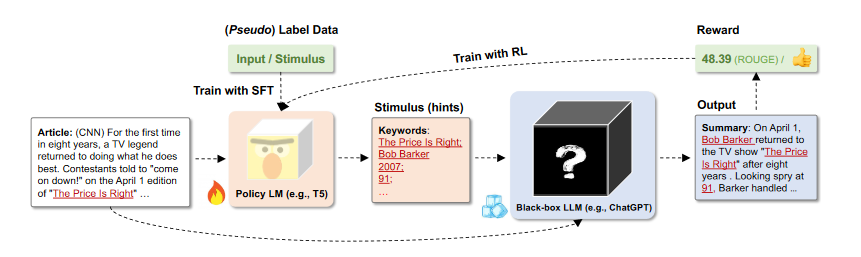
其实就是通过 llm 为 prompt 生成更加准确的上下文

链式提示 ChainofThought
- 什么是 Chain of Mind 提示
思维链提示是一种提示工程方法,它通过鼓励大型语言模型 (LLM) 将其推理分解为一系列中间步骤来增强其推理能力
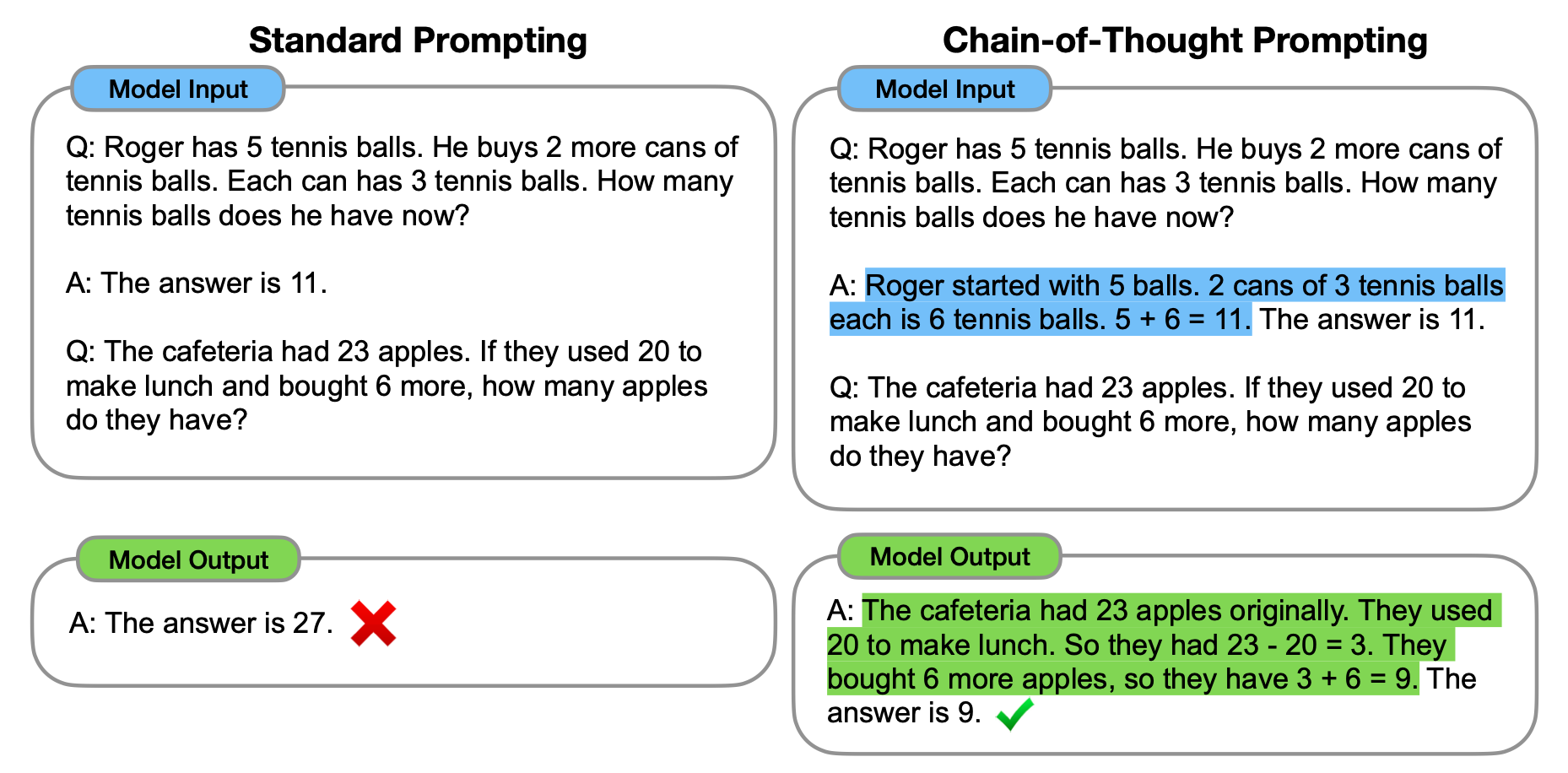
从本质上讲,Chain of Thought prompting 鼓励模型以循序渐进的方式思考问题,这应该模仿人类如何分解复杂问题
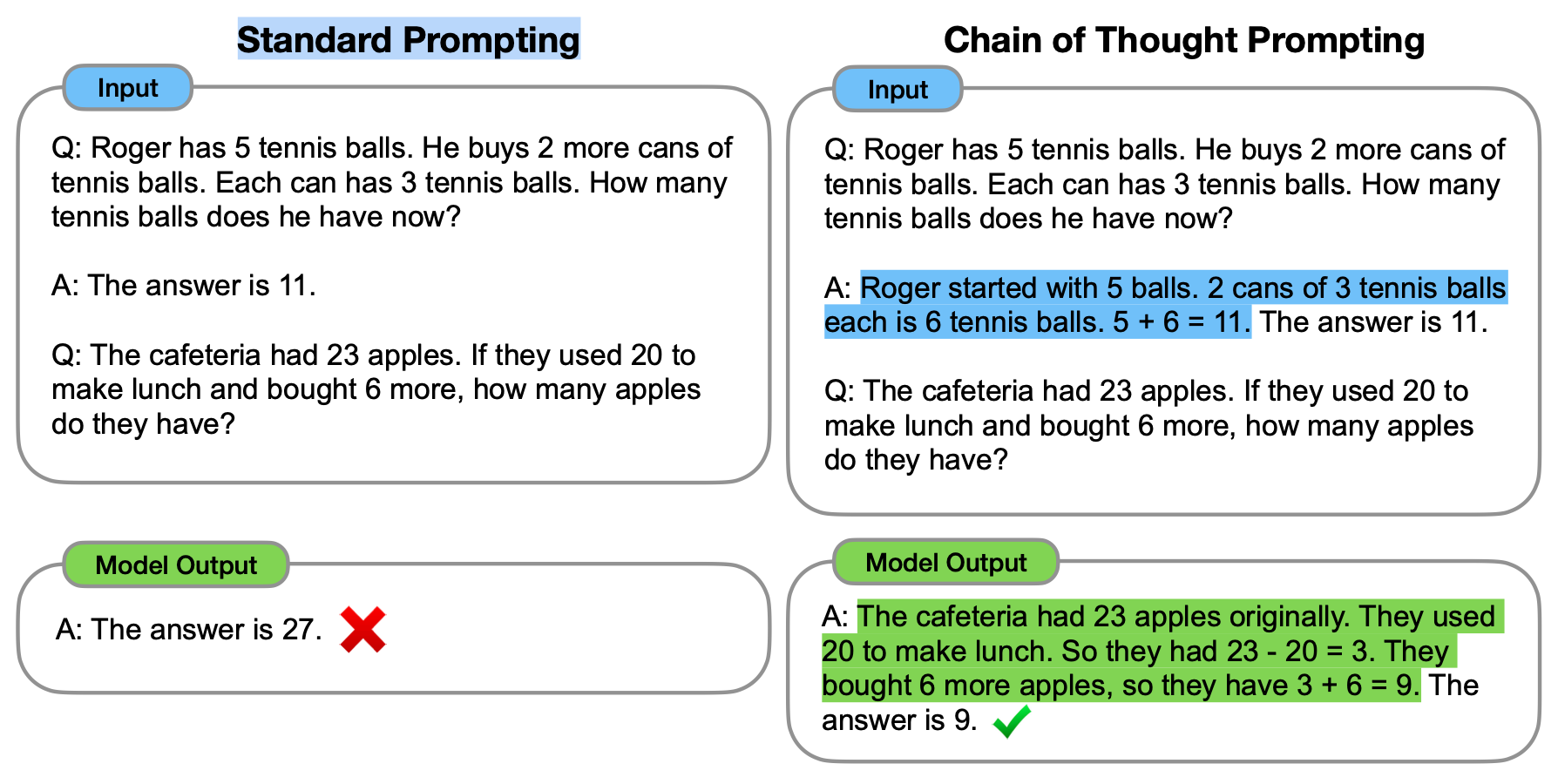
左边是标准的 prompt,右边提供例子的同时,给出得到答案的步骤,最终模型解决了新的问题
为什么 Chain of Thought 提示有帮助
分解复杂的问题: Chain of Thought 提示使 LLM 能够将复杂问题分解为一系列中间步骤。从理论上讲,这种循序渐进的方法允许模型将更多注意力分配给问题的每个部分,从而实现更准确的推理。
模型思维过程一瞥: 通过查看模型执行的推理步骤,用户可以更好地了解模型并调试推理路径是否 / 何时出错。
适用范围广: Chain of Thought 提示已经在大量不同的任务中成功进行了测试。它的用途广泛,可以应用于需要任何类型推理的各种任务。
易于实施: 虽然实施 Chain of Mind 提示的方法有很多种,但也有很多非常简单的方法。
Chain of Thought 提示示例
| prompt | Type |
|---|---|
| Q: A; Let’s think step by step | 零样本思维链 ZeroShot-CoT |
| Let’s work this out in a step-by-step way to be sure we have the right answer." | 零样本思维链 ZeroShot-CoT |
| First, let’s think about this logically. | 零样本思维链 ZeroShot-CoT |
| Given the following problem, generate multiple answers using diverse reasoning paths and aggregate the final answers to come to a final conclusion. Question: | 自洽性 |
| Q: There are 15 trees in the grove. Grove workers will plant trees in the grove today. After they are done, there Will be 21 trees. How many trees did the grove workers plant today? A: There are 15 trees originally. Then there were 21 trees after some more were planted. So there must have Been 21 - 15 = 6. The answer is 6. Q: If there are 3 cars in the parking lot and 2 more cars arrive, how many cars are in the parking lot? A: There are originally 3 cars. 2 more cars arrive. 3 + 2 = 5. The answer is 5. Q: A: | 少样本思维链 FewShot-CoT |
| Here is a question or task: Let’s think step-by-step to answer this: Step 1) Abstract the key concepts and principles relevant to this question: Step 2) Use the abstractions to reason through the question: Final Answer: | Step-Back |
| # Problem: # Instructions ## Tutorial: Identify core concepts or algorithms used to solve the problem ## Relevant problems: Recall three relevant and distinct problems. For each problem, describe it and explain the solution. ## Solve the initial problem: | 自动思维链 (Auto-CoT) |
“Walk me through this context in manageable parts step by step, summarizing and analyzing as we go.” | 思维线索 ThoT |
| Question : James writes a 3-page letter to 2 different friends twice a week. How many pages does he write a year? Explanation: He writes each friend 32=6 pages a week. So he writes 62=12 pages every week. That means he writes 1252=624 pages a year. Wrong Explanation: He writes each friend 1252=624 pages a week. So he writes 32=6 pages every week. That means he writes 62=12 pages a year. Question: James has 30 teeth. His dentist drills 4 of them and caps 7 more teeth than he drills. What percentage of James’ teeth does the dentist fix? | 对比思维链 CCoT |
| Jackson is planting tulips. He can fit 6 red tulips in a row and 8 blue Tulips in a row. If Jackson buys 36 red tulips and 24 blue tulips, how Many rows of flowers will he plant? |step|event|result| | 表格思维链 TabularCot |
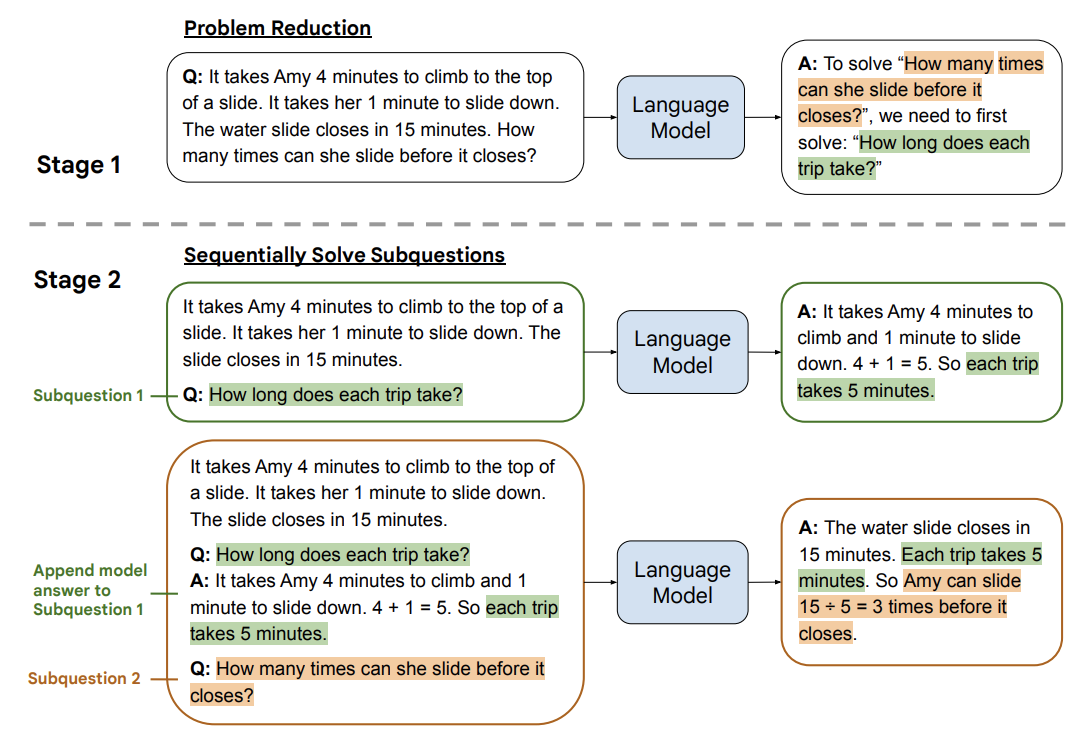
最少到最多提示 LtM
将复杂的问题分解为多个简单的问题地解决,与思维链提示过程类似,需要解决的问题被分解成一组建立在彼此之上的子问题。在第二步中,这些子问题被逐个解决。与思维链不同的是,先前子问题的解决方案被输入到提示中,以尝试解决下一个问题
比如在回答大型文档的问答中,先通过第一个 prompt 提取相关引文,然后使用第二个 prompt 回答问题
| 提示 | llm 输出 |
|---|---|
| 你是一个很有帮助的助手。你的任务是根据文档回答问题。第一步是从文档中提取与问题相关的引文,由 #### 分隔。请使用 #### #### | - Chain-of-thought (CoT) prompting[27] - Generated knowledge prompting[37] - Least-to-most prompting[38] - Self-consistency decoding[39] - Complexity-based prompting[41] - Self-refine[42] - Tree-of-thought prompting[43] - Maieutic prompting[45] - Directional-stimulus prompting[46] - Textual inversion and embeddings[59] - Using gradient descent to search for prompts[61][62][63][64] - Prompt injection[65][66][67] |
| 根据从文档中提取的相关引文(由 #### #### - Chain-of-thought (CoT) prompting[27] - Generated knowledge prompting[37] - Least-to-most prompting[38] - Self-consistency decoding[39] - Complexity-based prompting[41] - Self-refine[42] - Tree-of-thought prompting[43] - Maieutic prompting[45] - Directional-stimulus prompting[46] - Textual inversion and embeddings[59] - Using gradient descent to search for prompts[61][62][63][64] - Prompt injection[65][66][67] | 文档中提到的提示技术包括: 1. Chain-of-thought (CoT) prompting[27] 2. Generated knowledge prompting[37] 3. Least-to-most prompting[38] 4. Self-consistency decoding[39] 5. Complexity-based prompting[41] 6. Self-refine[42] 7. Tree-of-thought prompting[43] 8. Maieutic prompting[45] 9. Directional-stimulus prompting[46] 10. Textual inversion and embeddings[59] 11. Using gradient descent to search for prompts[61][62][63][64] 12. Prompt injection[65][66][67] 每一种技术都采用独特的策略来增强或明确与大型语言模型的互动,以产生期望的结果。 |
不仅仅通过手动设计 “多步骤的 prompt”,还可以使用 llm 自己提出解决问题的 prmot,这有点类似 Agent 的 Plan-and-Execute 技术,首先通过 llm 设计解决问题的子任务,通过一个个回答子任务,回答最终问题
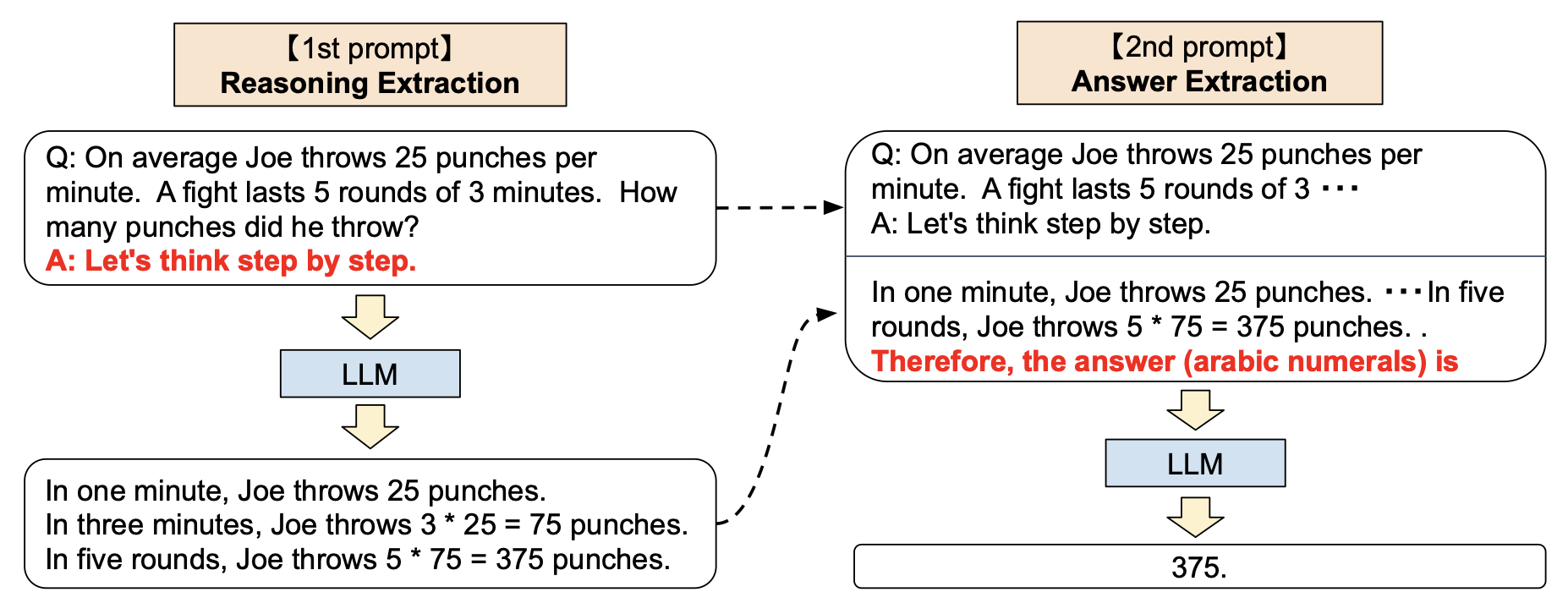
零样本思维链 ZeroShot-CoT
少样本思维链 FewShot-CoT 提供一个类似的问题及解题思路,应该模型去思考,那么不提供例子,而是在 prompt 中添加类似 Let's think step by step,实际上,这也是有效果的
| 提示 | llm 输出 |
|---|---|
| I went to the market and bought 10 apples. I gave 2 apples to the neighbor and 2 to the repairman. I then went and bought 5 more apples and ate 1. How many apples did I remain with? Let’s think step by step. | First, you started with 10 apples. You gave away 2 apples to the neighbor and 2 to the repairman, so you had 6 apples left. Then you bought 5 more apples, so now you had 11 apples. Finally, you ate 1 apple, so you would remain with 10 apples. |
少样本思维链 FewShot-CoT
通过在 prompt 引入推理步骤,结合少样本提示,引导模型解决复杂的推理问题
| 提示 | llm 输出 |
|---|---|
| The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1. A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False. The odd numbers in this group add up to an even number: 17, 10, 19, 4, 8, 12, 24. A: Adding all the odd numbers (17, 19) gives 36. The answer is True. The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24. A: Adding all the odd numbers (11, 13) gives 24. The answer is True. The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2. A: Adding all the odd numbers (17, 9, 13) gives 39. The answer is False. The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1. A: | Adding all the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is False. |
思维树 ToT
对于需要探索及动态决策的复杂任务来说,传统的提示技巧是不够,类比以下:在 Agent 的 Plan-and-Execute 技术中,会提前规划子任务,然后按顺序执行子任务,但是如果某个子任务的答案不理想,会影响后续子任务的回答。
基于此提出了思维树(Tree of Thoughts,ToT)框架,ToT 使 LM 能够做出深思熟虑的决策、考虑多种推理路径并自我评估选择。它还允许 LM 在做出全局决策时进行必要的前瞻性或回溯
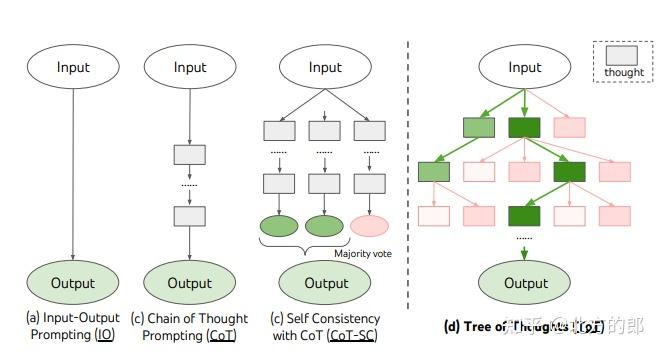
ToT 需要针对不同的任务定义思维 / 步骤的数量以及每步的候选项数量。例如,论文中的 “算 24 游戏” 是一种数学推理任务,需要分成 3 个思维步骤,每一步都需要一个中间方程。而每个步骤保留最优的(best) 5 个候选项
将 ToT 框架的主要概念概括成了一段简短的提示词,指导 LLM 在一次提示中对中间思维做出评估。ToT 提示词的例子如下:
1 | 假设三位不同的专家来回答这个问题。 |
最少到最多提示 LtM
将复杂的问题分解为多个简单的问题地解决,与思维链提示过程类似,需要解决的问题被分解成一组建立在彼此之上的子问题。在第二步中,这些子问题被逐个解决。与思维链不同的是,先前子问题的解决方案被输入到提示中,以尝试解决下一个问题
比如在回答大型文档的问答中,先通过第一个 prompt 提取相关引文,然后使用第二个 prompt 回答问题
| 提示 | llm 输出 |
|---|---|
| 你是一个很有帮助的助手。你的任务是根据文档回答问题。第一步是从文档中提取与问题相关的引文,由 #### 分隔。请使用 #### #### | - Chain-of-thought (CoT) prompting[27] - Generated knowledge prompting[37] - Least-to-most prompting[38] - Self-consistency decoding[39] - Complexity-based prompting[41] - Self-refine[42] - Tree-of-thought prompting[43] - Maieutic prompting[45] - Directional-stimulus prompting[46] - Textual inversion and embeddings[59] - Using gradient descent to search for prompts[61][62][63][64] - Prompt injection[65][66][67] |
| 根据从文档中提取的相关引文(由 #### #### - Chain-of-thought (CoT) prompting[27] - Generated knowledge prompting[37] - Least-to-most prompting[38] - Self-consistency decoding[39] - Complexity-based prompting[41] - Self-refine[42] - Tree-of-thought prompting[43] - Maieutic prompting[45] - Directional-stimulus prompting[46] - Textual inversion and embeddings[59] - Using gradient descent to search for prompts[61][62][63][64] - Prompt injection[65][66][67] | 文档中提到的提示技术包括: 1. Chain-of-thought (CoT) prompting[27] 2. Generated knowledge prompting[37] 3. Least-to-most prompting[38] 4. Self-consistency decoding[39] 5. Complexity-based prompting[41] 6. Self-refine[42] 7. Tree-of-thought prompting[43] 8. Maieutic prompting[45] 9. Directional-stimulus prompting[46] 10. Textual inversion and embeddings[59] 11. Using gradient descent to search for prompts[61][62][63][64] 12. Prompt injection[65][66][67] 每一种技术都采用独特的策略来增强或明确与大型语言模型的互动,以产生期望的结果。 |
不仅仅通过手动设计 “多步骤的 prompt”,还可以使用 llm 自己提出解决问题的 prmot,这有点类似 Agent 的 Plan-and-Execute 技术,首先通过 llm 设计解决问题的子任务,通过一个个回答子任务,回答最终问题
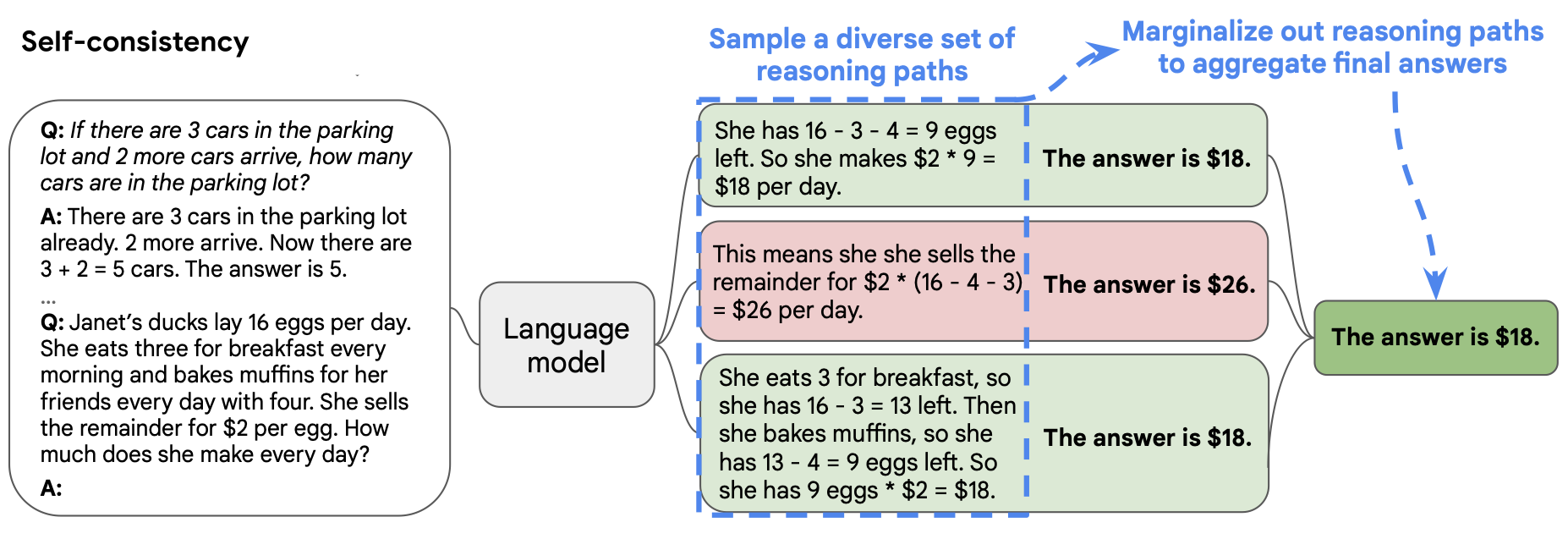
自洽性
用思维链提示中的自洽解码替代简单的贪婪解码,即通过少样本思维链(CoT)提示采样多个、多样化的推理路径,并使用生成的结果来选择最一致的答案
反射 Reflexion
比 ReAct 更进一步的框架,通过更加复杂的 “自我反省” 规划模型下一步 prompt,如下图所示,如果将 “Evalustor->Self-reflection->Experience” 替换为普通 llm,也就是 ReAct 了
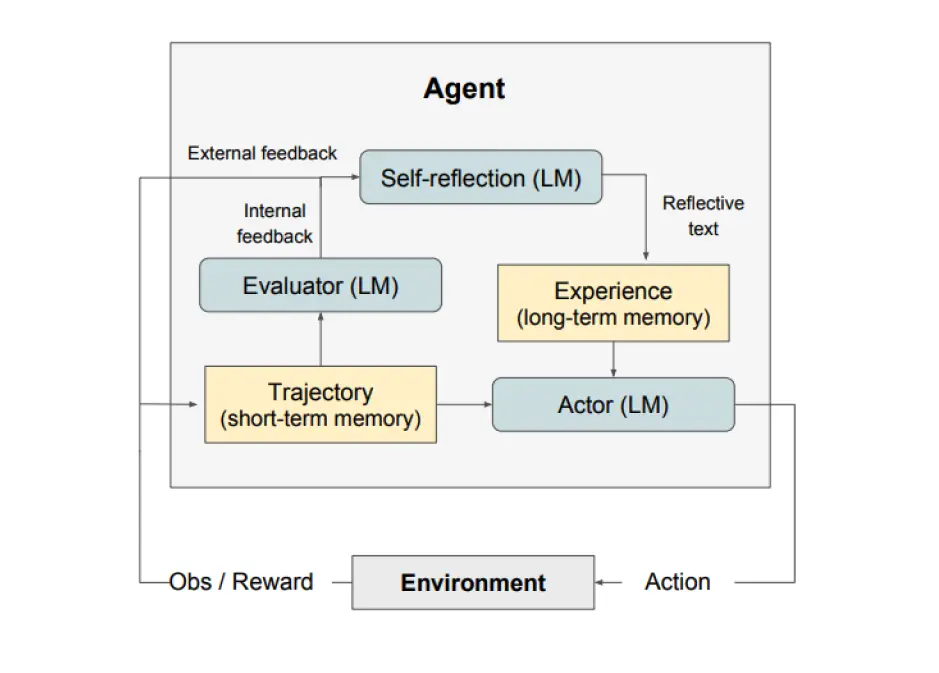
Reflexion 过程的关键步骤是:a) 定义任务,b) 生成轨迹,c) 评估,d) 执行反射, e) 生成下一个轨迹

Reflexion 最适合以下情况:
- 代理需要从反复试验中学习:Reflexion 旨在通过反思过去的错误并将这些知识纳入未来的决策来帮助代理提高绩效。这使得它非常适合代理需要通过反复试验来学习的任务,例如决策、推理和编程。
- 传统的强化学习方法不切实际:传统的强化学习 (RL) 方法通常需要大量的训练数据和昂贵的模型微调。Reflexion 提供了一种轻量级的替代方案,不需要微调底层语言模型,使其在数据和计算资源方面更加高效。
- 需要细致入微的反馈:Reflexion 利用口头反馈,这可能比传统 RL 中使用的标量奖励更细致、更具体。这使代理能够更好地了解其错误,并在后续试验中做出更有针对性的改进。
- 可解释性和显式记忆很重要:与传统的 RL 方法相比,Reflexion 提供了一种更具可解释性和明确的情景记忆形式。代理的自我反思存储在其内存中,从而可以更轻松地分析和理解其学习过程。
Reflexion 的一些限制:
- 依赖自我评估能力:Reflexion 依赖于代理准确评估其性能并生成有用的自我反思的能力。这可能具有挑战性,尤其是对于复杂的任务,但随着模型功能的不断改进,预计 Reflexion 会随着时间的推移而变得更好。
- 长期内存约束:Reflexion 使用具有最大容量的滑动窗口,但对于更复杂的任务,使用高级结构(如向量嵌入或 SQL 数据库)可能是有利的。
- 代码生成限制:测试驱动开发在指定准确的输入 - 输出映射(例如,非确定性生成器函数和受硬件影响的函数输出)方面存在限制。
主动提示 ActivePrompt
Active Prompting(或 Active-Prompt)) 是一种通过选择性地对模型显示不确定性最大的示例进行人工注释来改进少样本思维链 FewShot-CoT 提示性能的技术。这种方法通过只关注模型最具挑战性的问题,帮助最大限度地提高人工注释工作的效率。
其实就是使用这个技术筛选 CoT 数据集中,推理步骤效果低下的数据,然后将这些样本挑选出来,通过人工重新修改,提示 CoT 数据集的数据质量,减少对所有训练数据进行注释的需要来节省大量人力资源
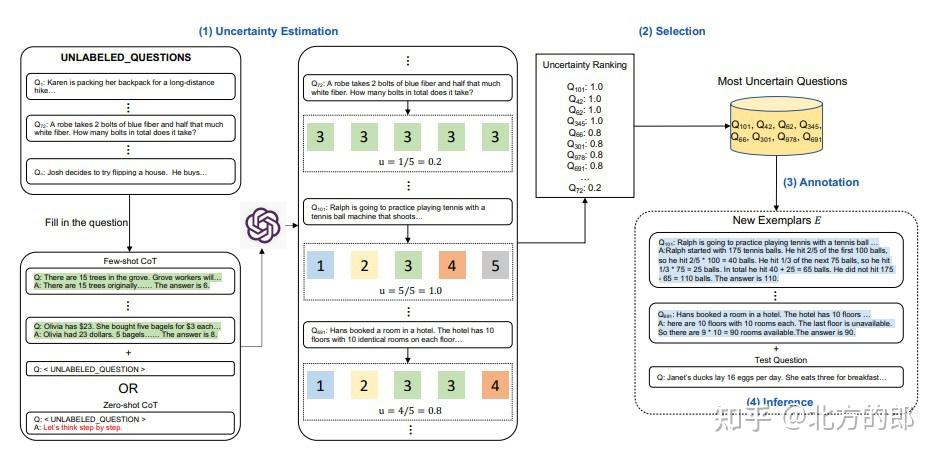
第一步是使用或不使用少量 CoT 示例查询 LLM。对一组训练问题生成 k 个可能的答案。基于 k 个答案计算不确定度度量。选择最不确定的问题由人类进行注释。然后使用新的注释范例来推断每个问题
思维线索 ThoT
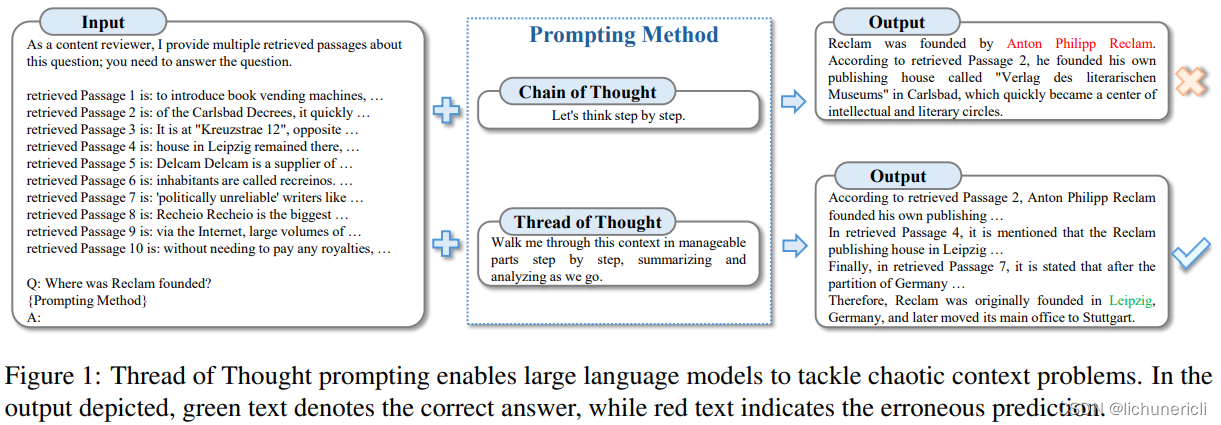
这个方法主要是通过特定 promp 多次使用 llm 提炼,解决混乱上下文导致输出鲜果不佳的问题
自我询问提示 Self-Ask

Self-Ask 通过将复杂的问题分解为子问题并逐步回答它们来改进 LLM 推理,与思维链 (CoT) 提示类似,Self-Ask 将问题分解为一个循序渐进的过程。但是,与 CoT 不同的是,Self-Ask 会提示模型在回答提示中的主要问题之前明确说明下一个后续问题
使用的 prompt
1 | Question: {A complex question} |
自动思维链 (Auto-CoT)
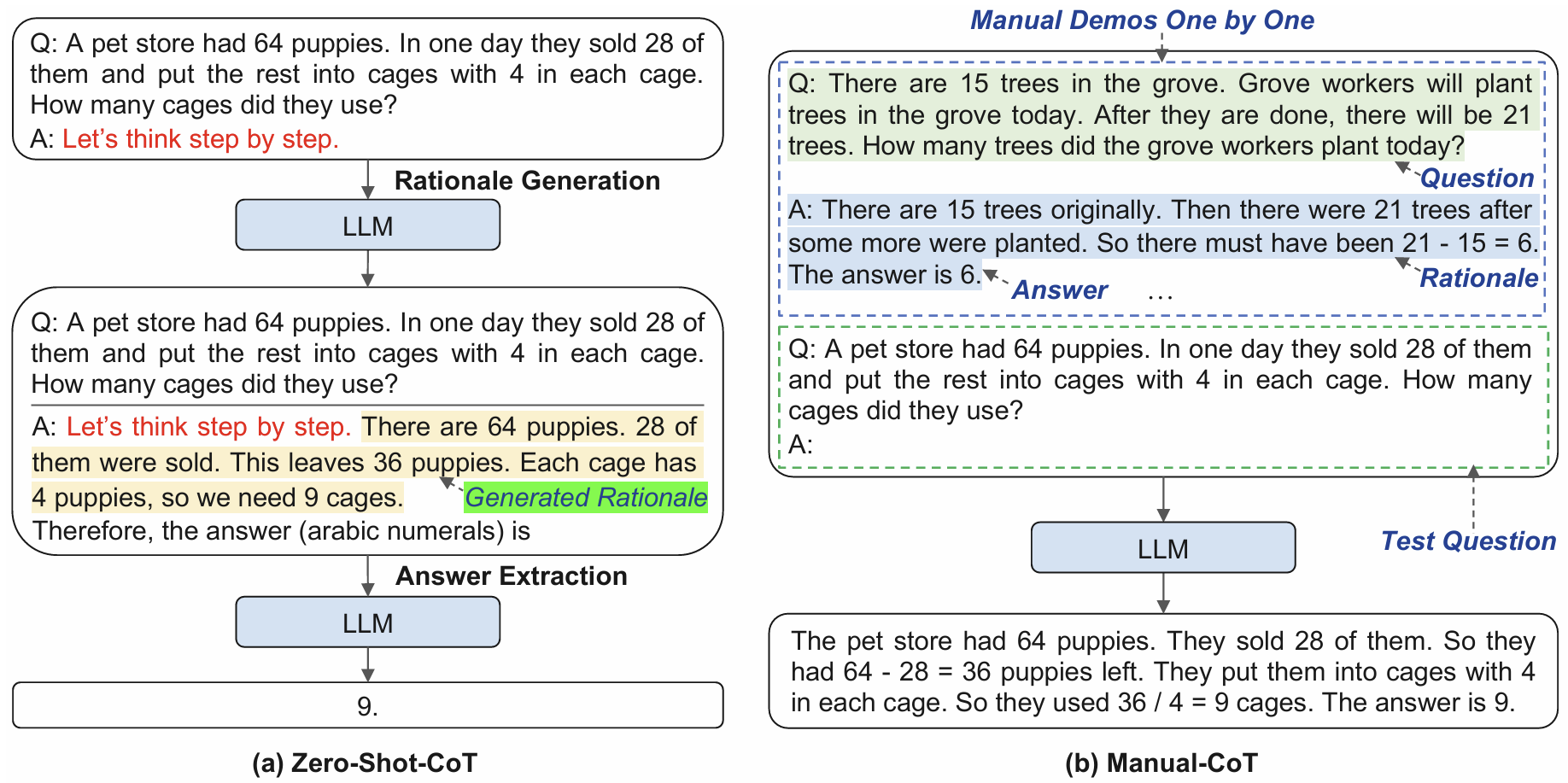
上图是使用零样本思维链、少样本思维链的过程,这两个过程中,零样本思维链不一定能提出正确的推理步骤,少样本思维链依赖手工设计水平,于是提出 Auto-CoT 摆脱这两种方法的缺陷

Auto-Cot 分为 3 步:
- 对问题聚类:对数据集中的问题聚类,聚类的目的是类似的问题,有类似的推理步骤
- 使用 “零样本思维链” 回答每个聚类问题:将回答获取的推理步骤,作为这类问题的标准推理步骤
- 使用 “少样本思维链” 回答用户问题:回答问题时,将类似问题的推理步骤到 prompt 中
总结:Auto-Cot 主要是优化推理步骤,是的步骤更符合用户的问题
对比思维链 CCoT
在少样本思维链 FewShot-CoT 的基础上新增负面样例,增强大模型回答能力
1 | Question : James writes a 3-page letter to 2 different friends twice a week. How many pages does he write a year? |
表格思维链 TabularCot
表格思维链提示类似于 Thread-of-Thought 提示,因为它使用不同的格式进行推理步骤。具体来说,它采用零镜头 Chain of Thought 提示,指示模型以结构化格式提供其推理,通常使用 Markdown 表格
1 | Jackson is planting tulips. He can fit 6 red tulips in a row and 8 blue |
图谱提示
生成类提示 (Generate)
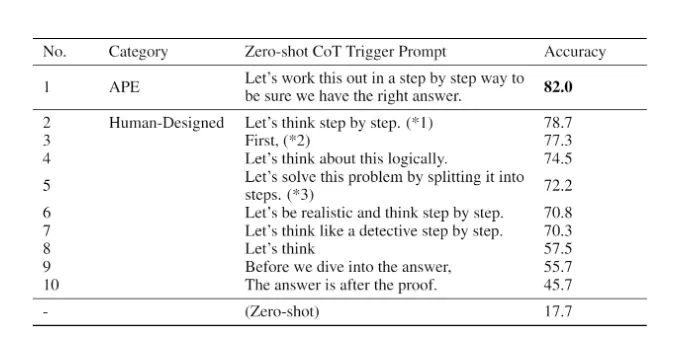
自动提示工程师 APE
自动提示工程师 (APE),这是一个用于自动指令生成和选择的框架。通过 3 个 llm 扮演答案生成的:产出、打分、裁判
设计不同的问题,然后将不同的类似 Let's think step by step 添加到 prompt 中,然后使用 llm 评估添加不同这些 prompt 的回答问题的打分,选择打分高的添加内容
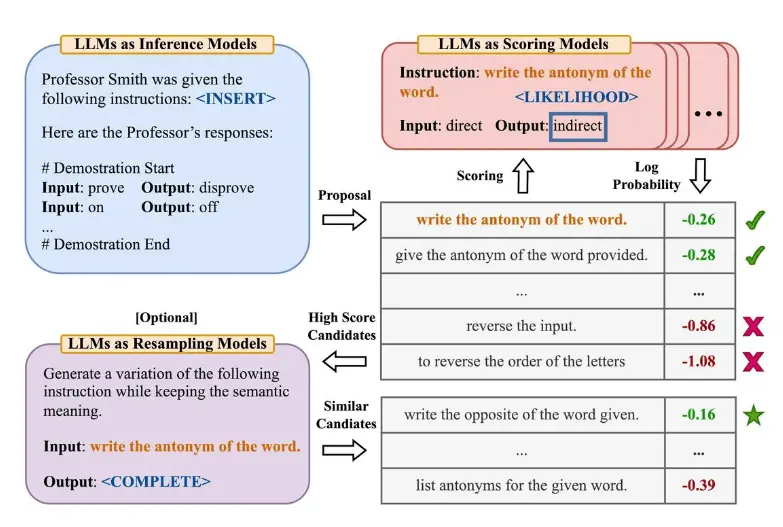
比如 APE 发现 Let's work this out in a step by step way to be sure we have the right answer. 比 Let's think step by step 有更好的答案
生成知识提示
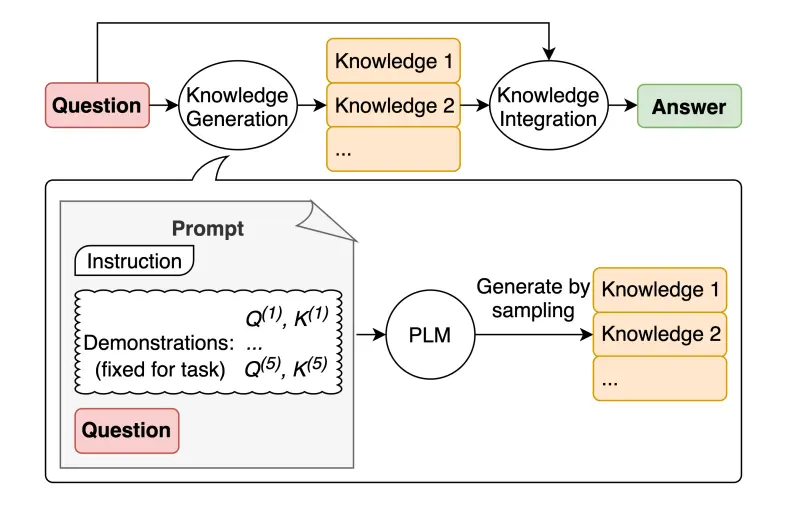
生成知识通过 llm 补充 prompt 上下文不足的问题,让 llm 有更充足的信息回答问题,涉及两个过程
- 知识生成 (Knowledge Generation):基于问题,通过 llm 生成不同相关的知识
- 知识集成 (Knowledge Integration):将问题和知识进行组合,生成新的 prompt, 给 llm 回答
| prompt | llm 输出 |
|---|---|
| 问题:高尔夫球的一部分是试图获得比其他人更高的得分。是或否? 知识:高尔夫球的目标是以最少的杆数打完一组洞。一轮高尔夫球比赛通常包括 18 个洞。每个洞在标准高尔夫球场上一轮只打一次。每个杆计为一分,总杆数用于确定比赛的获胜者。 解释和答案: | 不是,高尔夫球的目标不是获得比其他人更高的得分。相反,目标是以最少的杆数打完一组洞。总杆数用于确定比赛的获胜者,而不是总得分。 |
| 问题:高尔夫球的一部分是试图获得比其他人更高的得分。是或否? 知识:高尔夫球是一项精密的球杆运动,竞争选手(或高尔夫球手)使用许多类型的球杆,用最少的杆数将球打入球场上一系列洞中。目标是以最低的分数完成比赛,该分数是通过将每个洞上所用的杆数相加计算出来的。得分最低的选手赢得比赛。 解释和答案: | 是的,高尔夫球的一部分是试图获得比其他人更高的得分。每个选手都试图以最少的杆数打完一组洞。总杆数用于确定比赛的获胜者,而不是总得分。得分最低的选手赢得比赛。 |
| 以上第一个例子,回答准确,第二个例子回答错误,所以说这个技术依赖于结合的知识 |
集成式提示
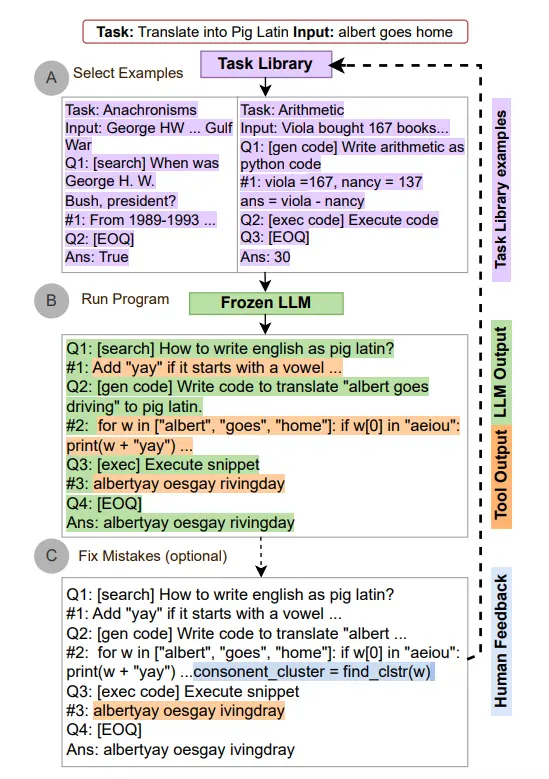
自动推理并使用工具 ART
ART(Automatic Reasoning and Tool-use)在回答问题时,交替使用 Cot 提示和工具,也就是说回答问题时,不仅 llm 参与,工具也会进行计算,这很接近 Agent 的原理
ART 的工作原理
- 接到一个新任务的时候,从任务库中选择多步推理和使用工具的示范。
- 在测试中,调用外部工具时,先暂停生成,将工具输出整合后继续接着生成
其他
元提示 MetaPrompt
无论是样本,还是思维链,都是在内容上引导模型回答更加准确,而元提示 (MetaPrompt) 则侧重于任务和问题的结构和语法方面,怎么说呢?以下是例子

在 prompt 中,并没有直接提供样本,而是强调解题的框架,这是一种比样本更加抽象的提示。与样本提示相比,它有以下优势
- Token 优势:更抽象的概括,意味使用更少的 token,花费更低
- 自适应不同问题:减少设计样本的影响,可以自适应不同的提问
MetaPrompt 的设计规则:
1. 以结构为导向:优先考虑问题和解决方案的格式和模式,而不是具体的内容
2. 以语法为中心:使用语法作为预期响应或解决方案的指导模板
3. 抽象示例:使用抽象示例作为框架,说明问题和解决方案的结构,而不关注具体细节
4. 多才多艺:适用于各个领域,能够为各种问题提供结构化的响应
5. 分类方法:借鉴类型论,强调提示中组件的分类和逻辑排列